
摘要
近年来,深度神经网络在语音识别、计算机视觉和自然语言处理方面取得了巨大的成就。然而,对推荐系统领域的深度神经网络的探索收到的关注相对较少。
虽然已经有一部分工作将深层神经网络引入到了推荐系统中,但主要使用深度神经网络来处理额外的信息,比如商品的文本描述。当涉及到建模协同过滤的关键因素——用户和商品之间的交互时,现有公所仍然采用矩阵分解的思想,将用户和商品的潜在特征做内积来表示用户对商品的购买行为。
我们提出了一个通用的框架——NCF(Neural network-based Collaborative Filtering),用神经网络结构来代替向量的内积操作,可以拟合任意的函数。
准备工作
从隐式数据中学习
令\(M\)和\(N\)代表用户和商品的数量,从用户和商品的隐式交互数据中可以定义如下用户——商品交互矩阵:
推荐系统的目标就是找到一个策略来补全用户——商品交互矩阵中的缺失项,即:\(\hat y_{ui}=f(u,i|\Theta )\)。其中\(\hat y_{ui}\)是模型的预测值,\(\Theta\)代表模型的参数。
矩阵分解
矩阵分解模型为每个用户和商品都分配了一个潜在的特征向量。用\(p_{u}\)和\(q_{i}\)代表用户\(u\)和商品\(i\)的潜在特征向量,矩阵分解模型用这两个向量的乘积代表用户对商品可能的购买行为:
其中\(K\)代表潜在特征向量的维度。
神经协同过滤
通用框架
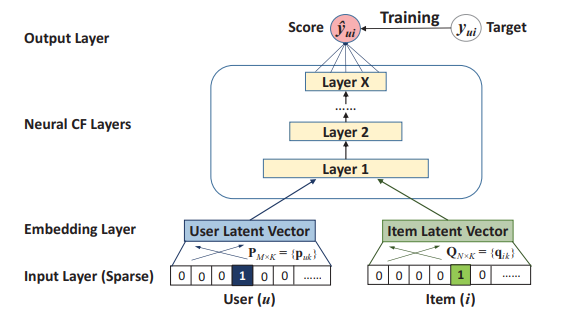
作者用MLP来对用户和商品的特征向量进行深层次的特征交互,如图1所示,输入层是用户和商品的one-hot编码,分别经过嵌入层,变成低维的特征,接着将低维的用户和商品特征向量拼接到一起输入到MLP中,计算该用户购买该商品的概率。
通用矩阵分解(GMF)
矩阵分解模型可以作为NCF框架的一个特例。输入数据是用户和商品的one-hot编码,经过Embedding Layer得到的向量可以分别看作用户和商品的潜在特征,即:\(p_{u}=P^{T}v^{U}_{u}\),\(q_{i}=Q^{T}v^{I}_{i}\)。第一个神经协同过滤层可以定义为:
模型的输出定义为:
\(a_{out}\)和\(h^{T}\)分别代表激活函数和边的权重。
多层感知机(MLP)
图1所示的NCF框架,分别将用户和商品的one-hot编码作为输入,然后经过嵌入层得到各自的特征向量,最后将两个向量拼接到一起,输入到多层感知机中。这样做的目的是对商品的特征和用户的特征进行深度的非线性融合。
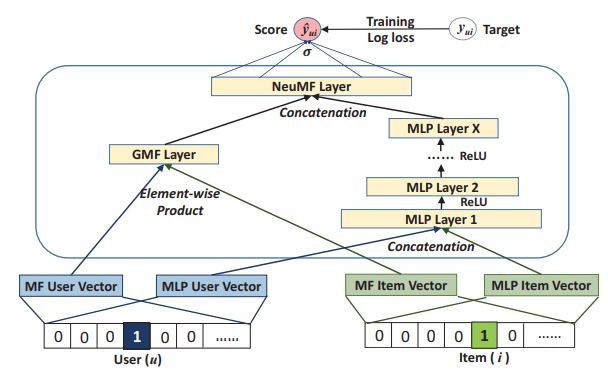
通用矩阵分解和MLP的融合
可以认为GMF模型是一种线性的模型,融合了用户和商品的线性交互特征;MLP模型更够更深层次的融合非线性特征。一种自然的融合方法是使GMF和MLP共享用户和商品嵌入层,但作者任务这样做限制了模型的表达能力。文中的做法是,将GMF和MLP的嵌入层分开,分别学习,将两者得到的最终隐向量拼接到一起。
实验
实验设置
数据集

文中对原始数据集做了适当预处理,即过滤掉交互数据少于20个的用户。
评估
采用留一法划分训练集和测试集,将用户最近的一次交互数据划分到测试数据中,其余的交互数据都作为训练集。为了构建负样本,需要对所有的未交互数据进行采样,因为如果将全体未交互数据都当作负样本的话,数据量太大了。文中采用的做法是随机为测试集中的用户采样100个未交互的商品作为负样本;随机为训练集中的用户采样4个未交互的商品作为负样本。
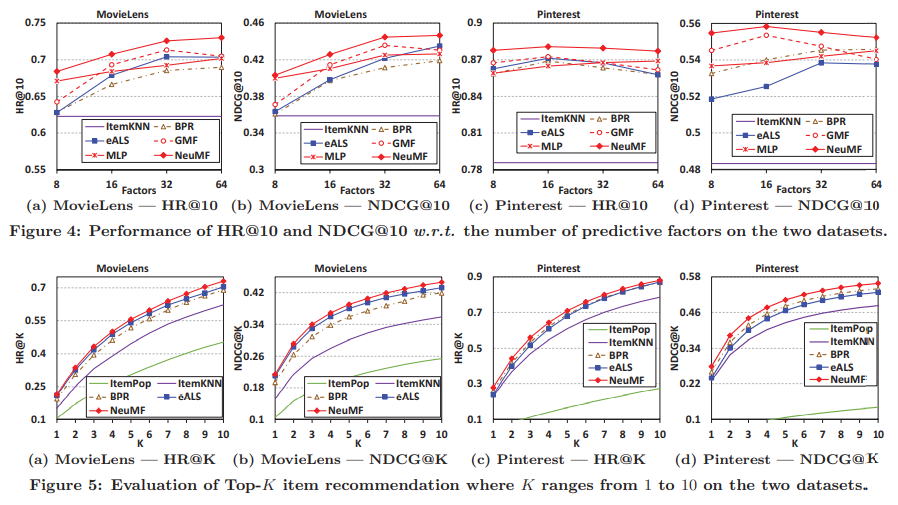
实验结果
代码复现
文件结构
准备数据
import torch
import tqdm
import random
from torch.utils.data import Dataset
class GetData(Dataset):
def __init__(self, data_path, mode='training', negs=99):
self.negs = negs
self.mode = mode
self.user_nums = 6040
self.item_nums = 3706
self.data_path = data_path
self._init_dataset()
def _init_dataset(self):
self.Xs = []
self.user_item_map = {}
for i in range(self.user_nums):
self.user_item_map[i] = []
with open(self.data_path, 'r') as f:
f.readline() # 先读取第一行
while True:
line = f.readline()
if not line:
break
user_id, item_id, _ = list(map(int, line.strip('\n').split(',')))
self.user_item_map[user_id].append(item_id)
pass
if self.mode == 'training':
for user, items in tqdm.tqdm(self.user_item_map.items()):
for item in items[:-1]:
self.Xs.append((user, item, 1))
for _ in range(3):
while True:
neg_sample = random.randint(0, self.item_nums - 1)
if neg_sample not in self.user_item_map[user]:
self.Xs.append((user, neg_sample, 0))
break
else:
for user, items in tqdm.tqdm(self.user_item_map.items()):
if len(items) == 0:
continue
self.Xs.append((user, items[-1]))
def __getitem__(self, index):
if self.mode == 'training':
user_id, item_id, label = self.Xs[index]
return user_id, item_id, label
elif self.mode == 'validation':
user_id, item_id = self.Xs[index]
negs = list(
random.sample(
list(set(range(self.item_nums)) - set(self.user_item_map[user_id])), self.negs
)
)
return user_id, item_id, torch.LongTensor(negs)
def __len__(self):
return len(self.Xs)
NCF模型
import torch
import torch.nn as nn
class NCFModel(nn.Module):
def __init__(self, hidden_dim, user_num, item_num, mlp_layer_num=3, weight_decay=1e-5, dropout=0.5):
super().__init__()
self.hidden_dim = hidden_dim
self.user_num = user_num
self.item_num = item_num
self.mlp_layer_num = mlp_layer_num
self.weight_decay = weight_decay
self.dropout = dropout
self.mlp_user_embedding = nn.Embedding(
self.user_num,
self.hidden_dim * (2 ** (self.mlp_layer_num - 1))
) # (user_num, 64)
self.mlp_item_embedding = nn.Embedding(
self.item_num,
self.hidden_dim * (2 ** (self.mlp_layer_num - 1))
) # (item_num, 64)
self.gmf_user_embedding = nn.Embedding(self.user_num, self.hidden_dim) # (user_num, 16)
self.gmf_item_embedding = nn.Embedding(self.item_num, self.hidden_dim) # (item_num, 16)
mlp_layers = []
input_size = int(self.hidden_dim * (2 ** self.mlp_layer_num))
for i in range(self.mlp_layer_num):
mlp_layers.append(nn.Linear(int(input_size), int(input_size / 2)))
mlp_layers.append(nn.Dropout(self.dropout))
mlp_layers.append(nn.ReLU())
input_size /= 2
self.mlp_layers = nn.Sequential(*mlp_layers)
self.output_layer = nn.Linear(2 * self.hidden_dim, 1)
def forward(self, user, item):
user_gmf_embedding = self.gmf_user_embedding(user)
item_gmf_embedding = self.gmf_item_embedding(item)
user_mlp_embedding = self.mlp_user_embedding(user)
item_mlp_embedding = self.mlp_item_embedding(item)
gmf_output = user_gmf_embedding * item_gmf_embedding
mlp_input = torch.cat([user_mlp_embedding, item_mlp_embedding], dim=-1)
mlp_output = self.mlp_layers(mlp_input)
output = torch.sigmoid(self.output_layer(
torch.cat([gmf_output, mlp_output], dim=-1)
)).squeeze(-1) # (batch_size,)
return output
def predict(self, user, item):
"""
:param user: 用户 id, 单个值
:param item: 正样本和负样本的 id, 是一个列表
:return:
"""
self.eval()
with torch.no_grad():
user_gmf_embedding = self.gmf_user_embedding(user)
item_gmf_embedding = self.gmf_item_embedding(item)
user_mlp_embedding = self.mlp_user_embedding(user)
item_mlp_embedding = self.mlp_item_embedding(item)
gmf_output = user_gmf_embedding.unsqueeze(1) * item_gmf_embedding
user_mlp_embedding = user_mlp_embedding.unsqueeze(1).expand(-1,
item_mlp_embedding.shape[1], -1
)
mlp_input = torch.cat([user_mlp_embedding, item_mlp_embedding], dim=-1)
mlp_output = self.mlp_layers(mlp_input)
output = torch.sigmoid(
self.output_layer(torch.cat([gmf_output, mlp_output], dim=-1))
).squeeze(-1)
return output
if __name__ == "__main__":
ncf = NCFModel(16, 6040, 3706)
print(ncf)
主模块
import torch
from torch.utils.data import DataLoader
from ncf import NCFModel
from dataprocesing import GetData
from draw import draw
seed = 114514
batch_size = 512
hidden_dim = 16
epochs = 1
device = torch.device('cuda:0') if torch.cuda.is_available() else torch.device('cpu')
train_dataset = GetData('data/ratings.txt', 'training')
validation_dataset = GetData('data/ratings.txt', 'validation')
train_loader = DataLoader(
dataset=train_dataset,
batch_size=batch_size,
shuffle=True,
drop_last=False,
num_workers=0
)
valid_loader = DataLoader(
dataset=validation_dataset,
batch_size=1,
shuffle=True,
drop_last=False,
num_workers=0
)
model = NCFModel(hidden_dim, train_dataset.user_nums, train_dataset.item_nums).to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3)
loss_func = torch.nn.BCELoss()
loss_log = []
hit_log = []
losses = []
for epoch in range(epochs):
for index, data in enumerate(train_loader):
user, item, label = data
user, item, label = user.to(device), item.to(device), label.to(device).float()
y_ = model(user, item).squeeze()
loss = loss_func(y_, label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
losses.append(loss.detach().cpu().item())
hit = []
for index, data in enumerate(valid_loader):
user, pos, neg = data
pos.unsqueeze_(1)
all_data = torch.cat([pos, neg], dim=-1)
output = model.predict(user.to(device), all_data.to(device)).detach().cpu()
for batch in output:
if 0 not in (-batch).argsort()[:10]:
hit.append(0)
else:
hit.append(1)
print('epoch {} finished, average loss {}, hit@20 {}'.format(epoch, sum(losses) / len(losses),
sum(hit) / len(hit)))
loss_log.append(sum(losses) / len(losses))
hit_log.append(sum(hit) / len(hit))
draw(losses)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号