Java【缓冲流、转换流、序列化流、打印流】学习笔记
【缓冲流、转换流、序列化流、打印流】
缓冲流
缓冲流,能够转换编码的转换流,能够持久化存储对象的序列化流等等。这些功能更为强大的流,都是在基本的流对象基础之上创建而来的,就像穿上铠甲的武士一样,相当于是对基本流对象的一种增强。
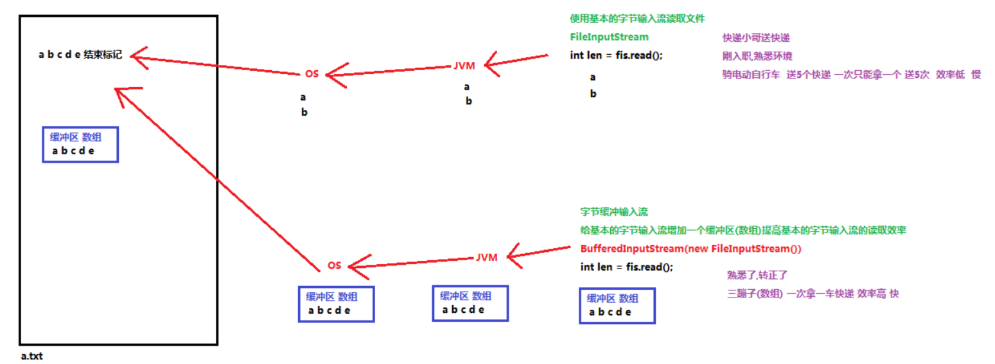
概述
缓冲流,也叫高效流,是对4个基本的FileXxx 流的增强,所以也是4个流,按照数据类型分类:
- 字节缓冲流:
BufferedInputStream,BufferedOutputStream - 字符缓冲流:
BufferedReader,BufferedWriter
缓冲流的基本原理,是在创建流对象时,会创建一个内置的默认大小的缓冲区数组,通过缓冲区读写,减少系统IO次数,从而提高读写的效率。
字节缓冲流
构造方法
public BufferedInputStream(InputStream in):创建一个 新的缓冲输入流。public BufferedOutputStream(OutputStream out): 创建一个新的缓冲输出流。
BufferedOutputStream
构造方法:
BufferedOutputStream(OutputStream out) 创建一个新的缓冲输出流,以将数据写入指定的底层输出流。
BufferedOutputStream(OutputStream out, int size) 创建一个新的缓冲输出流,以将具有指定缓冲区大小的数据写入指定的底层输出流。
参数:
OutputStream out:字节输出流
我们可以传递FileOutputStream,缓冲流会给FileOutputStream增加一个缓冲区,提高FileOutputStream的写入效率
int size:指定缓冲流内部缓冲区的大小,不指定默认
使用步骤(重点)
1.创建FileOutputStream对象,构造方法中绑定要输出的目的地
2.创建BufferedOutputStream对象,构造方法中传递FileOutputStream对象对象,提高FileOutputStream对象效率
3.使用BufferedOutputStream对象中的方法write,把数据写入到内部缓冲区中
4.使用BufferedOutputStream对象中的方法flush,把内部缓冲区中的数据,刷新到文件中
5.释放资源(会先调用flush方法刷新数据,第4部可以省略)
public class Demo01BufferedOutputStream {
public static void main(String[] args) throws IOException {
//1.创建FileOutputStream对象,构造方法中绑定要输出的目的地
FileOutputStream fos = new FileOutputStream("src\\10_IO\\a.txt");
//2.创建BufferedOutputStream对象,构造方法中传递FileOutputStream对象对象,提高FileOutputStream对象效率
BufferedOutputStream bos = new BufferedOutputStream(fos);
//3.使用BufferedOutputStream对象中的方法write,把数据写入到内部缓冲区中
bos.write("我把数据写入到内部缓冲区中2".getBytes());
//4.使用BufferedOutputStream对象中的方法flush,把内部缓冲区中的数据,刷新到文件中
bos.flush();
//5.释放资源(会先调用flush方法刷新数据,第4部可以省略)
bos.close();
}
}
BufferedInputStream
构造方法:
BufferedInputStream(InputStream in) 创建一个 BufferedInputStream 并保存其参数,即输入流 in,以便将来使用。
BufferedInputStream(InputStream in, int size) 创建具有指定缓冲区大小的 BufferedInputStream 并保存其参数,即输入流 in,以便将来使用。
参数:
InputStream in:字节输入流
我们可以传递FileInputStream,缓冲流会给FileInputStream增加一个缓冲区,提高FileInputStream的读取效率
int size:指定缓冲流内部缓冲区的大小,不指定默认
使用步骤(重点):
1.创建FileInputStream对象,构造方法中绑定要读取的数据源
2.创建BufferedInputStream对象,构造方法中传递FileInputStream对象,提高FileInputStream对象的读取效率
3.使用BufferedInputStream对象中的方法read,读取文件
4.释放资源
public class Demo02BufferedInputStream {
public static void main(String[] args) throws IOException {
//1.创建FileInputStream对象,构造方法中绑定要读取的数据源
FileInputStream fis = new FileInputStream("10_IO\\a.txt");
//2.创建BufferedInputStream对象,构造方法中传递FileInputStream对象,提高FileInputStream对象的读取效率
BufferedInputStream bis = new BufferedInputStream(fis);
//3.使用BufferedInputStream对象中的方法read,读取文件
//int read()从输入流中读取数据的下一个字节。
/*int len = 0;//记录每次读取到的字节
while((len = bis.read())!=-1){
System.out.println(len);
}*/
//int read(byte[] b) 从输入流中读取一定数量的字节,并将其存储在缓冲区数组 b 中。
byte[] bytes =new byte[1024];//存储每次读取的数据
int len = 0; //记录每次读取的有效字节个数
while((len = bis.read(bytes))!=-1){
System.out.println(new String(bytes,0,len));
}
//4.释放资源
bis.close();
}
}
效率测试
查询API,缓冲流读写方法与基本的流是一致的,我们通过复制大文件(375MB),测试它的效率。
- 基本流,代码如下:
public class BufferedDemo {
public static void main(String[] args) throws FileNotFoundException {
// 记录开始时间
long start = System.currentTimeMillis();
// 创建流对象
try (
FileInputStream fis = new FileInputStream("jdk9.exe");
FileOutputStream fos = new FileOutputStream("copy.exe")
){
// 读写数据
int b;
while ((b = fis.read()) != -1) {
fos.write(b);
}
} catch (IOException e) {
e.printStackTrace();
}
// 记录结束时间
long end = System.currentTimeMillis();
System.out.println("普通流复制时间:"+(end - start)+" 毫秒");
}
}
十几分钟过去了...
- 缓冲流,代码如下:
public class BufferedDemo {
public static void main(String[] args) throws FileNotFoundException {
// 记录开始时间
long start = System.currentTimeMillis();
// 创建流对象
try (
BufferedInputStream bis = new BufferedInputStream(new FileInputStream("jdk9.exe"));
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("copy.exe"));
){
// 读写数据
int b;
while ((b = bis.read()) != -1) {
bos.write(b);
}
} catch (IOException e) {
e.printStackTrace();
}
// 记录结束时间
long end = System.currentTimeMillis();
System.out.println("缓冲流复制时间:"+(end - start)+" 毫秒");
}
}
缓冲流复制时间:8016 毫秒
如何更快呢?
使用数组的方式,代码如下:
public class BufferedDemo {
public static void main(String[] args) throws FileNotFoundException {
// 记录开始时间
long start = System.currentTimeMillis();
// 创建流对象
try (
BufferedInputStream bis = new BufferedInputStream(new FileInputStream("jdk9.exe"));
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("copy.exe"));
){
// 读写数据
int len;
byte[] bytes = new byte[8*1024];
while ((len = bis.read(bytes)) != -1) {
bos.write(bytes, 0 , len);
}
} catch (IOException e) {
e.printStackTrace();
}
// 记录结束时间
long end = System.currentTimeMillis();
System.out.println("缓冲流使用数组复制时间:"+(end - start)+" 毫秒");
}
}
缓冲流使用数组复制时间:666 毫秒
字符缓冲流
构造方法
public BufferedReader(Reader in):创建一个 新的缓冲输入流。public BufferedWriter(Writer out): 创建一个新的缓冲输出流。
构造方法:
BufferedWriter(Writer out) 创建一个使用默认大小输出缓冲区的缓冲字符输出流。
BufferedWriter(Writer out, int sz) 创建一个使用给定大小输出缓冲区的新缓冲字符输出流。
参数:
Writer out:字符输出流
我们可以传递FileWriter,缓冲流会给FileWriter增加一个缓冲区,提高FileWriter的写入效率
int sz:指定缓冲区的大小,不写默认大小
特有的成员方法:
void newLine() 写入一个行分隔符。会根据不同的操作系统,获取不同的行分隔符
换行:换行符号
windows:\r\n
linux:/n
mac:/r
使用步骤:
1.创建字符缓冲输出流对象,构造方法中传递字符输出流
2.调用字符缓冲输出流中的方法write,把数据写入到内存缓冲区中
3.调用字符缓冲输出流中的方法flush,把内存缓冲区中的数据,刷新到文件中
4.释放资源
特有方法
字符缓冲流的基本方法与普通字符流调用方式一致,不再阐述,我们来看它们具备的特有方法。
- BufferedReader:
public String readLine(): 读一行文字。 - BufferedWriter:
public void newLine(): 写一行行分隔符,由系统属性定义符号。
readLine方法演示,代码如下:
public class BufferedReaderDemo {
public static void main(String[] args) throws IOException {
// 创建流对象
BufferedReader br = new BufferedReader(new FileReader("in.txt"));
// 定义字符串,保存读取的一行文字
String line = null;
// 循环读取,读取到最后返回null
while ((line = br.readLine())!=null) {
System.out.print(line);
System.out.println("------");
}
// 释放资源
br.close();
}
}
newLine方法演示,代码如下:
public class BufferedWriterDemo throws IOException {
public static void main(String[] args) throws IOException {
// 创建流对象
BufferedWriter bw = new BufferedWriter(new FileWriter("out.txt"));
// 写出数据
bw.write("我是");
// 写出换行
bw.newLine();
bw.write("程序");
bw.newLine();
bw.write("员");
bw.newLine();
// 释放资源
bw.close();
}
}
输出效果:
我是
程序
员
练习:文本排序
对文本的内容进行排序
按照(1,2,3. . . )顺序排序
3.侍中、侍郎郭攸之、费祎、董允等,此皆良实,志虑忠纯,是以先帝简拔以遗陛下。愚以为宫中之事,事无大小,悉以咨之,然后施行,必得裨补阙漏,有所广益。
8.愿陛下托臣以讨贼兴复之效,不效,则治臣之罪,以告先帝之灵。若无兴德之言,则责攸之、祎、允等之慢,以彰其咎;陛下亦宜自谋,以咨诹善道,察纳雅言,深追先帝遗诏,臣不胜受恩感激。
4.将军向宠,性行淑均,晓畅军事,试用之于昔日,先帝称之曰能,是以众议举宠为督。愚以为营中之事,悉以咨之,必能使行阵和睦,优劣得所。
2.宫中府中,俱为一体,陟罚臧否,不宜异同。若有作奸犯科及为忠善者,宜付有司论其刑赏,以昭陛下平明之理,不宜偏私,使内外异法也。
1.先帝创业未半而中道崩殂,今天下三分,益州疲弊,此诚危急存亡之秋也。然侍卫之臣不懈于内,忠志之士忘身于外者,盖追先帝之殊遇,欲报之于陛下也。诚宜开张圣听,以光先帝遗德,恢弘志士之气,不宜妄自菲薄,引喻失义,以塞忠谏之路也。
9.今当远离,临表涕零,不知所言。
6.臣本布衣,躬耕于南阳,苟全性命于乱世,不求闻达于诸侯。先帝不以臣卑鄙,猥自枉屈,三顾臣于草庐之中,咨臣以当世之事,由是感激,遂许先帝以驱驰。后值倾覆,受任于败军之际,奉命于危难之间,尔来二十有一年矣。
7.先帝知臣谨慎,故临崩寄臣以大事也。受命以来,夙夜忧叹,恐付托不效,以伤先帝之明,故五月渡泸,深入不毛。今南方已定,兵甲已足,当奖率三军,北定中原,庶竭驽钝,攘除奸凶,兴复汉室,还于旧都。此臣所以报先帝而忠陛下之职分也。至于斟酌损益,进尽忠言,则攸之、祎、允之任也。
5.亲贤臣,远小人,此先汉所以兴隆也;亲小人,远贤臣,此后汉所以倾颓也。先帝在时,每与臣论此事,未尝不叹息痛恨于桓、灵也。侍中、尚书、长史、参军,此悉贞良死节之臣,愿陛下亲之信之,则汉室之隆,可计日而待也。
案例分析
分析:
1、创建一个HashMap集合对象,可以:存储每行文本的序号(1,2,3,..);value:存储每行的文本
2、创建字符缓冲输入流对象,构造方法中绑定字符输入流
3、创建字符缓冲输出流对象,构造方法中绑定字符输出流
4、使用字符缓冲输入流中的方法readline,逐行读取文本
5、对读取到的文本进行切割,获取行中的序号和文本内容
6、把切割好的序号和文本的内容存储到HashMap集合中(key序号是有序的,会自动排序1,2,3,4..)
7、遍历HashMap集合,获取每一个键值对
8、把每一个键值对,拼接为一个文本行
9、把拼接好的文本,使用字符缓冲输出流中的方法write,写入到文件中
10、释放资源
案例实现
public class Demo05Test {
public static void main(String[] args) throws IOException {
//1.创建一个HashMap集合对象,可以:存储每行文本的序号(1,2,3,..);value:存储每行的文本
HashMap<String,String> map = new HashMap<>();
//2.创建字符缓冲输入流对象,构造方法中绑定字符输入流
BufferedReader br = new BufferedReader(new FileReader("src\\10_IO\\in.txt"));
//3.创建字符缓冲输出流对象,构造方法中绑定字符输出流
BufferedWriter bw = new BufferedWriter(new FileWriter("src\\10_IO\\out.txt"));
//4.使用字符缓冲输入流中的方法readline,逐行读取文本
String line;
while((line = br.readLine())!=null){
//5.对读取到的文本进行切割,获取行中的序号和文本内容
String[] arr = line.split("\\.");//两个反斜杠代表一个反斜杠,用于转义
//6.把切割好的序号和文本的内容存储到HashMap集合中(key序号是有序的,会自动排序1,2,3,4..)
map.put(arr[0],arr[1]);
}
//7.遍历HashMap集合,获取每一个键值对
for(String key : map.keySet()){
String value = map.get(key);
//8.把每一个键值对,拼接为一个文本行
line = key + "." + value;
//9.把拼接好的文本,使用字符缓冲输出流中的方法write,写入到文件中
bw.write(line);
bw.newLine();//写换行
}
//10.释放资源
bw.close();
br.close();
}
}
转换流
字符编码和字符集
字符编码
计算机中储存的信息都是用二进制数表示的,而我们在屏幕上看到的数字、英文、标点符号、汉字等字符是二进制数转换之后的结果。按照某种规则,将字符存储到计算机中,称为编码 。反之,将存储在计算机中的二进制数按照某种规则解析显示出来,称为解码 。比如说,按照A规则存储,同样按照A规则解析,那么就能显示正确的文本符号。反之,按照A规则存储,再按照B规则解析,就会导致乱码现象。
编码:字符(能看懂的)--字节(看不懂的)
解码:字节(看不懂的)-->字符(能看懂的)
-
字符编码
Character Encoding: 就是一套自然语言的字符与二进制数之间的对应规则。编码表:生活中文字和计算机中二进制的对应规则
字符集
- 字符集
Charset:也叫编码表。是一个系统支持的所有字符的集合,包括各国家文字、标点符号、图形符号、数字等。
计算机要准确的存储和识别各种字符集符号,需要进行字符编码,一套字符集必然至少有一套字符编码。常见字符集有ASCII字符集、GBK字符集、Unicode字符集等。
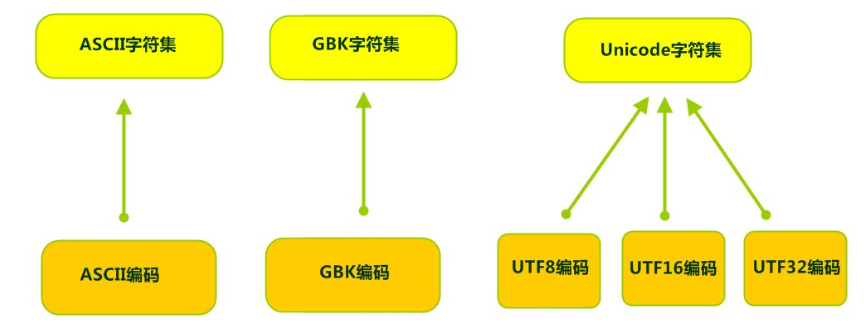
可见,当指定了编码,它所对应的字符集自然就指定了,所以编码才是我们最终要关心的。
- ASCII字符集 :
- ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统,用于显示现代英语,主要包括控制字符(回车键、退格、换行键等)和可显示字符(英文大小写字符、阿拉伯数字和西文符号)。
- 基本的ASCII字符集,使用7位(bits)表示一个字符,共128字符。ASCII的扩展字符集使用8位(bits)表示一个字符,共256字符,方便支持欧洲常用字符。
- ISO-8859-1字符集:
- 拉丁码表,别名Latin-1,用于显示欧洲使用的语言,包括荷兰、丹麦、德语、意大利语、西班牙语等。
- ISO-8859-1使用单字节编码,兼容ASCII编码。
- GBxxx字符集:
- GB就是国标的意思,是为了显示中文而设计的一套字符集。
- GB2312:简体中文码表。一个小于127的字符的意义与原来相同。但两个大于127的字符连在一起时,就表示一个汉字,这样大约可以组合了包含7000多个简体汉字,此外数学符号、罗马希腊的字母、日文的假名们都编进去了,连在ASCII里本来就有的数字、标点、字母都统统重新编了两个字节长的编码,这就是常说的"全角"字符,而原来在127号以下的那些就叫"半角"字符了。
- GBK:最常用的中文码表。是在GB2312标准基础上的扩展规范,使用了双字节编码方案,共收录了21003个汉字,完全兼容GB2312标准,同时支持繁体汉字以及日韩汉字等。
- GB18030:最新的中文码表。收录汉字70244个,采用多字节编码,每个字可以由1个、2个或4个字节组成。支持中国国内少数民族的文字,同时支持繁体汉字以及日韩汉字等。
- Unicode字符集 :
- Unicode编码系统为表达任意语言的任意字符而设计,是业界的一种标准,也称为统一码、标准万国码。
- 它最多使用4个字节的数字来表达每个字母、符号,或者文字。有三种编码方案,UTF-8、UTF-16和UTF-32。最为常用的UTF-8编码。
- UTF-8编码,可以用来表示Unicode标准中任何字符,它是电子邮件、网页及其他存储或传送文字的应用中,优先采用的编码。互联网工程工作小组(IETF)要求所有互联网协议都必须支持UTF-8编码。所以,我们开发Web应用,也要使用UTF-8编码。它使用一至四个字节为每个字符编码,编码规则:
- 128个US-ASCII字符,只需一个字节编码。
- 拉丁文等字符,需要二个字节编码。
- 大部分常用字(含中文),使用三个字节编码。
- 其他极少使用的Unicode辅助字符,使用四字节编码。
编码引出的问题

在IDEA中,使用FileReader 读取项目中的文本文件。由于IDEA的设置,都是默认的UTF-8编码,所以没有任何问题。但是,当读取Windows系统中创建的文本文件时,由于Windows系统的默认是GBK编码,就会出现乱码。
public class ReaderDemo {
public static void main(String[] args) throws IOException {
FileReader fileReader = new FileReader("E:\\File_GBK.txt");
int read;
while ((read = fileReader.read()) != -1) {
System.out.print((char)read);
}
fileReader.close();
}
}
输出结果:
���
那么如何读取GBK编码的文件呢?
InputStreamReader类
转换流java.io.InputStreamReader,是Reader的子类,是从字节流到字符流的桥梁。它读取字节,并使用指定的字符集将其解码为字符。它的字符集可以由名称指定,也可以接受平台的默认字符集。
构造方法
InputStreamReader(InputStream in): 创建一个使用默认字符集的字符流。InputStreamReader(InputStream in, String charsetName): 创建一个指定字符集的字符流。
java.io.InputStreamReader extends Reader
InputStreamReader:是字节流通向字符流的桥梁:它使用指定的 charset 读取字节并将其解码为字符。(解码:把看不懂的变成能看懂的)
继承自父类的共性成员方法:
int read() 读取单个字符并返回。
int read(char[] cbuf)一次读取多个字符,将字符读入数组。
void close() 关闭该流并释放与之关联的所有资源。
构造方法:
InputStreamReader(InputStream in) 创建一个使用默认字符集的 InputStreamReader。
InputStreamReader(InputStream in, String charsetName) 创建使用指定字符集的 InputStreamReader。
参数:
InputStream in:字节输入流,用来读取文件中保存的字节
String charsetName:指定的编码表名称,不区分大小写,可以是utf-8/UTF-8,gbk/GBK,...不指定默认使用UTF-8
使用步骤:
1.创建InputStreamReader对象,构造方法中传递字节输入流和指定的编码表名称
2.使用InputStreamReader对象中的方法read读取文件
3.释放资源
注意事项:
构造方法中指定的编码表名称要和文件的编码相同,否则会发生乱码
构造举例,代码如下:
InputStreamReader isr = new InputStreamReader(new FileInputStream("in.txt"));
InputStreamReader isr2 = new InputStreamReader(new FileInputStream("in.txt") , "GBK");
指定编码读取
public class ReaderDemo2 {
public static void main(String[] args) throws IOException {
// 定义文件路径,文件为gbk编码
String FileName = "E:\\file_gbk.txt";
// 创建流对象,默认UTF8编码
InputStreamReader isr = new InputStreamReader(new FileInputStream(FileName));
// 创建流对象,指定GBK编码
InputStreamReader isr2 = new InputStreamReader(new FileInputStream(FileName) , "GBK");
// 定义变量,保存字符
int read;
// 使用默认编码字符流读取,乱码
while ((read = isr.read()) != -1) {
System.out.print((char)read); // ��Һ�
}
isr.close();
// 使用指定编码字符流读取,正常解析
while ((read = isr2.read()) != -1) {
System.out.print((char)read);// 大家好
}
isr2.close();
}
}
OutputStreamWriter类
转换流java.io.OutputStreamWriter ,是Writer的子类,是从字符流到字节流的桥梁。使用指定的字符集将字符编码为字节。它的字符集可以由名称指定,也可以接受平台的默认字符集。
构造方法
OutputStreamWriter(OutputStream in): 创建一个使用默认字符集的字符流。OutputStreamWriter(OutputStream in, String charsetName): 创建一个指定字符集的字符流。
构造方法:
OutputStreamWriter(OutputStream out)创建使用默认字符编码的 OutputStreamWriter。
OutputStreamWriter(OutputStream out, String charsetName) 创建使用指定字符集的 OutputStreamWriter。
参数:
OutputStream out:字节输出流,可以用来写转换之后的字节到文件中
String charsetName:指定的编码表名称,不区分大小写,可以是utf-8/UTF-8,gbk/GBK,...不指定默认使用UTF-8
使用步骤:
1.创建OutputStreamWriter对象,构造方法中传递字节输出流和指定的编码表名称
2.使用OutputStreamWriter对象中的方法write,把字符转换为字节存储缓冲区中(编码)
3.使用OutputStreamWriter对象中的方法flush,把内存缓冲区中的字节刷新到文件中(使用字节流写字节的过程)
4.释放资源
构造举例,代码如下:
OutputStreamWriter isr = new OutputStreamWriter(new FileOutputStream("out.txt"));
OutputStreamWriter isr2 = new OutputStreamWriter(new FileOutputStream("out.txt") , "GBK");
指定编码写出
public class OutputDemo {
public static void main(String[] args) throws IOException {
// 定义文件路径
String FileName = "E:\\out.txt";
// 创建流对象,默认UTF8编码
OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream(FileName));
// 写出数据
osw.write("你好"); // 保存为6个字节
osw.close();
// 定义文件路径
String FileName2 = "E:\\out2.txt";
// 创建流对象,指定GBK编码
OutputStreamWriter osw2 = new OutputStreamWriter(new FileOutputStream(FileName2),"GBK");
// 写出数据
osw2.write("你好");// 保存为4个字节
osw2.close();
}
}
转换流理解图解
转换流是字节与字符间的桥梁!

练习:转换文件编码
将GBK编码的文本文件,转换为UTF-8编码的文本文件。
案例分析
- 指定GBK编码的转换流,读取文本文件。
- 使用UTF-8编码的转换流,写出文本文件。
案例实现
public class TransDemo {
public static void main(String[] args) {
// 1.定义文件路径
String srcFile = "file_gbk.txt";
String destFile = "file_utf8.txt";
// 2.创建流对象
// 2.1 转换输入流,指定GBK编码
InputStreamReader isr = new InputStreamReader(new FileInputStream(srcFile) , "GBK");
// 2.2 转换输出流,默认utf8编码
OutputStreamWriter osw = new OutputStreamWriter(new FileOutputStream(destFile));
// 3.读写数据
// 3.1 定义数组
char[] cbuf = new char[1024];
// 3.2 定义长度
int len;
// 3.3 循环读取
while ((len = isr.read(cbuf))!=-1) {
// 循环写出
osw.write(cbuf,0,len);
}
// 4.释放资源
osw.close();
isr.close();
}
}
序列化
概述
Java 提供了一种对象序列化的机制。用一个字节序列可以表示一个对象,该字节序列包含该对象的数据、对象的类型和对象中存储的属性等信息。字节序列写出到文件之后,相当于文件中持久保存了一个对象的信息。
反之,该字节序列还可以从文件中读取回来,重构对象,对它进行反序列化。对象的数据、对象的类型和对象中存储的数据信息,都可以用来在内存中创建对象。看图理解序列化:
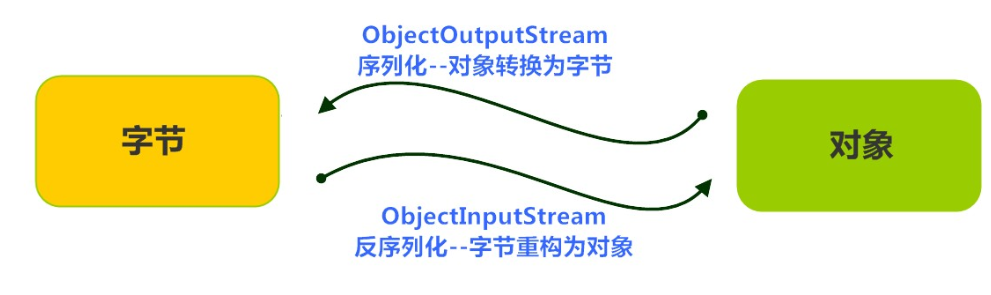
ObjectOutputStream类
java.io.ObjectOutputStream 类,将Java对象的原始数据类型写出到文件,实现对象的持久存储。
构造方法
public ObjectOutputStream(OutputStream out): 创建一个指定OutputStream的ObjectOutputStream。
java.io.ObjectOutputStream extends OutputStream
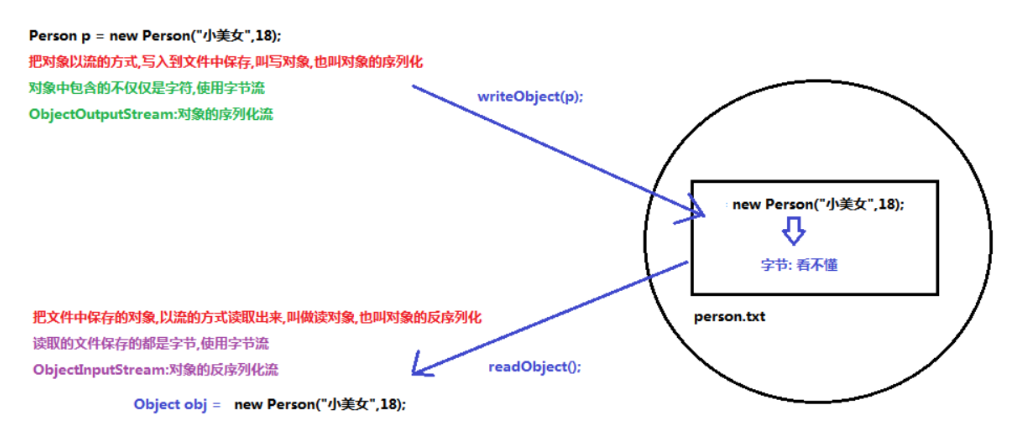
ObjectOutputStream:对象的序列化流
作用:把对象以流的方式写入到文件中保存
构造方法:
ObjectOutputStream(OutputStream out) 创建写入指定 OutputStream 的 ObjectOutputStream。
参数:
OutputStream out:字节输出流
特有的成员方法:
void writeObject(Object obj) 将指定的对象写入 ObjectOutputStream。
使用步骤:
1.创建ObjectOutputStream对象,构造方法中传递字节输出流
2.使用ObjectOutputStream对象中的方法writeObject,把对象写入到文件中
3.释放资源
构造举例,代码如下:
FileOutputStream fileOut = new FileOutputStream("employee.txt");
ObjectOutputStream out = new ObjectOutputStream(fileOut);
序列化操作
- 一个对象要想序列化,必须满足两个条件:
- 该类必须实现
java.io.Serializable接口,Serializable是一个标记接口,不实现此接口的类将不会使任何状态序列化或反序列化,会抛出NotSerializableException。 - 该类的所有属性必须是可序列化的。如果有一个属性不需要可序列化的,则该属性必须注明是瞬态的,使用
transient关键字修饰。
public class Employee implements java.io.Serializable {
public String name;
public String address;
public transient int age; // transient瞬态修饰成员,不会被序列化
public void addressCheck() {
System.out.println("Address check : " + name + " -- " + address);
}
}
2.写出对象方法
public final void writeObject (Object obj): 将指定的对象写出。
public class SerializeDemo{
public static void main(String [] args) {
Employee e = new Employee();
e.name = "zhangsan";
e.address = "beiqinglu";
e.age = 20;
try {
// 创建序列化流对象
ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream("employee.txt"));
// 写出对象
out.writeObject(e);
// 释放资源
out.close();
fileOut.close();
System.out.println("Serialized data is saved"); // 姓名,地址被序列化,年龄没有被序列化。
} catch(IOException i) {
i.printStackTrace();
}
}
}
输出结果:
Serialized data is saved
ObjectInputStream类
ObjectInputStream反序列化流,将之前使用ObjectOutputStream序列化的原始数据恢复为对象。
构造方法
public ObjectInputStream(InputStream in): 创建一个指定InputStream的ObjectInputStream。
java.io.ObjectInputStream extends InputStream
ObjectInputStream:对象的反序列化流
作用:把文件中保存的对象,以流的方式读取出来使用
构造方法:
ObjectInputStream(InputStream in) 创建从指定 InputStream 读取的 ObjectInputStream。
参数:
InputStream in:字节输入流
特有的成员方法:
Object readObject() 从 ObjectInputStream 读取对象。
使用步骤:
1.创建ObjectInputStream对象,构造方法中传递字节输入流
2.使用ObjectInputStream对象中的方法readObject读取保存对象的文件
3.释放资源
4.使用读取出来的对象(打印)
readObject方法声明抛出了ClassNotFoundException(class文件找不到异常)
当不存在对象的class文件时抛出此异常
反序列化的前提:
1.类必须实现Serializable
2.必须存在类对应的class文件
反序列化操作1
如果能找到一个对象的class文件,我们可以进行反序列化操作,调用ObjectInputStream读取对象的方法:
public final Object readObject (): 读取一个对象。
public class DeserializeDemo {
public static void main(String [] args) {
Employee e = null;
try {
// 创建反序列化流
FileInputStream fileIn = new FileInputStream("employee.txt");
ObjectInputStream in = new ObjectInputStream(fileIn);
// 读取一个对象
e = (Employee) in.readObject();
// 释放资源
in.close();
fileIn.close();
}catch(IOException i) {
// 捕获其他异常
i.printStackTrace();
return;
}catch(ClassNotFoundException c) {
// 捕获类找不到异常
System.out.println("Employee class not found");
c.printStackTrace();
return;
}
// 无异常,直接打印输出
System.out.println("Name: " + e.name); // zhangsan
System.out.println("Address: " + e.address); // beiqinglu
System.out.println("age: " + e.age); // 0
}
}
对于JVM可以反序列化对象,它必须是能够找到class文件的类。如果找不到该类的class文件,则抛出一个 ClassNotFoundException 异常。
反序列化操作2
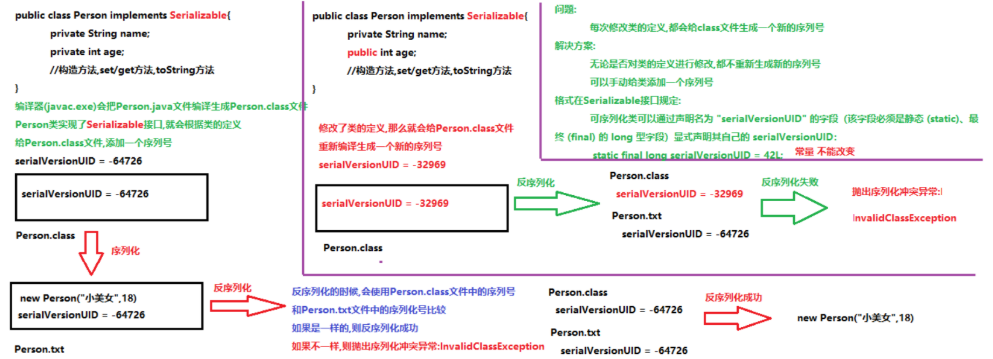
另外,当JVM反序列化对象时,能找到class文件,但是class文件在序列化对象之后发生了修改,那么反序列化操作也会失败,抛出一个InvalidClassException异常。发生这个异常的原因如下:
- 该类的序列版本号与从流中读取的类描述符的版本号不匹配
- 该类包含未知数据类型
- 该类没有可访问的无参数构造方法
Serializable 接口给需要序列化的类,提供了一个序列版本号。serialVersionUID 该版本号的目的在于验证序列化的对象和对应类是否版本匹配。
public class Employee implements java.io.Serializable {
// 加入序列版本号
private static final long serialVersionUID = 1L;
public String name;
public String address;
// 添加新的属性 ,重新编译, 可以反序列化,该属性赋为默认值.
public int eid;
public void addressCheck() {
System.out.println("Address check : " + name + " -- " + address);
}
}
练习:序列化集合
- 将存有多个自定义对象的集合序列化操作,保存到
list.txt文件中。 - 反序列化
list.txt,并遍历集合,打印对象信息。
案例分析
- 把若干学生对象 ,保存到集合中。
- 把集合序列化。
- 反序列化读取时,只需要读取一次,转换为集合类型。
- 遍历集合,可以打印所有的学生信息
案例实现
public class SerTest {
public static void main(String[] args) throws Exception {
// 创建 学生对象
Student student = new Student("老王", "laow");
Student student2 = new Student("老张", "laoz");
Student student3 = new Student("老李", "laol");
ArrayList<Student> arrayList = new ArrayList<>();
arrayList.add(student);
arrayList.add(student2);
arrayList.add(student3);
// 序列化操作
// serializ(arrayList);
// 反序列化
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("list.txt"));
// 读取对象,强转为ArrayList类型
ArrayList<Student> list = (ArrayList<Student>)ois.readObject();
for (int i = 0; i < list.size(); i++ ){
Student s = list.get(i);
System.out.println(s.getName()+"--"+ s.getPwd());
}
}
private static void serializ(ArrayList<Student> arrayList) throws Exception {
// 创建 序列化流
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("list.txt"));
// 写出对象
oos.writeObject(arrayList);
// 释放资源
oos.close();
}
}
打印流
概述
平时我们在控制台打印输出,是调用print方法和println方法完成的,这两个方法都来自于java.io.PrintStream类,该类能够方便地打印各种数据类型的值,是一种便捷的输出方式。
PrintStream类
构造方法
public PrintStream(String fileName): 使用指定的文件名创建一个新的打印流。
java.io.PrintStream:打印流
PrintStream 为其他输出流添加了功能,使它们能够方便地打印各种数据值表示形式。
PrintStream特点:
1.只负责数据的输出,不负责数据的读取
2.与其他输出流不同,PrintStream 永远不会抛出 IOException
3.有特有的方法,print,println
void print(任意类型的值)
void println(任意类型的值并换行)
构造方法:
PrintStream(File file):输出的目的地是一个文件
PrintStream(OutputStream out):输出的目的地是一个字节输出流
PrintStream(String fileName) :输出的目的地是一个文件路径
PrintStream extends OutputStream
继承自父类的成员方法:
- public void close() :关闭此输出流并释放与此流相关联的任何系统资源。
- public void flush() :刷新此输出流并强制任何缓冲的输出字节被写出。
- public void write(byte[] b):将 b.length字节从指定的字节数组写入此输出流。
- public void write(byte[] b, int off, int len) :从指定的字节数组写入 len字节,从偏移量 off开始输出到此输出流。
- public abstract void write(int b) :将指定的字节输出流。
注意:
如果使用继承自父类的write方法写数据,那么查看数据的时候会查询编码表 97->a
如果使用自己特有的方法print/println方法写数据,写的数据原样输出 97->97
- public void flush() :刷新此输出流并强制任何缓冲的输出字节被写出。
public class Demo01PrintStream {
public static void main(String[] args) throws FileNotFoundException {
//System.out.println("HelloWorld");
//创建打印流PrintStream对象,构造方法中绑定要输出的目的地
PrintStream ps = new PrintStream("10_IO\\print.txt");
//如果使用继承自父类的write方法写数据,那么查看数据的时候会查询编码表 97->a
ps.write(97);
//如果使用自己特有的方法print/println方法写数据,写的数据原样输出 97->97
ps.println(97);
ps.println(8.8);
ps.println('a');
ps.println("HelloWorld");
ps.println(true);
//释放资源
ps.close();
}
}
改变打印流向
System.out就是PrintStream类型的,只不过它的流向是系统规定的,打印在控制台上。不过,既然是流对象,我们就可以玩一个"小把戏",改变它的流向。
/*
可以改变输出语句的目的地(打印流的流向)
输出语句,默认在控制台输出
使用System.setOut方法改变输出语句的目的地改为参数中传递的打印流的目的地
static void setOut(PrintStream out)
重新分配“标准”输出流。
*/
public class Demo02PrintStream {
public static void main(String[] args) throws FileNotFoundException {
System.out.println("我是在控制台输出");
PrintStream ps = new PrintStream("10_IO\\目的地是打印流.txt");
System.setOut(ps);//把输出语句的目的地改变为打印流的目的地
System.out.println("我在打印流的目的地中输出");
ps.close();
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号