MOBIUS: Towards the Next Generation of Query-Ad Matching in Baidu's Sponsored Search——百度下一代搜索广告系统
Posted on 2022-02-23 19:37 foghorn 阅读(339) 评论(0) 收藏 举报简介
传统的广告最终的呈现需要经过召回与排序两个阶段,百度的搜索架构则采用三层漏斗状,如图1所示。最上面的一层用于筛选出和用户查询最相关的一部分广告,将整个候选广告集从亿级降到千级;下面两层是排序阶段,需要结合具体的业务,对召回的广告进行最终的排序、展示。三层结构相较于两层结构更多的是从计算资源与业务目标上的考量。
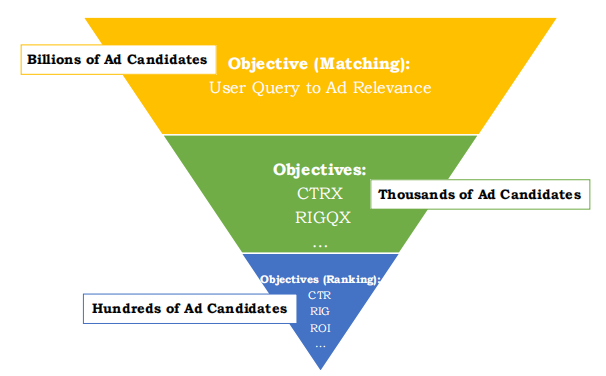
然而这种“召回——排序”模式存在的主要问题是:召回阶段的优化目标和排序阶段的优化目标是不一样的,这就可能导致召回的样本不具备太多商业价值。针对这一问题,百度团队提出在召回阶段兼顾排序阶段的目标(如CTR、ROI),从而将两阶段模式融合成一个阶段。
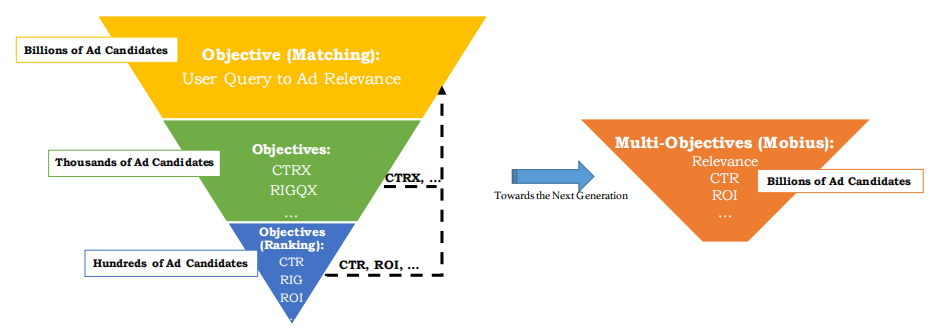
总体而言,该论文的创新之处有两点:
- 在召回层保证相关性的同时引入了CPM等业务指标作为召回的依据;
- 将以往的CTR预估模型融合到召回层中,提出一种全新的多目标商业召回系统架构。
问题建模
传统两阶段广告排序模型的召回层注重召回结果的相关性,用公式表达为:
召回阶段的优化目标和排序阶段的优化目标不一样,这可能导致召回的样本不具备太多商业价值。因此百度的解决方案是将两阶段模式融合成一个阶段,在召回阶段同时兼顾排序阶段的优化目标,问题建模为:
如何在数以亿计的样本中兼顾召回的相关性和排序阶段的CTR、CPM等目标?一个直观的方案是在召回阶段引入排序阶段的模型,但是如果不加改动地直接使用排序模型会导致一些问题。我们知道,排序阶段的样本是召回阶段筛选出的与用户查询较为相关的一部分样本,然后经过排序后一部分样本会获得较高的CTR值,这是没问题的。然而直接在海量数据上进行排序,会导致与用户查询不相关的样本仍有很高的CTR,但这部分样本用户并不关心。

为了解决这一问题,需要在排序之前让排序模型能够区分相关性低的样本。
模型架构
召回阶段需要计算样本与给定查询的相关性,在进行排序之前,先用召回模型计算query和id的相关性,把相关性较低的<query,ad>对筛选出来,该模块称为“Relevance Judger”。模型主要分为两个部分,数据增强模块和CTR建模模块,整体架构如下图所示。
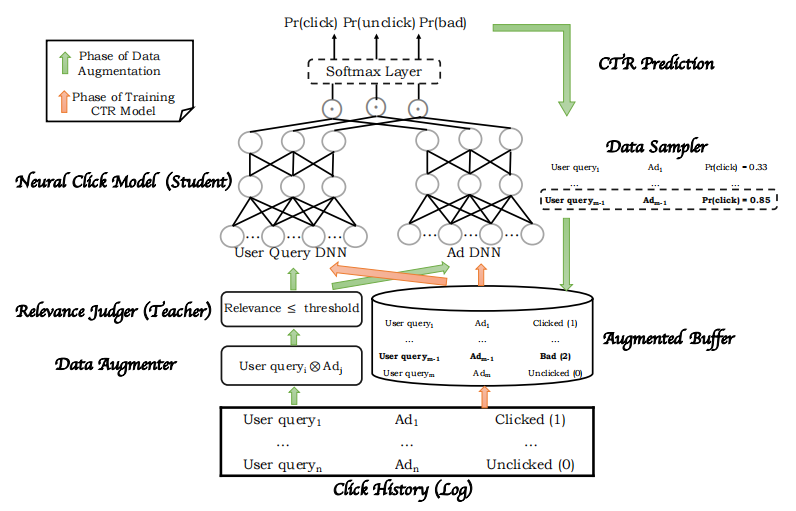
输入是一个batch的<query,ad>对,在进行后续处理之前,需要拆分成两个集合——query集和ad集;
Data Augmenter模块对上一步拆分的query集和ad集做笛卡尔积,假设query集有m个元素,ad集有n个元素,则该模块会输出m*n个元素,包含很多虚拟的<query, ad>对;
接着通过Relevance Judger把相关性低于指定阈值的<query, ad>对筛选出来,然后送入到点击率预估网络中计算其CTR;
Data Sampler模块根据CTR值采样出一部分CTR值较高的样本,称为bad case。将该部分数据和一开始输入的<query, ad>对混合,最后送入到CTR预估网络中。与一般CTR预估模型的二分类(点击/不点击)输出不同的是,该架构的输出还包括bad case情况,是一个三分类问题。
总的来说,该架构训练网络,使其能够将与用户查询相关性低但是CTR高的ad标记为bad case。利用相关性召回模型 ( teacher ) 来“教”会CTR模型 ( student ) 哪些样本是badcase,所以这里首先利用相关性模型对构造的query-ad pair进行相关性打分,并从中筛选出来相关性较低的样本交给CTR模型进行预测,根据预测的PCTR值从中选出低相关性高PCTR的样本作为badcase ( 这类样本在原始CTR样本中是不存在的,是为了让CTR模型学会哪些是badcase而构建出来的,原始的CTR模型是不需要关注相关性的,只需要关注CTR )。
线上召回
离线训练好模型以后,可以通过图4中的User Query DNN和Ad DNN获得用户查询的Embedding和广告的Embedding,给定一个query embedding,需要找到若干和该查询相关的广告,然而在全体样本集里面一个一个查找可能的ad embedding在上线阶段是不可行的。因此百度采用ANN(近似最近邻)技术加速筛选过程。
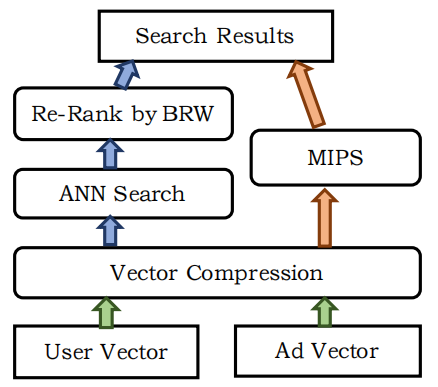
为了最终排序结果的精确性,通常在排序之前要考虑业务相关权重信息,而ANN方案是先召回在考虑业务权重进行精排,MIPS则是将业务指标改写进了相似度计算的公式中,也就是在检索的过程中就考虑商业指标。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号