已知基于数据驱动的机器学习和优化技术在单场景内的A/B测试上,点击率、转化率、成交额、单价都取得了不错的效果。 但是,目前各个场景之间是完全独立优化的,这样会带来哪些比较严重的问题 ?
[解答]
-
不同场景的商品排序仅考虑自身,会导致 用户的购物体验是不连贯或者雷同的 。例如:从冰箱的详情页进入店铺,却展示手机;各个场景都展现趋同,都包含太多的U2I(点击或成交过的商品);
-
多场景之间是博弈(竞争)关系, 期望每个场景的提升带来整体提升这一点是无法保证的 。很有可能一个场景的提升会导致其他场景的下降,更可怕的是某个场景带来的提升甚至小于其他场景更大的下降。这并非是不可能的,这种情况下,单场景的A/B测试就显得没那么有意义,单场景的优化也会存在明显的问题。
推荐页与搜索页特性有什么不同?
[解答]
-
搜索带着 query 来的,结果与之相关性越高越好,不用太关心结果的多样性
-
推荐页用户没有明确的目的,但是有兴趣偏好和对结果的多样性需求,推荐既要准确又要多样化。
常见的多路召回策略
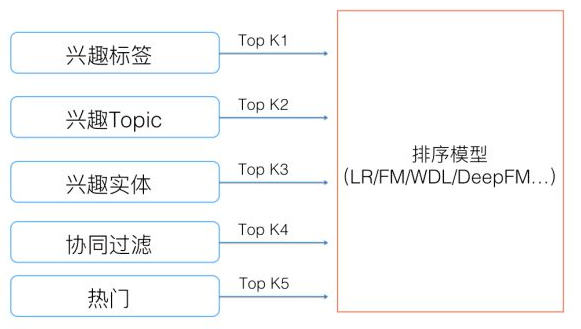
目前工业界的推荐系统,在召回阶段,一般都采取多路召回策略。上图展示了一个简化版本的例子,以微博信息流排序为例,不同业务召回路数不太一样,但是常用的召回策略,基本都会包含,比如兴趣标签,兴趣Topic,兴趣实体,协同过滤,热门,相同地域等,多者几十路召回,少者也有7/8路召回。
什么是DSSM?有什么优缺点?
[解答]
-
DSSM(Deep Structured Semantic Models)的原理很简单,通过搜索引擎里 Query 和 Title 的海量的点击曝光日志,用 DNN 把 Query 和 Title 表达为低纬语义向量,并通过 cosine 距离来计算两个语义向量的距离,最终训练出语义相似度模型。该模型既可以用来预测两个句子的语义相似度,又可以获得某句子的低纬语义向量表达。
-
优点:DSSM 用字向量作为输入既可以减少切词的依赖,又可以提高模型的范化能力,因为每个汉字所能表达的语义是可以复用的。另一方面,传统的输入层是用 Embedding 的方式(如 Word2Vec 的词向量)或者主题模型的方式(如 LDA 的主题向量)来直接做词的映射,再把各个词的向量累加或者拼接起来,由于 Word2Vec 和 LDA 都是无监督的训练,这样会给整个模型引入误差,DSSM 采用统一的有监督训练,不需要在中间过程做无监督模型的映射,因此精准度会比较高。
-
缺点:DSSM 采用词袋模型(BOW),因此丧失了语序信息和上下文信息。另一方面,DSSM 采用弱监督、端到端的模型,预测结果不可控。
怎样将知识图谱引入推荐系统 ?
[解答]
-
基于特征的知识图谱辅助推荐,核心是知识图谱特征学习的引入。一般而言,知识图谱是一个由三元组<头节点,关系,尾节点> 组成的异构网络。由于知识图谱天然的高维性和异构性,首先使用知识图谱特征学习对其进行处理,从而得到实体和关系的低维稠密向量表示。这些低维的向量表示可以较为自然地与推荐系统进行结合和交互。
-
基于结构的推荐模型,更加直接地使用知识图谱的结构特征。具体来说,对于知识图谱中的每一个实体,我们都进行宽度优先搜索来获取其在知识图谱中的多跳关联实体从中得到推荐结果。
如何离线评价召回阶段各种模型算法的好坏?由于没有明确的召回预期值,所以无论rmse还是auc都不知道该怎么做?
[解答]
- 召回最直接的评估就是召回率,也就是召回集里正样本的比例;也可以不同的召回算法+同一个排序算法,还是用排序之后的AUC和RMSE来评估。
普通的逻辑回归能否用于大规模的广告点击率预估 ,为什么?
[解答]
不能
-
第一,数据量太大。传统的逻辑回归参数训练过程都依靠牛顿法(Newton's Method)或者 L-BFGS 等算法。这些算法并不太容易在大规模数据上得以处理。
-
第二,不太容易得到比较稀疏(Sparse)的答案(Solution)。也就是说,虽然数据中特征的总数很多,但是对于单个数据点来说,有效特征是有限而且稀疏的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号