脚本:获取CSDN文章的访问量
目标
- 获取所有文章名,链接,阅读人数,评论数
- 以适合pandas读取的格式存储之
分析
页面跳转
首页:http://blog.csdn.net/fontthrone?viewmode=list
第二页:http://blog.csdn.net/FontThrone/article/list/2
三四页以此类推
根据第二三四页的格式尝试http://blog.csdn.net/FontThrone/article/list/1
成功跳转:证明http://blog.csdn.net/fontthrone?viewmode=list = http://blog.csdn.net/FontThrone/article/list/1
那么获取不同的页面我们只需要通过跳转链接最后面的 数字来控制就好了,真是简单=- =
页面整体构成
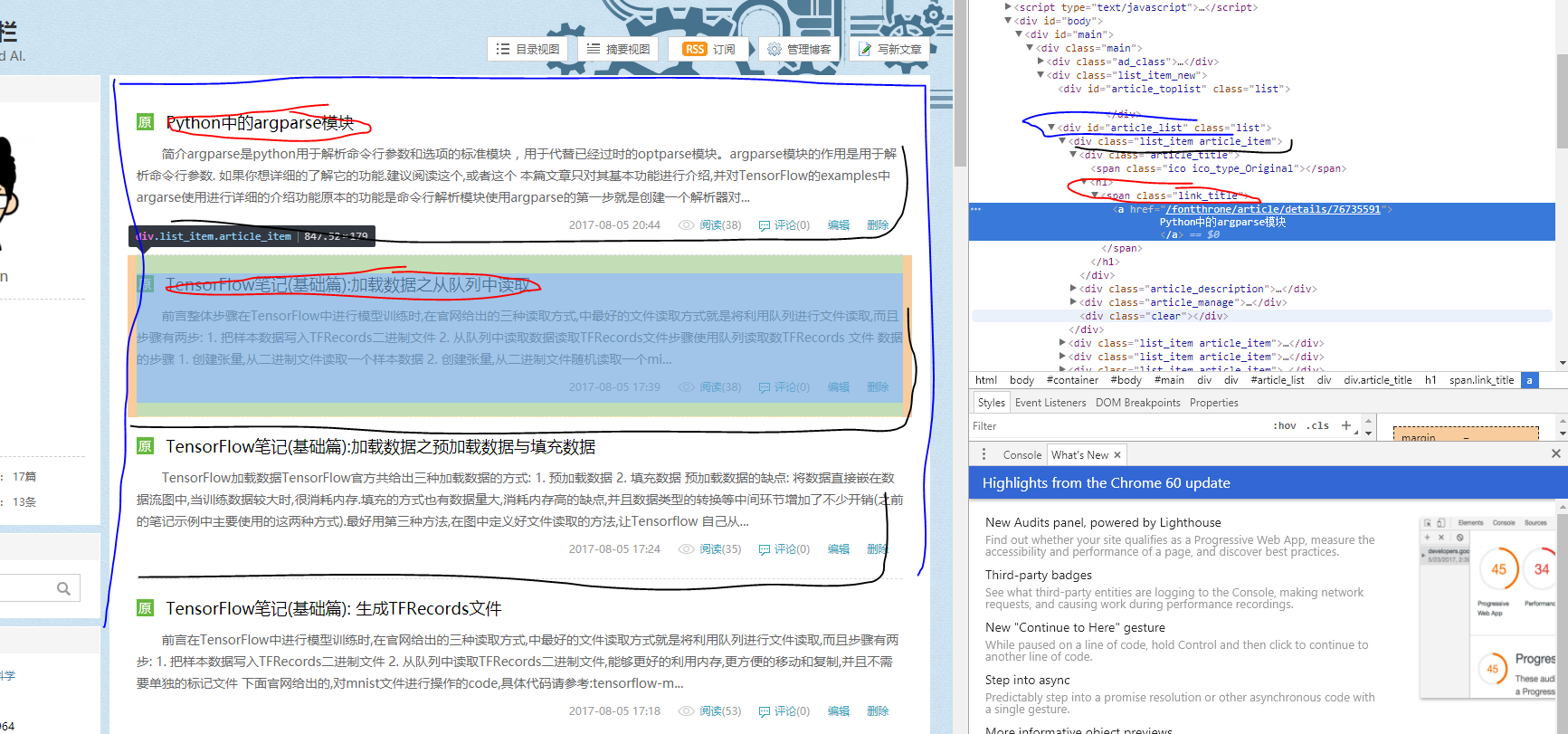
页面构成(class)如图所示
- article_list
- - list_item article_item
- - - article_title 标题
- - - - h1
- - - - - link_title
- - - - - - a
- - - article_description 文章摘要
- - - article_manage
- - - - link_postdate 日期
- - - - link_view 阅读人数
- - - - link_comments 评论数
- - - - link_edit 编辑
- - - clear
我们首先获取每一个- article_list,然后通过循环获取每个list_item article_item中的信息
细节
- 使用bs4 解析网页,减少了工作量
- a标签中的href使用 [‘href’] 获取
- 对于span中含有a标签+text的,获取text直接用正则进行获取
- 注意编码:1. 网页获取内容的编码 1. py文件的默认编码
代码分解
获取具体信息的方法
- 1.获取article_list
html = BeautifulSoup(response.text, 'html.parser')
blog_list = html.select('.list_item_new > #article_list > .article_item')- 2.获取article_title 以及文章链接
blog_title = house.select('.link_title > a')[0].string.encode('utf-8')
blog_title = str(blog_title.replace(' ', '').replace('\n', ''))
blog_url = urljoin(ADDR, house.select('.link_title > a')[0]['href'])- 3.获取 link_view 阅读人数 and link_comments 评论数
link_view = str(house.select('.article_manage > .link_view')[0])
blog_people = re.search(r'\d+', re.search(r'\(\d+\)', link_view).group()).group()
# 先获取span然后实用正则提取阅读人数
link_comment = str(house.select('.article_manage > .link_comments')[0])
blog_comment = re.search(r'\d+', re.search(r'\(\d+\)', link_comment).group()).group()
# 先获取span然后实用正则提取评论数写入CSV文件
import csv
# 引入类库
with open('info.csv', 'wb') as f:
csv_writer = csv.writer(f, delimiter=',')
# 创建-使用with,无需手动关闭
csv_writer.writerow(['blog_title', 'blog_url', 'blog_people', 'blog_comment'])
# 写入内列名,便于pandas使用(按行写入)
csv_writer.writerow([blog_title, blog_url,blog_people, blog_comment])
#按行写入 我们爬取的信息
CODE
真·CODE
初代机参考:http://blog.csdn.net/fontthrone/article/details/75287311
# - * - coding: utf - 8 -*-
#
# 作者:田丰(FontTian)
# 创建时间:'2017/8/5'
# 邮箱:fonttian@Gmaill.com
# CSDN:http://blog.csdn.net/fontthrone
#
from bs4 import BeautifulSoup
from urlparse import urljoin
import requests
import csv
import re
import sys
reload(sys)
sys.setdefaultencoding('utf8')
# account = str(raw_input('输入csdn的登录账号:'))
account = 'fontthrone'
URL = 'http://blog.csdn.net/' + account
ADDR = 'http://blog.csdn.net/'
start_page = 0
with open('info.csv', 'wb') as f:
csv_writer = csv.writer(f, delimiter=',')
csv_writer.writerow(['blog_title', 'blog_url', 'blog_people', 'blog_comment'])
print 'starting'
while True:
start_page += 1
URL2 = URL + '/article/list/' + str(start_page)
print URL2
response = requests.get(URL2)
html = BeautifulSoup(response.text, 'html.parser')
# print html
blog_list = html.select('.list_item_new > #article_list > .article_item')
# check blog_list
if not blog_list:
print 'No blog_list'
break
for house in blog_list:
blog_title = house.select('.link_title > a')[0].string.encode('utf-8')
blog_title = str(blog_title.replace(' ', '').replace('\n', ''))
link_view = str(house.select('.article_manage > .link_view')[0])
blog_people = re.search(r'\d+', re.search(r'\(\d+\)', link_view).group()).group()
link_comment = str(house.select('.article_manage > .link_comments')[0])
blog_comment = re.search(r'\d+', re.search(r'\(\d+\)', link_comment).group()).group()
blog_url = urljoin(ADDR, house.select('.link_title > a')[0]['href'])
csv_writer.writerow([blog_title, blog_url,blog_people, blog_comment])
print 'ending'
运行效果

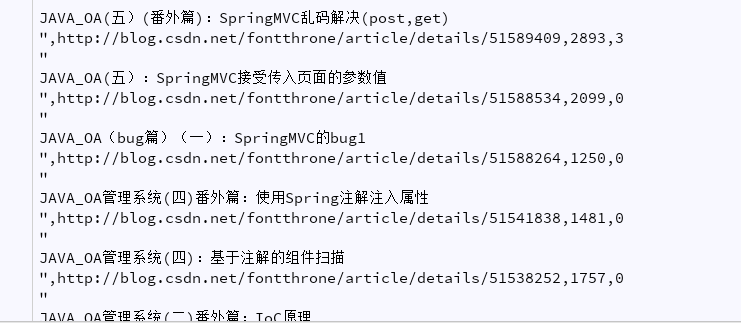
与pandas结合,升级刷访问量脚本初代机
说明
本代码仅供学习参考,不建议使用该脚本进行访问量的刷新
CODE
# blog_url =[
# 'http://blog.csdn.net/fontthrone/article/details/76675684',
# 'http://blog.csdn.net/FontThrone/article/details/76652772',
# 'http://blog.csdn.net/FontThrone/article/details/76652762',
# 'http://blog.csdn.net/FontThrone/article/details/76652753',
# 'http://blog.csdn.net/FontThrone/article/details/76652257',
# 'http://blog.csdn.net/fontthrone/article/details/76735591',
# 'http://blog.csdn.net/FontThrone/article/details/76728083',
# 'http://blog.csdn.net/FontThrone/article/details/76727466',
# 'http://blog.csdn.net/FontThrone/article/details/76727412',
# 'http://blog.csdn.net/FontThrone/article/details/76695555',
# 'http://blog.csdn.net/fontthrone/article/details/75805923',
# ]
import pandas as pd
df1 = pd.DataFrame(pd.read_csv('info.csv'))
blog_url = list(df1['blog_url'])补充
- 一代半有了,二代机还会远吗?
- 各位老铁,一波666走起,(滑稽.jpg)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号