导读
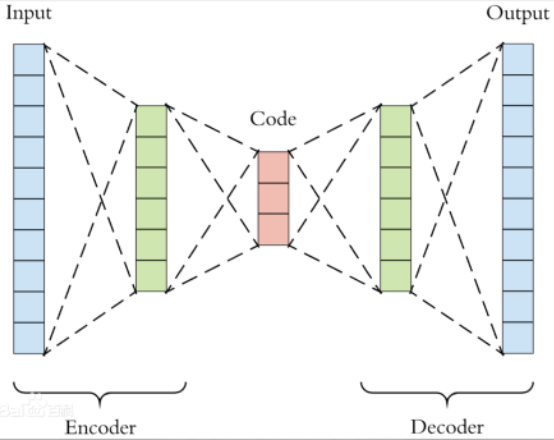
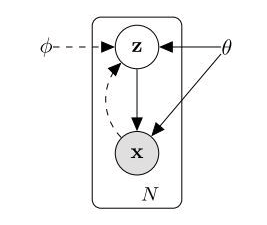
变分自编码器(VAE)是一种生成式模型,虽然名字上叫做自编码器,但却和普通的自编码器有着本质上的区别。图a所示为一个普通自编码器的示意图,其功能是将输入数据压缩到一个低维的空间中,这个低维的向量代表了输入数据的“精华”,如何保证低维的向量能够表示输入向量呢?自编码器在将低维向量解码成输出向量时,会使重构误差尽可能地小,即输出的向量与原始向量尽可能地接近。经过这样的处理我们遇到一个新的样本数据时,只要将其输入到自编码器的编码部分,就可以用的到的低维向量代表这个样本,所以说基本自编码器实际上是一个数据转换的过程,即将原始高维的数据用低维的数代替,从而方便我们处理后续任务。而变分自编码器(如图b所示),其中间的编码不是低维向量那么简单,而是代表一个分布的参数。我们假设观测变量\(x\)(即样本)是受到某个隐变量\(z\)的影响而产生的,即通过\(z\)可以生成\(x\)。那么如果我们知道了\(z\)的概率分布,从中采样出一个样本\(z_{i}\),就可以生成一个新的数据\(x_{i}\)。变分自编码器广泛应用与图像生成领域,一个好的VAE可以生成十分逼真的图像。
建模
如上一节所说,我们假设观测变量\(x\)受隐变量\(z\)的影响,只要知道隐变量\(z\)的分布\(p(z)\)便可通过采样得到一个新的数据,现在我们只知道样本数据,因此一个直观的方法是通过样本来推断隐变量\(z\)的分布,即求\(p(z|x)\)。根据贝叶斯公式:
想要求得\(p(z|x)\),首先要知道\(p(x)\),而\(p(x)\)我们是不知道的,因此直接求解\(p(z|x)\)的方法十分麻烦。退而求其次,可以引入一个新的分布\(q(z|x)\),用这个分布去逼近\(p(z|x)\)。既然引入\(q(z|x)\),那么\(q(z|x)\)的分布须是已知的,并且要尽量简单,我们通常假设\(q(z|x)\)服从对角化协方差的高斯分布:
我们希望引进的分布\(q(z|x)\)与\(p(z|x)\)越接近越好。衡量两个分布之间相似性的指标可以用KL散度:
于是我们的目标即为最小化KL散度:
接下来进行必要的数学推导:
由于\(p(x)\)是固定值,\(\int q(z|x)dz=1\),上式中间部分就等于\(logp(x)\),继续推导:
别忘了我们的目的是最小化上面的公式,而\(logp(x)\)是固定的,因此只需要最小化右边两个部分,记作\(L\),即:
即最大化:
上式第一部分是说:不断在\(z\)上采样,然后使得被重构的样本中重构\(x\)的几率最大;第二部分衡量的是引入的分布\(q(z|x)\)与隐变量\(z\)的分布\(p(z)\)的相似性,一般我们假设隐变量\(z\)服从标准高斯分布,即:
为了用梯度下降算法求解,我们重新整理一下目标函数:
至此,变分自编码器的目标函数已经构建完成。
重参数化
上一节谈到目标函数\(J\)包含从分布\(N(\mu _{I},\sigma ^{2}_{I}I)\)中采样出一个\(z\),然后重构回到\(x\)的损失,而“采样”这个操作是不可导的。我们可以用如下操作来代替:从\(N(\mu,\sigma ^{2})\)中采样一个\(z\),相当于从标准正态分布\(N(0, 1)\)中采样一个\(\epsilon\),然后让\(z=\mu + \epsilon \times \sigma\)。最后总结一下变分自编码器的操作过程。
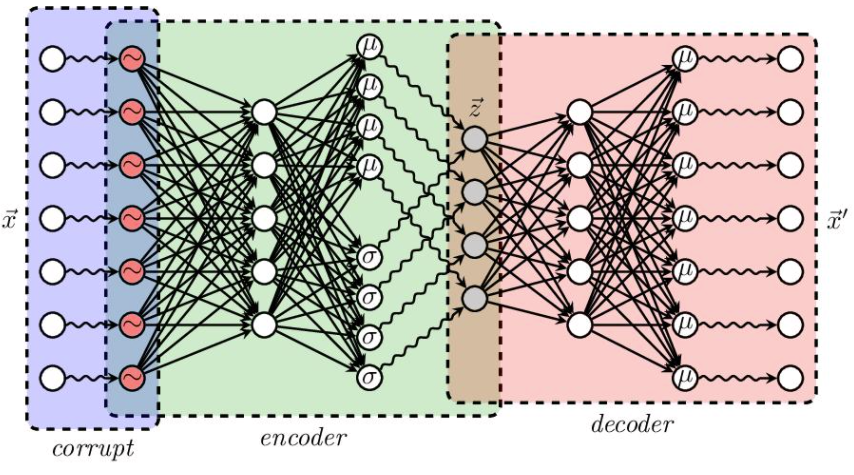
如上图所示,自编码器接受一个样本作为输入,经过推断网络(又称编码器)计算\(p(z|x)\),我们是用\(q(z|x)\)来近似\(p(z|x)\)的,而\(q(z|x)\)的参数是通过神经网络计算的,接着利用重参数化技巧采样一个样本\(z\),并利用\(p(x|z)\)重构出\(z\)对应的\(x\),而\(p(x|z)\)同样也是通过神经网络计算的,这个网络称为生成网络(也称解码器)。
代码实现
基于pytorch实现VAE,数据集选用MNIST手写数字图片。主要代码如下:
class MYVAE(nn.Module):
def __init__(self):
super().__init__()
self.encoder = nn.Sequential(
nn.Linear(HP.image_size, HP.h_dim),
nn.ReLU(),
nn.Linear(HP.h_dim, HP.z_dim * 2)
)
self.decoder = nn.Sequential(
nn.Linear(HP.z_dim, HP.h_dim),
nn.ReLU(),
nn.Linear(HP.h_dim, HP.image_size),
nn.Sigmoid()
)
def reparameterize(self, mu, logvar):
std = torch.exp(logvar)
eps = torch.randn_like(std)
return mu + std * eps
def forward(self, x):
param = self.encoder(x)
mu, logvar = torch.chunk(param, 2, dim=-1)
z = self.reparameterize(mu, logvar)
return self.decoder(z), mu, logvar
效果
以下两幅图是运行15个epoch的效果:



 浙公网安备 33010602011771号
浙公网安备 33010602011771号