

论文复现——AutoRec: Autoencoders Meet Collaborative Filtering
Posted on 2021-08-16 21:18 foghorn 阅读(207) 评论(0) 编辑 收藏 举报《AutoRec: Autoencoders Meet Collaborative Filtering》是2015年Suvash等人发表在“The Web Conference”会议上的一篇论文,作者提出用自编码器预测用户对电影的评分。论文比较短,只有两页,可以说是深度学习在推荐系统领域应用的开端。
ABSTRACT
本文提出了一个新颖的基于自编码器的协同过滤框架——AutoRec。实验表明,AutoRec在Movielens数据集上的表现优于目前最好的方法(矩阵分解、受限玻尔兹曼机、LLORMA)。
THE AUTOREC MODEL
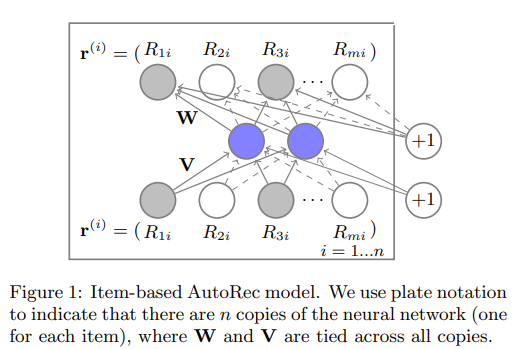
假设有\(m\)个用户,\(n\)个商品,并且有用户对商品的评分矩阵\(R\in \mathbb{R}^{m\times n}\),则用户\(u\)对所有商品的评分可以用不完全的向量\(r^{(u)}={R_{u1},...,R_{u2}}\)表示(不完全意思是,\(r^{(u)}\)中的元素有的是真实的评分数据,有的是需要我们预测的)。自编码器的作用就是将\(r^{(u)}\)作为输入数据,经过编码器将向量映射维一个低维的向量,然后通过解码器重构输出向量,使输出向量趋近于输入向量,同时能够补全原始输入向量中的缺失值。自编码器模型可以表示为:
\[min\sum_{r\in S}^{}\left \| r-h(r;\theta ) \right \|^{2}_{2}
\]
代码复现
完整代码及数据集已上传至github
import os
import torch
import numpy as np
import pandas as pd
import torch.nn as nn
import torch.utils.data as Data
import matplotlib.pyplot as plt
os.environ['KMP_DUPLICATE_LIB_OK'] = 'TRUE'
col_name = ["userid", "movieid", "rating", "timestrap"]
u1_base_path = "data/u1.base"
u1_base = pd.read_table(u1_base_path, sep='\t', header=None, names=col_name)
# print(u1_base.head(5))
u1_test_path = "data/u1.test"
u1_test = pd.read_table(u1_test_path, sep='\t', header=None, names=col_name)
# print(u1_test.head(5))
# 将数据转换为 user-item 交互矩阵
def TranslateData(data):
user_num = data.userid.nunique() # 用户的个数
movie_num = 1682 # 电影个数(数据中标明的所有电影数)
data_mat = np.zeros(user_num * movie_num).reshape((-1, movie_num)) + 3
k = 0
for i in range(data.shape[0]):
data_mat[k][data.iloc[i, 1] - 1] = data.iloc[i, 2]
if i > 0 and data.iloc[i, 0] != data.iloc[i - 1, 0]:
k += 1
return data_mat
class AutoRec(nn.Module):
def __init__(self, input_num, hidden_num):
super(AutoRec, self).__init__()
self.input_num = input_num
self.hidden_num = hidden_num
self.encoder = nn.Linear(self.input_num, self.hidden_num, bias=True)
self.relu = nn.ReLU()
self.decoder = nn.Linear(self.hidden_num, self.input_num, bias=True)
def forward(self, x):
hidden = self.encoder(x)
hidden = self.relu(hidden)
out = self.decoder(hidden)
return out
def GetData(data_mat):
dataset = Data.TensorDataset(torch.tensor(data_mat, dtype=torch.float32),
torch.zeros(data_mat.shape[0], 1).view(-1, 1))
loader = Data.DataLoader(
dataset=dataset,
batch_size=64,
shuffle=False
)
return loader
epochs = 100
input_num, hidden_num = 1682, 200
model = AutoRec(input_num, hidden_num)
learning_rate = 0.0003
optimizer = torch.optim.Adam([
{'params': (p for name, p in model.named_parameters() if 'bias' not in name)},
{'params': (p for name, p in model.named_parameters() if 'bias' in name), 'weight_decay': 0.}
], lr=learning_rate, weight_decay=0.001)
loss_func = torch.nn.MSELoss()
loss_train_set = []
loss_test_set = []
def run():
train()
draw(loss_train_set)
def train():
train_data_mat = TranslateData(u1_base)
r = train_data_mat[0]
train_loader = GetData(train_data_mat)
for epoch in range(epochs):
rmse_loss = 0
for step, (X, y) in enumerate(train_loader):
out = model(X)
rmse_loss = torch.sqrt(loss_func(out, X))
rmse_loss.backward()
optimizer.step()
loss_train_set.append(rmse_loss)
if epoch % 100 == 0:
print("epoch %d" % (epoch + 1))
test()
def test():
test_data_mat = TranslateData(u1_test)
test_loader = GetData(test_data_mat)
with torch.no_grad():
rmse_loss = 0
for step, (X, y) in enumerate(test_loader):
out = model(X)
rmse_loss += torch.sqrt(loss_func(out, X))
print("test_loss: %f" % (rmse_loss / test_data_mat.shape[0]))
def draw(loss_train_set):
x = [i for i in range(len(loss_train_set))]
plt.plot(x, loss_train_set, label="Training loss")
plt.xlabel("epochs")
plt.ylabel("rmse")
plt.legend()
plt.show()
if __name__ == "__main__":
run()

