
一步步带你找猫眼评论的接口4月14号
我之前看了一些关于抓包的文章,还以为猫眼的接口都要通过fiddler去抓包,但是我错了,fiddler出了点问题,后来用夜神模拟器去模拟手机,但是一直抓不到想要的包,于是又上网查,终于看到一篇文章说到开发者模式可以直接切换到手机模式
第一步:进入猫眼官网,找到一部电影,或者直接点开链接https://maoyan.com/films/248123
第二步:按下F12,使用开发者模式,然后重点来了!!!!
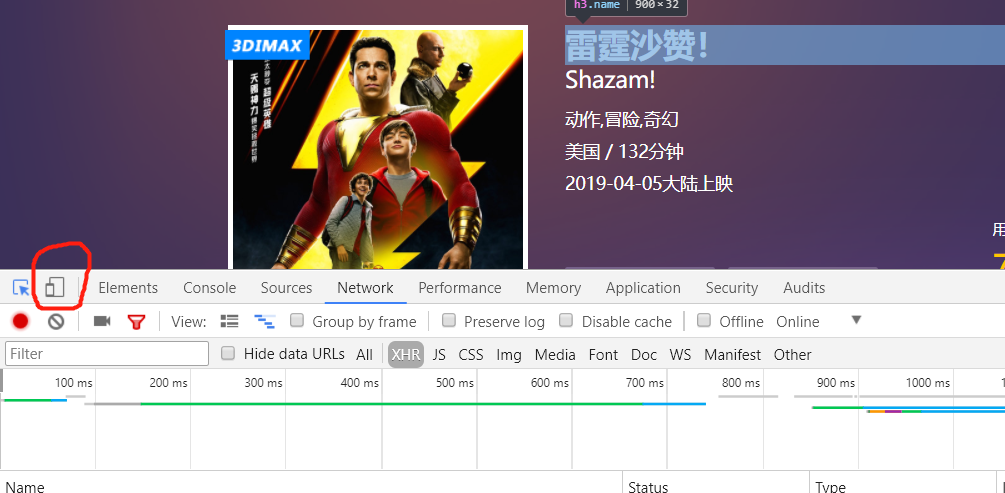
按下这个按钮,然后!!!必须再按F5刷新一次,然后就会变成手机模式,只有在手机上才会显示评论数的!!!
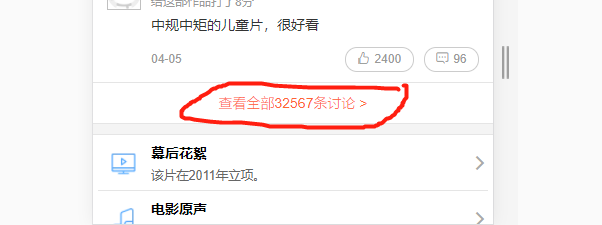
第三步:点击查看全部32567条评论,然后一直下滑查看评论,并且要点切换XHR,只看XHR格式文件,不然数据难找,最后找到comment.json,offset这个文件
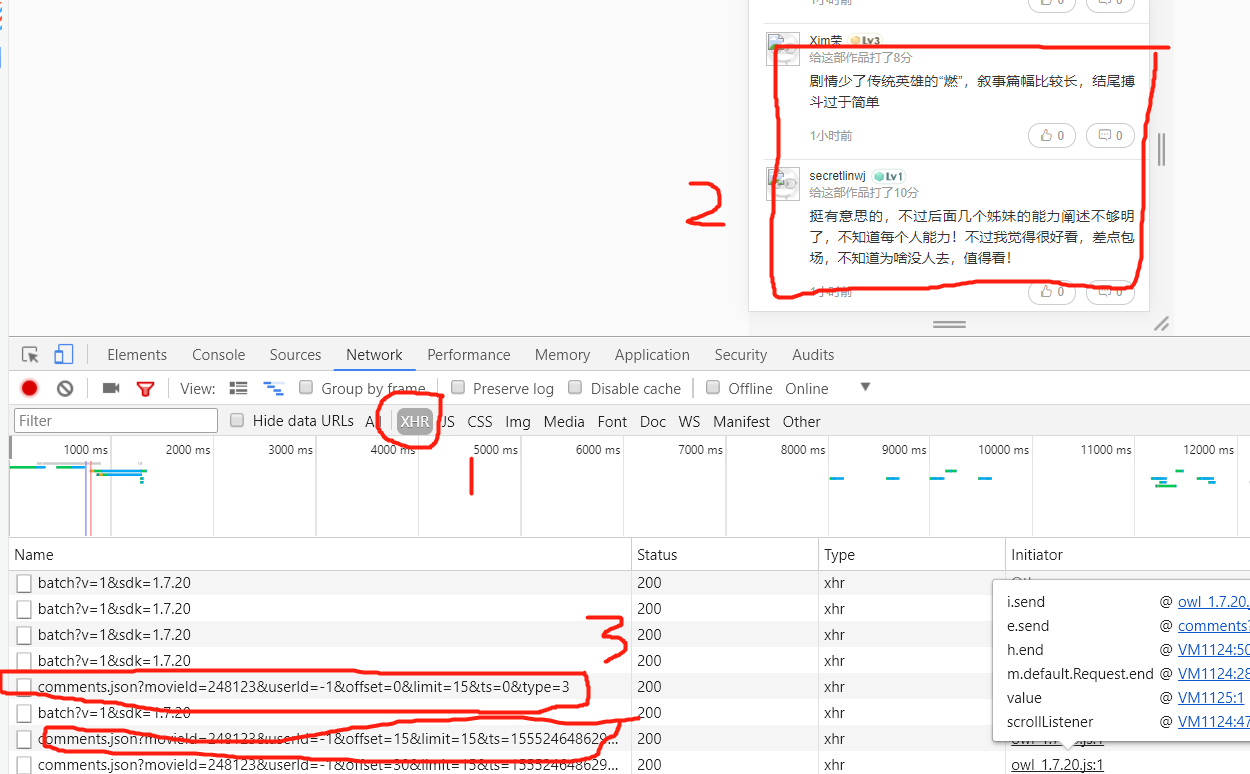
第四步:查看这个文件的headers,得到URL:http://m.maoyan.com/review/v2/comments.json?movieId=248123&userId=-1&offset=15&limit=15&ts=1555246486297&type=3
通过多次下滑观察可以看到每次都是offset在变化,而且每次加15,也就是增加15条评论
第五步:知道第四步的规律其实大家都应该会做了,但是还有个问题,这个方法只能爬取1000条数据,除非改变时间戳,也就是ts,
ts是对时间的一个表述形式,而我们点击上面的json文件,使用json解析,百度一下就知道json解析的网页了,解析后发现存在一个startTime
startTime也是对时间的一个表述,那么我们就打开这个网页:http://tool.chinaz.com/Tools/unixtime.aspx
把内容切换为北京时间,可以看到ts对应的是当前时间,于是我们尝试访问http://m.maoyan.com/review/v2/comments.json?movieId=248123&userId=-1&offset=15&limit=15&startTime=你的当前时间&type=3
但是要注意对时间进行转换,空格对应的是%20,冒号对应的是%3A
我们发现行得通,于是代码思路就来了!!
第六步:首先得到当前时间和电影上映时间,每次访问URL都获取json中最后一个数据的startTime,当遍历完前1000条数据后,更新URL,改变startTime为最后一条数据的URL,
知道startTime小于上映时间为止
最后就附上源码:
import requests
import time
import datetime
import random
from pymongo import MongoClient
mon_client=MongoClient() #使用mongodb数据库
mon_db=mon_client.home
mon_maoyan=mon_db.zhumeng #选定数据集合
ran_time=random.random() #随机休眠0-1浮点数秒
id=1003
now_time=datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S') #当前时间
end_time="2019-04-05 00:00:00" #上映时间,有些评论在上映时间之前,但是不要了
def startTime(time):
if time>end_time:#不转换为时间戳格式,因为时间戳格式的URL无法显示cmts部分评论
run(time)
def run(date):
global id # 定义为全局变量
global starttime
for i in range(67): #页号,一般只显示前1000条,67*15》1000
#要把时间里面的空格改为%20,否则URL不完整
url='http://m.maoyan.com/mmdb/comments/movie/248123.json?_v_=yes&offset={}&startTime={}'.format(i*15,date.replace(' ','%20'))
print(url)
headers = {
'Host': 'm.maoyan.com',
'Referer': 'http://m.maoyan.com/movie/248123/comments?_v_=yes',
'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Mobile Safari/537.36',
'X-Requested-With': 'superagent',
}
rsp=requests.get(url,headers=headers)
text=rsp.json()
try:
comments=text['cmts']
for i in comments:
id += 1 # 序号
data={
'id':id, #序号
'startTime':i['startTime'], # 开始时间
'cityName':i['cityName'], # 观众所在城市
'nickName':i['nickName'].replace('\n','').replace('\r','').replace('\t','').replace(',','').replace(',','').strip(), # 观众昵称
'score':i['score'], # 评分
'contents':i['content'].replace('\n','').replace('\r','').replace('\t','').strip(), # 内容
}
starttime=i['startTime'] #最后一条评论的时间
# print(data)
mon_maoyan.insert(data)
except: #可能有一天不足1000条评论
continue
time.sleep(ran_time)
startTime(starttime)
if __name__=='__main__':
run(now_time)


