Kafka(二) —— Server端设计原理
整理架构
消息设计
/**
* 消息类
*
* @author Michael Fang
* @since 2019-11-14
*/
public class Message implements Serializable{
// 2字节
private short magic;
// 2字节
private short codecKlassOrdinal;
// 1字节
private boolean codecEnabled;
// 4字节
private CRC32 crc;
// 4字节
private String key;
// 4字节
private String value;
}
(1)一个普通的Kafka消息对象有多大
这个Message对象被创建好实际的大小是多少?
JMM要求Java对象必须按照8Byte对齐,未对齐的部分会填充空白字节进行补齐。
外加64位JVM对象头通常由两个8Byte的word组成。
所以如果是64位JVM,则对象大小 = 16byte(对象头=存放Class指针的空间大小8字节 + MarkWord8字节) + 2 + 2 + 1 + 4 + 4 + 4 +7(补充字节) = 40byte,
如果是32位JVM,则对象大小 = 8byte(对象头=存放Class指针的空间大小4字节 + MarkWord4字节) + 2 + 2 + 1 + 4 + 4 + 4 + 7(补充字节)= 32byte。
一个普通的Kafka消息对象就要40KB的内存空间,显然是比较大的,其中7个字节被浪费掉。
集群管理
kafka依赖Zk,每个broker启动都会在zk中注册一个节点。

从图中的ephemeralOwner字段值可以看出,这是个临时节点。 图中的值表示节点绑定的session-id。如果值为0,则表示不是临时节点。
Zk的路径:
- /broker:保存Kafka集群的所有信息
- /controller:保存Kafka controller组件的注册信息
- /admin:
- /isr_change_notification
- /cofig
- /cluster
- /controller_epoch
副本与ISR
(1)何为ISR,为什么要有ISR?
ISR是Kafka集群维护的一组同步副本集合(in-sync replicas)。
leader副本对外服务,follower副本向leader副本请求数据,保持与leader副本的同步。
如果leader副本挂掉,从其他follower副本中中选择出一个数据同步进步落后太多的follwer作为leader,会导致数据丢失的问题。
所以引入ISR的概念。
(2)follower副本同步与HW、LEO
HW:高水印值,意思是consumer能够获取的消息上限offset,超过HW的消息,视为“未提交成功”。
LEO:副本日志中下一条写入消息的offset。每个副本都需要维护自己的LEO信息。
在ack = -1的语义下,
当leader接收一条消息后,会把LEO值往后挪动1位,假设为1。
当其他follower都接收到这条消息后,都将LEO值往后挪动1位。
leader接收到follower的响应后,更新HW值为1,则位移为0的消息可以被consumer消费。
(3)如何界定ISR?
0.9版本之前是,replica.lag.max.messages、replica.lag.time.max.ms,意思是当follower落后多少条信息或在多少毫秒内无法向leader请求数据,就会被踢出ISR。
0.9版本以后,只保留replica.lag.time.max.ms。
follower与leader不同步的原因:
- 请求速度跟不上
- 进程卡住
- 新创建副本:新follower副本,需要从头开始追赶。
0.9版本之前的设计,有个问题是,replica.lag.max.messages参数不好设定,容易导致某follower频繁被踢出、加入ISR,导致很大的性能开销。
日志存储设计
文件目录布局
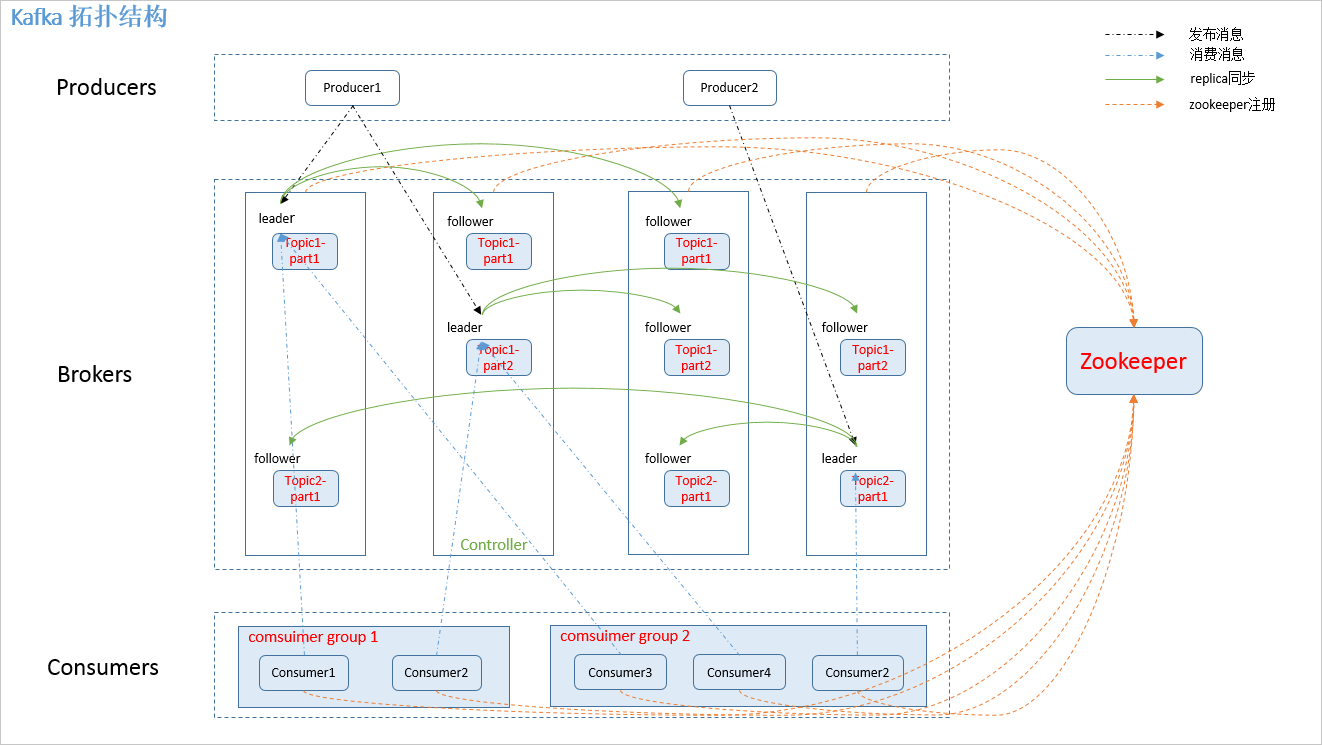
当创建topic的时候,kafka会为每个分区创建对应的文件夹,格式是<topic>-<分区号>。例如创建分区为4,名称为test-partition-1的topic。

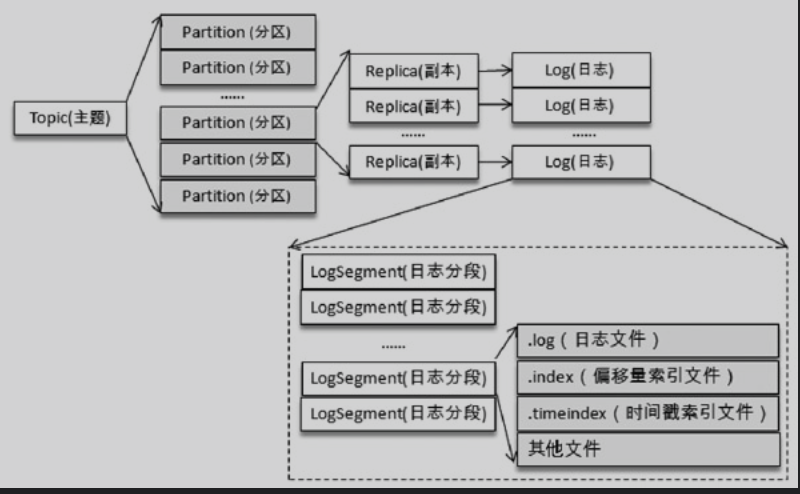
向Log中追加消息是顺序写入的,只有最后一个LogSegment才能执行写入,最后一个LogSegment也叫activeSegment。当activeSegment满足一定条件时,需要创建一个新的activeSegment。
日志索引
使用索引的目的是提高查找消息的效率。
每个LogSegment都对应两个索引文件,.index偏移量索引文件、.timeindex时间戳索引文件。
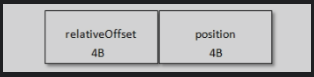
偏移量索引的格式:
- relativeOffset:相对偏移量。占用4byte。
- postition:物理地址,消息在日志分段分拣中对应的物理位置。占用4byte。
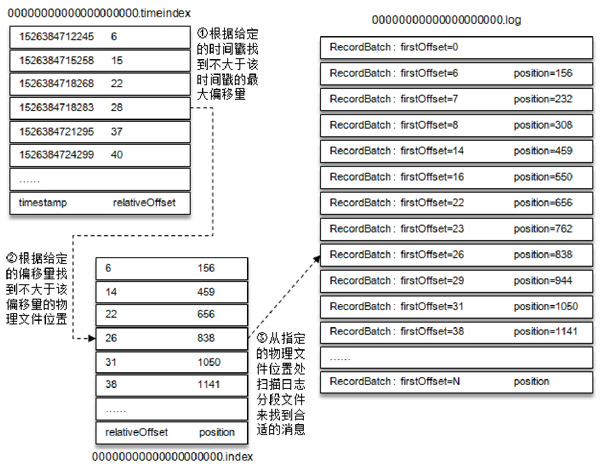
使用二分法实现消息的快速查找,例如要获得offset为35的消息,则找到小于offset=35的最大索引项,该索引项为[31,1050],然后从1050byte处顺序搜索记录,直到找到offset=35的消息记录。

时间戳索引的格式:

查找timeStamp = 1526384718288的消息,消息查找过程如下:
磁盘存储
Kafka依赖文件系统(磁盘)来存储和缓存消息。磁盘在介质存储速度层级中处于尴尬的位置,那Kafka是如何提供有竞争力的性能呢?
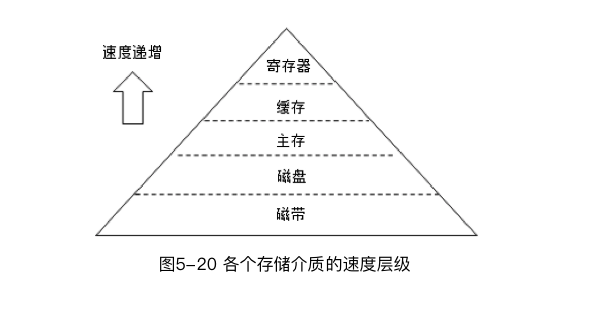
(1)文件追加
顺序写盘的速度,比随机写盘的速度快,也比随机写内存的速度快。
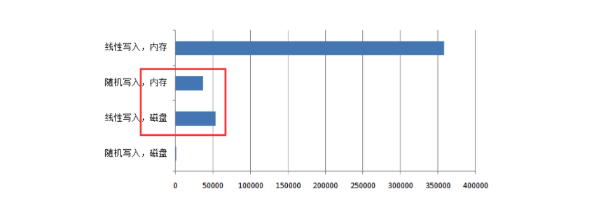
Kafka采用文件追加的方式写入消息,即只在文件的尾部追加新的消息,并且不允许修改已写入的消息。
(2)页缓存(PageCache)
页缓存是操作系统实现的一种重要的磁盘缓存,以此用来减少对磁盘I/O的操作。
页缓存,就是将磁盘中的数据缓存到内存中,将对磁盘的访问变为内存的访问。
读取流程:
当一个进程准备读取磁盘中的文件内容时,操作系统会先判断读取的数据所在的页,是否存在页缓存中,存在则返回数据。不存在,则操作系统向磁盘发送读取请求,并将读取的数据存入页缓存中,再将数据返回给进程。
写入流程:
当进程准备将数据写入磁盘,操作系统会判断数据是否在页缓存中,不存在,则给页缓存增加相应的页,最后将数据写入对应的页。操作系统会在合适的时间,将缓存页中的数据写入磁盘,保证数据一致性。
kafka大量使用页缓存,这是Kafka实现高吞吐的重要原因之一。消息都是先被写入页缓存,然后OS负责具体的刷盘任务。
(3)零拷贝(Zero Copy)
零拷贝:将数据直接从磁盘文件复制到网卡设备中,而不需要经由应用程序之手。
对Linux系统而言,零拷贝技术依赖底层的sendfile()方法实现。对Java而言,FileChannal.transferTo()的底层实现就是sendfile()。
不使用非零拷贝技术的流程:
当需要将一个文件展示给用户时,需要将文件从磁盘中复制到内存buf中,然后将buf通过Socket传输给用户。
在这个过程中文件经历了4次复制过程:
- 调用read(),文件内容复制到内核模式的Read Buffer中
- CPU控制将内核模式的数据复制到用户模式下
- 调用write(),将用户模式下的内容复制到内核模式下的Socket Buffer中
- 将内核模式下的Socket Buffer的数据复制到网卡设备中传送
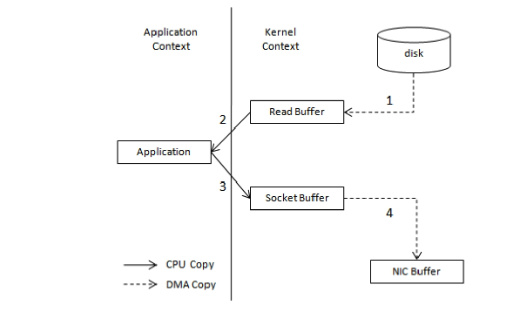
使用零拷贝技术的流程:
应用程序直接请求内核把磁盘中的数据传输给Socket。
零拷贝技术通过DMA技术将文件内容复制到内核模式下的Read Buffer中。相比不使用零拷贝技术,数据只经历了2次复制,上下文切换也减少为2次。

controller(控制器)设计
(1)controller概念
controller是在Kafka集群中,某个broker会被选举出来承担特殊的角色,用来管理集群中所有分区的状态并执行相应的管理操作。
每个Kafka集群中任意时刻都只能有一个controller,集群启动,所有broker会竞选controller,选举工作依赖Zk。
controller相比broker增加的职责如下:
- 监听分区相关的变化
- 监听主题相关的变化
- 监听broker相关的变化
- 更新集群的元数据信息
- 启动并管理分区状态机和副本状态机
参考文档
JVM JMM 运行时数据区(内存结构)
Java对象结构及大小计算
Kafka副本同步机制理解
图解Kafka的零拷贝技术到底有多牛?
kafka 解密:破除单机topic数多性能下降魔咒
关于作者
后端程序员,五年开发经验,从事互联网金融方向。技术公众号「清泉白石」。如果您在阅读文章时有什么疑问或者发现文章的错误,欢迎在公众号里给我留言。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号