Jieba分词介绍
概述
结巴分词是一款非常流行中文开源分词包,具有高性能、准确率、可扩展性等特点,目前主要支持python,其它语言也有相关版本,好像维护不是很实时。
分词功能介绍
这里只介绍他的主要功能:分词,他还提供了关键词抽取的功能。
- 精确模式
默认模式。句子精确地切开,每个字符只会出席在一个词中,适合文本分析;
Print "/".join(jieba.cut("我来到北京清华大学"))
我/来到/北京/清华大学
- 全模式
把句子中所有词都扫描出来, 速度非常快,有可能一个字同时分在多个词
print "/".join(jieba.cut("我来到北京清华大学", cut_all=True))
我/来到/北京/清华/清华大学/华大/大学
- 搜索引擎模式
在精确模式的基础上,对长度大于2的词再次切分,召回当中长度为2或者3的词,从而提高召回率,常用于搜索引擎。
print "/".join(jieba.cut_for_search("小明硕士毕业于中国科学院计算所,后在日本京都大学深造"))
小明/硕士/毕业/于/中国/科学/学院/科学院/中国科学院/计算/计算所/,/后/在/日本/京都/大学/日本京都大学/深造
- 词性分词
只支持精确模式分词,同时给出词的词性
for w, f in pseg.cut("我叫李小明, 我来到北京清华大学"):
print u"{}_{}".format(w, f),
我_r 叫_v 李小明_nr ,_x _x 我_r 来到_v 北京_ns 清华大学_nt
- 新词发现
Jieba默认会对连续的单个字符使用HMM进行新词识别
print "/".join(jieba.cut("我是李华,我来到北京清华大学"))
print "/".join(jieba.cut("我是李华,我来到北京清华大学", HMM=False))
我|是|李华|,|我|来到|北京|清华大学
我|是|李|华|,|我|来到|北京|清华大学
自定义词表
个人认为,自定义词表是结巴最大的优势,提高准确率,方便后续扩展,常见模型分词做不到这点。
print "/".join(jieba.cut("大家好,我是春雨医生"))
jieba.add_word(u"春雨医生") # 添加自定义词
print "/".join(jieba.cut("大家好,我是春雨医生"))
大家/好/,/我/是/春雨/医生
大家/好/,/我/是/春雨医生
当然你也可以直接添加一个词典文件
用法: jieba.load_userdict(file_name)
词典格式和 dict.txt 一样,一个词占一行;每一行分三部分:词语、词频(可省略)、词性(可省略),用空格隔开。
词频省略时使用自动计算的能保证分出该词的词频。
例如:
创新办 3 i 云计算 5 凱特琳 nz 台中
删除词:del_word(word)
jieba分词原理说明
结巴分词其实就是通过词典分词,然后对不在词典的词使用HMM算法识别新词。
- 基于词典分词
属于分词中的词表分词。结巴主要基于有向无环图的查找算法,通过动态规划,从后至前使得词的切割组合联合概率最大。下面以“春雨医生你好全身红疹子”为例
假设我们的词典如下
春雨 100 n 医生 100 n 春雨医生 100 n 你好 100 n 全身 100 n 红疹 100 n 疹子 100 n
从而有向无环图如下:

每个词都会有一个连接的有向边,字本身都会有一个自我连接的边。用索引位置代表字符,邻接链表存取表示如下。0:[0, 1, 3]代表春可以组成词[春, 春雨, 春雨医生]
{0: [0, 1, 3], 1: [1], 2: [2, 3], 3: [3], 4: [4, 5], 5: [5]}
如果我们给每条路径加上权重,从而我们的分词转换成了求最大路径,将最大路径转换成分词的目标函数就是最大联合概率(路径相乘)。我们先看春雨医生四个字,这四个字没有与其他字的路径,也就是说这四个字的分词是独立,他们的最大路径必定也是整个句子的最大路径的子路径。春雨医生四个字总共存在四条路径:[春,雨,医,生]、[春雨,医,生]、[春雨,医生]、[春雨医生]。每条边的权重即这个词的概率为:p=freq/total,freq代表这个词的频数,也就是我们在词表里面设定的100,total为所有词频数之和,由于freq小于total,那么p是小于1的。简单计算:p[春,雨,医,生]<p[春雨,医,生]<p[春雨,医生]<p[春雨医生],我们会发现jieba倾向于分出更长的词,这是因为词权重小于1,相乘越多越小。权重在在分词中到底是做什么的?消歧,当某个字属于多个互不包含的词时,例如我的红疹与疹子两个词中诊应该和谁集合,这时就是权重起作用的时候。如果freq(红疹)*freq(子)>=freq(红)*freq(疹子)就分为红+疹子。整个句子的计算其实就是一个简单动态规划。从后至前,后面某个阶段的最大分词结果作为前面的结果,例如计算身位置后的路径总权重时,只需要将红疹子的最大权重赋给身就行了。计算参考jieba/__init__.py中的calc方法:
def calc(self, sentence, DAG, route):
N = len(sentence)
route[N] = (0, 0)
logtotal = log(self.total)
for idx in xrange(N - 1, -1, -1):
route[idx] = max((log(self.FREQ.get(sentence[idx:x + 1]) or 1) - logtotal + route[x + 1][0], x) for x in DAG[idx])
- 基于HMM的新词识别
有时候我们的词表并不能覆盖所有的词,如果不加处理就会被识别为单个字符,jieba是使用HMM来进行二次分词,即新词的识别。HMM属于分词中的序列标注,使用模型识别词每个位置的状态值。
HMM的原理我不详细介绍,有兴趣的可以查看其它资料。
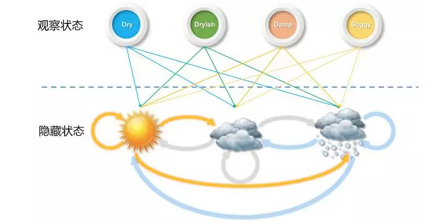
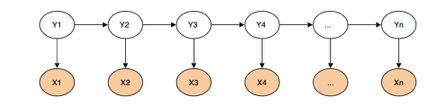
HMM主要由两部分组成观察序列X与隐藏序列Y,隐藏序列是我们要预测的序列。和传统预测模型不一样,HMM还考虑被预测值的前后关系,以前面的天气预测为例,如果去预测明天,那么我们就可以用今天的观测值湿度等特征以及今天的隐藏值天气情况去预测明天。
在分词中,观察序列即输入的字符,输出数列用“BEMS”代表。其中,B代表该字是词语中的起始字,M代表是词语中的中间字,E代表是词语中的结束字,S则代表是单字成词。“春雨医生/你好/全身/红疹/子”就可以表示为BMME/BE/BE/BE/S,由此可见HMM分词就是要预测所有字符的BEMS值。
在分词中我们常用Viterbi算法来计算HMM。它主要训练以下三张表:状态的初始概率表π,输出序列直接转移关系表A,观察序列到输出序列的转移概率表B,详细实例请参考
其它分词
目前比较常见的分词都是基于序列标注的方法,即用更加复杂的模型来代替HMM,然后来预测字符的“BEMS”值。比较常见的模型主要为CRF和深度学习。
- 基于CRF的分词方法
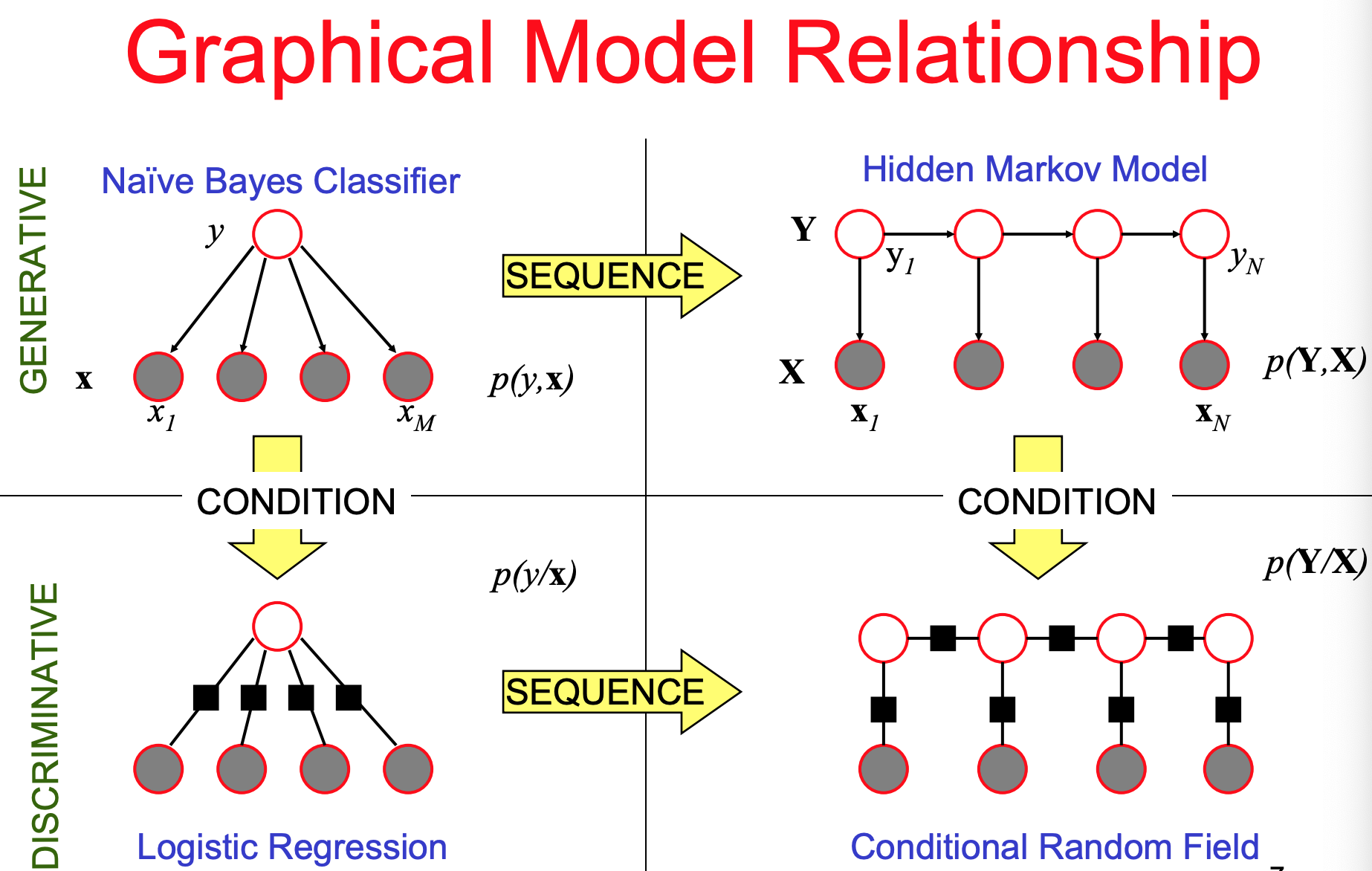
HMM是生成模型它是通过查表寻找联合概率最大的组合,而CRF是判别模型,它是通过构造一个预测输出序列类别概率(字符在BEMS类别的概率)的目标函数。其实CRF是HMM随机场的更一般形式,HMM假设随机场中某一个位置的赋值仅仅与和它相邻的位置的赋值有关,和与其不相邻的位置的赋值无关。HMM中使用两个转移矩阵的联合概率表示输出变量Y,而CRF是用一个特征函 表示观测变量与输出变量的关联关系,其中X表示输入变量,i为当前位置,y表示输出状态值。f_k其实是节点特征函数与局部特征函数的统一表示。在分词中构建出联合概率函数就可以求解出每个位置的“BEMS”值了。
- 基于深度学习的分词方法
目前比较成熟的方法主要使用双向LSTM+CRF实现,其本质也输入序列标注,所以具有通用性,命名实体识别等都可以使用该模型(把词的类别BEMS换成相应的实体类别)。
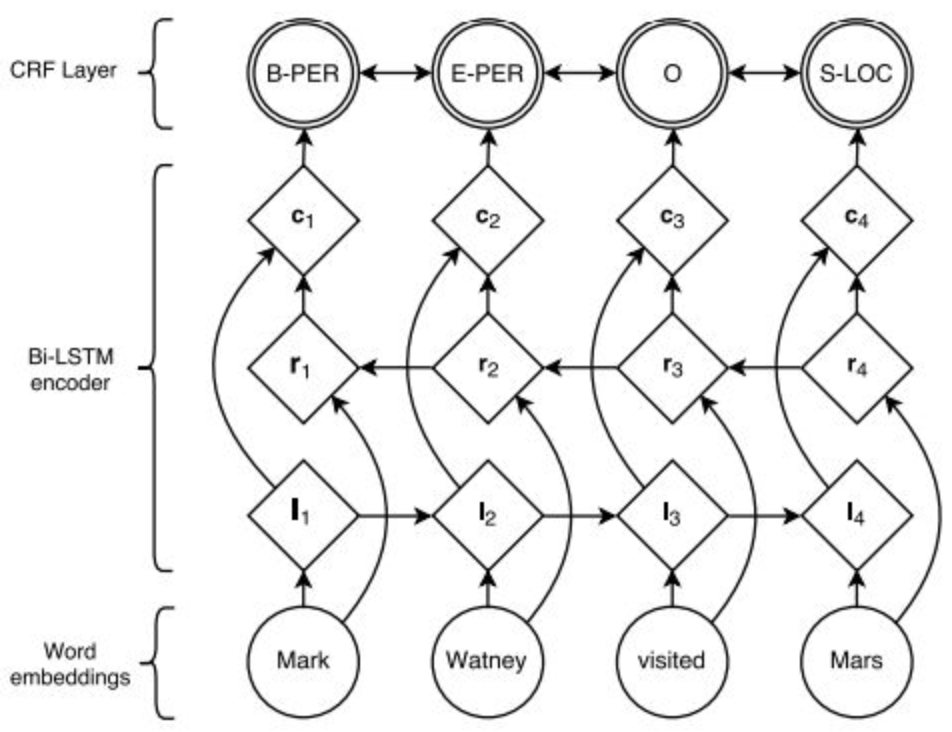
图:LSTM+CRF框架
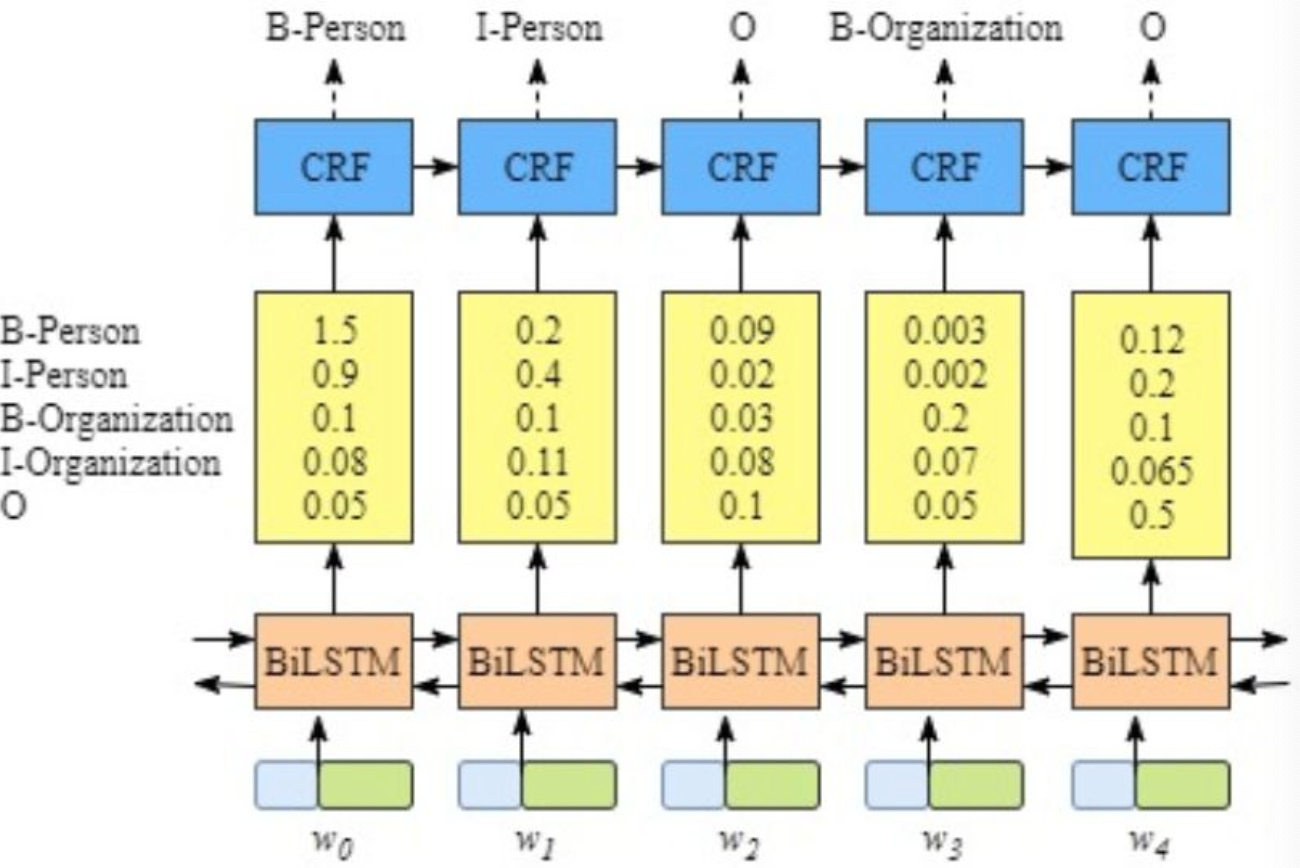
图:实体识别
从上图可以看出BiLSTM-CRF主要有三层,输入层:词的embedding;中间层:双向LSTM网络,得到一个序列特征向量;目标层:LSTM的输出向量为特征,预测类别为目标,CRF为损失函数。该模型目前已有开源的方法FoolNLTK,当然你也可以用目前最火的BERT模型替换LSTM,我相信效果会比较好。
模型分词相对于jieba会慢很多,他还有一个比较严重的缺陷就是不能引入词表,特别对于一些新词,模型很难学出该部分特征,往往无法识别。FoolNLTK虽然可以加入词表,但是他是在模型分完词的结果上进行的调整。我觉得可以尝试在深度学习里面加入更多的特征满足该需求。
参考资料
分词简介: https://zhuanlan.zhihu.com/p/33261835
结巴分词: https://github.com/fxsjy/jieba
HMM介绍: https://www.leiphone.com/news/201704/nT29tSWJlJ0WsWL7.html
CRF: https://cedar.buffalo.edu//~srihari/CSE574/Chap13/Ch13.5-ConditionalRandomFields.pdf
CRF:https://zhuanlan.zhihu.com/p/29989121
Bi-LSTM+CRF: https://www.unclewang.info/learn/machine-learning/756/
Fool分词:https://github.com/rockyzhengwu/FoolNLTK

 浙公网安备 33010602011771号
浙公网安备 33010602011771号