使用vmware+Ubuntu搭建hadoop集群
阅读须知
本文旨在使用Vmware搭建Hadoop集群,如果你使用的是多台独立的、已安装linux操作系统的计算机搭建Hadoop集群的话,请直接从安装Hadoop 开始,否则,我建议你按照安装Vmware并创建Ubuntu虚拟机 创建虚拟机并安装ubuntu系统。文中假设的运行环境为:Ubuntu 18.04 Desktop,账户密码都为hadoop,如果你已创建虚拟机,请根据你的设置修改自行修改我文中的相关内容。
下文中所有列出的指令建议逐句执行,以免发生错误!!!
下文中所有列出的指令建议逐句执行,以免发生错误!!!
下文中所有列出的指令建议逐句执行,以免发生错误!!!
如果你使用的是Vmware虚拟机,建议你在完成每种模式的搭建后第一时间使用快照备份,以给留自己一条后路。
本文选用的软件版本如下:
-
Ubuntu 18.04 Desktop
-
Hadoop-3.2.1
-
OpenJdk-8
Hadoop三种运行模式的区别
非分布式模式/本地模式
该模式为Hadoop的默认模式,一旦你安装了Hadoop,在没有进行相关配置前,Hadoop运行的是本地模式,该模式下,Hadoop使用的是本地文件系统而不是分布式文件系统,且不会启动NameNode、DataNode、JobTracker、TaskTracker等守护进程。该模式用于对MapReduce程序的验证。
伪分布式模式
即Hadoop假装自己在全分布式模式下,与全分布式模式下Hadoop的守护进程在不同主机上运行不同,此时Hadoop的守护进程都在一台主机上运行。此时,Hadoop进程以分离的Java进程来运行,节点及作为NameNode也作为DataNode,同时,读取的是HDFS中的文件。
全分布式模式
Hadoop运行在多台主机(一个集群)中,每台主机都安装了OpenJDK和Hadoop,节点之间通过SSH进行联系。其中,一个节点作为主节点,其他节点要在主节点中注册才能加入集群。
Java运行环境的选择
由于Hadoop是运行在Java环境下的,所以如果Java运行环境版本与Hadoop版本不兼容,Hadoop会无法运行或者在运行的时候会产生问题,以下表格来自Hadoop的官方文档HadoopJavaVersions,你在选择jdk版本的时候充分考虑此表。
| Version | Status | Reported By |
|---|---|---|
| oracle 1.7.0_15 | Good | Cloudera |
| oracle 1.7.0_21 | Good (4) | Hortonworks |
| oracle 1.7.0_45 | Good | Pivotal |
| openjdk 1.7.0_09-icedtea | Good (5) | Hortonworks |
| oracle 1.6.0_16 | Avoid (1) | Cloudera |
| oracle 1.6.0_18 | Avoid | Many |
| oracle 1.6.0_19 | Avoid | Many |
| oracle 1.6.0_20 | Good (2) | LinkedIn, Cloudera |
| oracle 1.6.0_21 | Good (2) | Yahoo!, Cloudera |
| oracle 1.6.0_24 | Good | Cloudera |
| oracle 1.6.0_26 | Good(2) | Hortonworks, Cloudera |
| oracle 1.6.0_28 | Good | |
| oracle 1.6.0_31 | Good(3, 4) | Cloudera, Hortonworks |
创建Hadoop用户
创建一个名为hadoop的用户以进行hadoop安装。
即使你不愿意创建hadoop用户,我也强烈建议你不要使用root用户来搭建hadoop环境,因为这可能带来安全问题。
sudo addgroup hadoop
sudo adduser --ingroup hadoop hadoop
Adding user
hadoop' ... Adding new userhadoop' (1000) with grouphadoop' ... Creating home directory/home/hadoop' ...
Copying files from `/etc/skel' ...
Enter new UNIX password:
Retype new UNIX password:
passwd: password updated successfully
Changing the user information for hadoop
Enter the new value, or press ENTER for the default
Full Name []:
Room Number []:
Work Phone []:
Home Phone []:
Other []:
Is the information correct? [Y/n]
安装Hadoop
执行以下指令以安装hadoop,openjdk并配置Hadoop,在执行之前,在终端输入sudo -i并输入密码,以root身份运行以下指令。
cd /home/hadoop
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.2.1/hadoop-3.2.1.tar.gz # 下载hadoop安装包
tar -zxf hadoop-3.2.1.tar.gz # 解压hadoop安装包
mv ./hadoop-3.2.1 /usr/local/
cd /usr/local
mv ./hadoop-3.2.1 hadoop
chown -R hadoop:hadoop ./hadoop # 更新文件夹所有者
cd hadoop/
apt-get update
apt-get install -y openjdk-8-jdk openjdk-8-jre # 安装openjdk
# 为hadoop指定JAVA_HOME
# sed -i "s?export\ JAVA_HOME=\${JAVA_HOME}?export\ JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64/?g" ./etc/hadoop/hadoop-env.sh # 用于hadoop2
echo "JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/" >> ./etc/hadoop/hadoop-env.sh
echo "export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/" >> /etc/bash.bashrc # 将JAVA_HOME写入环境变量
# 将hadoop写入环境变量
echo "export HADOOP_HOME=/usr/local/hadoop" >> /etc/bash.bashrc
echo "export PATH=\$HADOOP_HOME/bin:\$HADOOP_HOME/sbin:\$PATH" >> /etc/bash.bashrc
echo "export HADOOP_CONF_DIR=\$HADOOP_HOME/etc/hadoop" >> /etc/bash.bashrc
source /etc/bash.bashrc
运行过程中你可以去泡杯茶喝,因为这个过程需要下载Hadoop和OpenJDK,会占用比较多的时间,下载速度取决于你的网络。
关闭现有的终端,新开一个终端(目的是刷新环境变量),执行hadoop version。如果你的终端最后显示的内容类似如下,说明已经完成Hadoop的默认模式(非分布式模式/本地模式)的安装。
Hadoop 3.2.1 Source code repository https://gitbox.apache.org/repos/asf/hadoop.git -r b3cbbb467e22ea829b3808f4b7b01d07e0bf3842 Compiled by rohithsharmaks on 2019-09-10T15:56Z Compiled with protoc 2.5.0 From source with checksum 776eaf9eee9c0ffc370bcbc1888737 This command was run using /usr/local/hadoop/share/hadoop/common/hadoop-common-3.2.1.jar
以单机模式运行
运行自带的mapreduce示例以检验单机模式可以正常运行。
cd /usr/local/hadoop
mkdir input
cp etc/hadoop/*.xml input
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep input output 'dfs[a-z.]+'
cat output/*
结果显示1 dfsadmin则你的hadoop已经正常完成单机mapreduce任务。
安装openssh-server
Hadoop要用到ssh进行通讯,所以要安装ssh的服务端,以允许外部主机通过ssh远程连接到本地主机。执行以下指令以安装ssh服务端:
sudo apt-get install openssh-server -y
如果你此时是通过ssh连接到主机的,很显然你是不需要进行这一步的。
配置伪分布式模式
修改配置文件
Hadoop的配置文件位于/usr/local/hadoop/etc/hadoop/,完成配置伪分布式需要修改配置文件:core-site.xml、hdfs-site.xml。
如果你懒得修改文件,你可以使用以下指令直接使用我的配置文件:
cd /usr/local/hadoop/etc/hadoop
rm core-site.xml
rm hdfs-site.xml
wget https://gitee.com/focksor/hadoop-config/raw/master/Pseudo-Distributed/core-site.xml
wget https://gitee.com/focksor/hadoop-config/raw/master/Pseudo-Distributed/hdfs-site.xml
或者,你也可以手动修改:
- 将
core-site.xml内容修改为:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>更改临时目录以防止系统自动清空临时目录内的hadoop相关内容</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
- 将
hdfs-site.xml内容修改为:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
<description>数据块的副本数,在一台机器存放多副本是没有意义的</description>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
<description>本地磁盘用于存放fsimage文件的目录</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
<description>本地磁盘用于存放HDFS的block的目录</description>
</property>
</configuration>
设置ssh免登录
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
上述命令会在
~/.ssh/目录下生成ssh的公钥和私钥并将本机的公钥追加~/.ssh/authorized_keys内。
如果正确完成,你可以执行以下指令以无密码的方式ssh连接到本机
ssh localhost
如果你第一次运行该指令,终端会提示你:
Are you sure you want to continue connecting (yes/no)?
应输入yes后回车。
以伪分布式运行Hadoop
以下指令会在本地运行一个MapReduce工作,如果你想用YARN来运行工作,可以参照YARN on Single Node。
cd /usr/local/hadoop/
bin/hdfs namenode -format # 格式化文件系统
sbin/start-dfs.sh # 启动NameNode和DataNode实例
该步骤不会要求你输入密码,如果该步有让你输入密码,你应该返回上一节设置ssh免登录并确定你是否已正确完成。
正确的输出结果应类似如下:
hadoop@ubuntu:/usr/local/hadoop$ sbin/start-dfs.sh Starting namenodes on [localhost] Starting datanodes Starting secondary namenodes [ubuntu] ubuntu: Warning: Permanently added 'ubuntu' (ECDSA) to the list of known hosts.如果你的输出如下,表示你的jdk版本兼容性有问题(笔者在使用openjdk-11+hadoop-2.10.0进行测试的时候出现以下问题),请参考Java运行环境的选择做出合理的调整,当然,由于出现的是
WARNING,你可以无视,但是会出现什么问题不好说。hadoop@ubuntu:/usr/local/hadoop$ sbin/start-dfs.sh WARNING: An illegal reflective access operation has occurred WARNING: Illegal reflective access by org.apache.hadoop.security.authentication.util.KerberosUtil (file:/usr/local/hadoop/share/hadoop/common/lib/hadoop-auth-2.10.0.jar) to method sun.security.krb5.Config.getInstance() WARNING: Please consider reporting this to the maintainers of org.apache.hadoop.security.authentication.util.KerberosUtil WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations WARNING: All illegal access operations will be denied in a future release Incorrect configuration: namenode address dfs.namenode.servicerpc-address or dfs.namenode.rpc-address is not configured. Starting namenodes on [] localhost: starting namenode, logging to /usr/local/hadoop/logs/hadoop-hadoop-namenode-ubuntu.out localhost: starting datanode, logging to /usr/local/hadoop/logs/hadoop-hadoop-datanode-ubuntu.out Starting secondary namenodes [0.0.0.0] The authenticity of host '0.0.0.0 (0.0.0.0)' can't be established. ECDSA key fingerprint is SHA256:wFCc7FRsvL5nFsKgn2BLwS3sQBmjnWJkACM7wsWbvuk. Are you sure you want to continue connecting (yes/no)? yes 0.0.0.0: Warning: Permanently added '0.0.0.0' (ECDSA) to the list of known hosts. 0.0.0.0: starting secondarynamenode, logging to /usr/local/hadoop/logs/hadoop-hadoop-secondarynamenode-ubuntu.out WARNING: An illegal reflective access operation has occurred WARNING: Illegal reflective access by org.apache.hadoop.security.authentication.util.KerberosUtil (file:/usr/local/hadoop/share/hadoop/common/lib/hadoop-auth-2.10.0.jar) to method sun.security.krb5.Config.getInstance() WARNING: Please consider reporting this to the maintainers of org.apache.hadoop.security.authentication.util.KerberosUtil WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations WARNING: All illegal access operations will be denied in a future release如果你的输出如下:说明你使用了root账户进行操作,此时需要使用指令
su hadoop切换到hadoop账户再进行上述操作。Starting namenodes on [localhost] ERROR: Attempting to operate on hdfs namenode as root ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation. Starting datanodes ERROR: Attempting to operate on hdfs datanode as root ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation. Starting secondary namenodes [aliYun-focksor] ERROR: Attempting to operate on hdfs secondarynamenode as root ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation.如果你的输出类似如下,说明你没有设置ssh免登录或者进行该操作时使用的不是hadoop账户,此时你需要使用hadoop账户再进行一次该操作。
Starting namenodes on [localhost] localhost: Warning: Permanently added 'localhost' (ECDSA) to the list of known hosts. localhost: hadoop@localhost: Permission denied (publickey,password). Starting datanodes localhost: hadoop@localhost: Permission denied (publickey,password). Starting secondary namenodes [focksor] focksor: Warning: Permanently added 'focksor,192.168.232.156' (ECDSA) to the list of known hosts. focksor: hadoop@focksor: Permission denied (publickey,password).
访问管理页面
完成上述步骤后使用ubuntu虚拟机自带的网络浏览器firefox访问以下地址以查看NameNode信息:
http://localhost:9870/
如果你安装的是没有GUI界面的操作系统,你可以通过以下方式访问管理页面:
- 在真实系统的浏览器访问如下虚拟机的ip地址+端口号:
http://192.168.232.131:9870/
如果你未知你的虚拟机的ip地址,可以参照Ubuntu18.04查看ip地址。
管理界面如下图所示
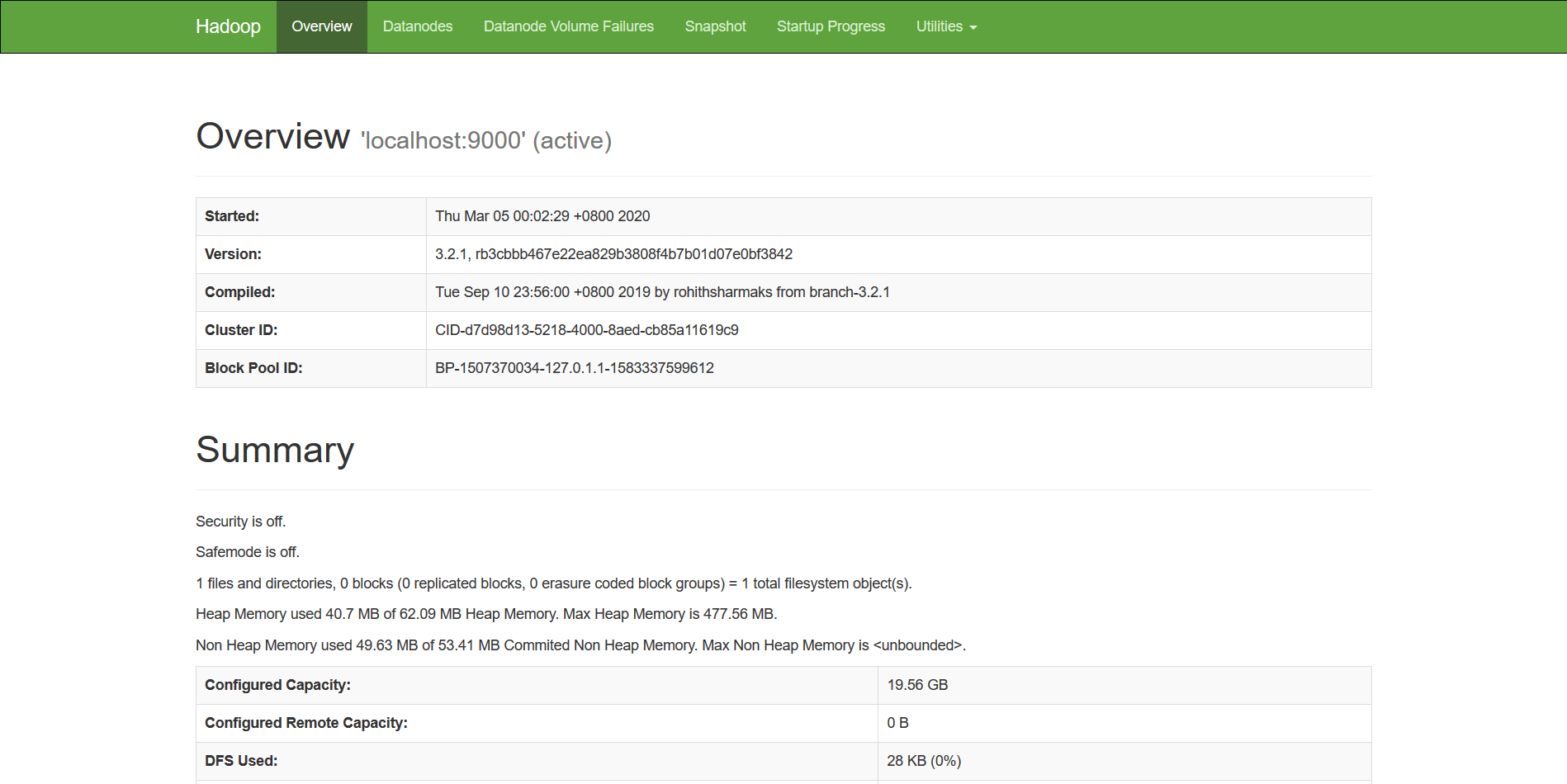
注:该端口号(9870)对应的是hadoop3.x版本的管理界面,如果你使用的是hadoop2.x,应尝试访问端口(50070)
配置全分布式模式(Hadoop集群)
关闭伪分布式模式
如果你在上一节中开启了伪分布式模式,执行以下指令以关闭服务并清空缓存:
/usr/local/hadoop/sbin/stop-all.sh
rm -rf /usr/local/hadoop/tmp
克隆出多台虚拟机
将已经完成Hadoop安装(至少hadoop version可以运行)的虚拟机克隆出另外三台(如果你的电脑资源不足,至少克隆出一台),分别命名为hadoop2、hadoop3、hadoop4,此时我们就有了4台安装有Hadoop的虚拟机,我们以hadoop1作为主节点,其它作为子节点进行配置。
如果你不了解Vmware克隆功能的使用方法,你可以参照使用Vmware克隆功能快速创建多台虚拟机。
注:如果你使用的是逻辑主机而不是虚拟机或无法进行克隆操作,你需要将其它主机配置好单机模式。
注:如果你运行的是ubuntu Server,不要直接用克隆,否则你将进入火葬场。
完成克隆后,我的虚拟机ip地址如下,下文所有指令都以我的虚拟机ip地址举例,你需要修改为你的虚拟机对应的ip地址。
如果你不了解如何查看ip地址,你可以参照Ubuntu18.04查看ip地址。
下表中的hostname是便于我们分辨操作的是哪台机器设置的,在下文中会有相关设置指令,你可以先不用管。
| 虚拟机 | ip | hostname |
|---|---|---|
| hadoop1 | 192.168.232.131 | master |
| hadoop2 | 192.168.232.128 | slave1 |
| hadoop3 | 192.168.232.132 | slave2 |
| hadoop4 | 192.168.232.133 | slave3 |
设置ssh免登录以及hosts
在对应虚拟机中执行以下指令以设置hosts和ssh无密码登录:
在hadoop1中执行:
su # 将下列ip地址改为你对应虚拟机的ip地址 # 如果不设置hosts,hadoop能正常启动且jps都是正常的,但是管理界面看不到子节点 MASTER_IP=192.168.232.131 SLAVE1_IP=192.168.232.128 SLAVE2_IP=192.168.232.132 SLAVE3_IP=192.168.232.133 echo "$MASTER_IP master" >> /etc/hosts echo "$SLAVE1_IP slave1" >> /etc/hosts echo "$SLAVE2_IP slave2" >> /etc/hosts echo "$SLAVE3_IP slave3" >> /etc/hosts su hadoop cd /usr/local/hadoop/ bin/hdfs namenode -format # 格式化文件系统 # 创建ssh密钥,如果你是已经按照上面的章节配置过ssh免登录再进行克隆的话,忽略下面三条指令 ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys chmod 0600 ~/.ssh/authorized_keys # 分发ssh公钥,执行过程中需要输入yes,有可能需要输入密码hadoop,你需要逐行执行下面的指令 ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop@slave1 ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop@slave2 ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop@slave3
在hadoop2、hadoop3、hadoop4中执行下列指令:
su hadoop cd /usr/local/hadoop rm -rf tmp # 创建ssh密钥 ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys chmod 0600 ~/.ssh/authorized_keys
修改配置文件
在主节点对应的虚拟机(hadoop1)中执行以下指令:
# 修改配置文件,你也可以手动修改 cd /usr/local/hadoop/etc/hadoop rm core-site.xml hdfs-site.xml mapred-site.xml yarn-site.xml wget https://gitee.com/focksor/hadoop-config/raw/master/Cluster/core-site.xml wget https://gitee.com/focksor/hadoop-config/raw/master/Cluster/hdfs-site.xml wget https://gitee.com/focksor/hadoop-config/raw/master/Cluster/mapred-site.xml wget https://gitee.com/focksor/hadoop-config/raw/master/Cluster/yarn-site.xml echo slave1 > workers echo slave2 >> workers echo slave3 >> workers # 分发配置文件文件到slave中 cd /usr/local/hadoop/etc scp -r hadoop/ hadoop@slave1:/usr/local/hadoop/etc scp -r hadoop/ hadoop@slave2:/usr/local/hadoop/etc scp -r hadoop/ hadoop@slave3:/usr/local/hadoop/etc
启动Hadoop
在主节点对应的虚拟机hadoop1内输入下面指令以启动Hadoop,启动过程大约需要半分钟:
start-all.sh
访问管理界面
完成上述步骤后使用主节点对应的虚拟机自带的网络浏览器firefox访问以下地址以查看NameNode信息:
http://localhost:9870/
如果你安装的是没有GUI界面的操作系统,你可以通过以下方式访问管理页面:
- 在真实系统的浏览器访问主节点虚拟机的ip地址+端口号:
http://192.168.232.131:9870/
如果你未知你的虚拟机的ip地址,可以参照Ubuntu18.04查看ip地址。
如果出现如下图所示类似画面(有3个节点,主节点并不在这里显示),则集群已搭建完成并已成功运行。
如果你的管理界面显示Live Nodes为0,或者无法访问管理界面,建议你转到设置ssh免登录以及hosts并检查你的hosts是否设置正确。

上传与下载文件
点击管理页面上侧的Utilities->Browse the file system,访问文件系统,点击下图所示位置开始上传文件。

完成上传后,点击文件的Name即可下载该文件或查看文件副本相关存放信息,如下图所示。

观察Download标签的链接
http://192.168.232.150:9870/webhdfs/v1/focksor5.jpg?op=OPEN,你会发现访问的是主节点(NameNode)的地址而不是存放副本的节点(DataNode)的地址,这是因为Hadoop的文件存取都是通过主节点来控制的,所以如果集群主节点挂了整个集群都挂掉。
explorer.html提示错误Server Error的解决方法
如果你的管理界面中的explorer.html(eg:http://192.168.232.150:9870/explorer.html#/)出现错误
Failed to retrieve data from /webhdfs/v1/?op=LISTSTATUS: Server Error,如下图所示,说明你的hadoop版本与jdk版本不兼容,建议使用openjdk-8。假设你目前使用的时openjdk-11,你应该在所有节点中执行以下指令以替换jdk,替换后应重启集群:sudo apt-get install openjdk-8-jre openjdk-8-jdk -y sed -i "s?java-11-openjdk-amd64?java-8-openjdk-amd64?g" /usr/local/hadoop/etc/hadoop/hadoop-env.sh
正确的运行界面应如下图所示:


explorer.html中上传文件提示Couldn't upload the file的解决方法
如果在explorer.html中上传文件时提示错误
Couldn't upload the file filename,如下图所示
打开浏览器的开发者工具监听网络,可以看到是因为
focksor-hadoop-slave4无法解析(如下图下侧所示),要解决这个问题,你需要将对应的条目写入到你现实系统的hosts中,假设你的系统为windwos,操作如下:
访问
http://192.168.232.150:9870/dfshealth.html#tab-datanode(此处应将ip修改为你的主节点对应的ip地址)将红框所示的主机名与ip写入到hosts文件中,windows的hosts文件位置为
C:\Windows\System32\drivers\etc\hosts,你需要有管理员身份才能修改。
- 修改完成的hosts文件应类似如下:
# Copyright (c) 1993-2009 Microsoft Corp. # # This is a sample HOSTS file used by Microsoft TCP/IP for Windows. # # This file contains the mappings of IP addresses to host names. Each # entry should be kept on an individual line. The IP address should # be placed in the first column followed by the corresponding host name. # The IP address and the host name should be separated by at least one # space. # # Additionally, comments (such as these) may be inserted on individual # lines or following the machine name denoted by a '#' symbol. # # For example: # # 102.54.94.97 rhino.acme.com # source server # 38.25.63.10 x.acme.com # x client host # localhost name resolution is handled within DNS itself. # 127.0.0.1 localhost # ::1 localhost 192.168.232.150 focksor-hadoop-master 192.168.232.151 focksor-hadoop-slave1 192.168.232.152 focksor-hadoop-slave2 192.168.232.153 focksor-hadoop-slave3 192.168.232.154 focksor-hadoop-slave4


使用Python进行文件操作
附录
如果你无法按照本篇文章完成配置,你可以下载我已经完成环境搭建的虚拟机并自行比较配置差异。如果你不了解如何导入虚拟机,可以参考在Vmware中导入已有的虚拟机。
下载地址:百度网盘 提取码:7ith
注:
- 该集群使用的环境操作系统为
ubuntu-18.04.4-live-server-amd64,是无图形操作界面的server版本- 该集群的所有主机的用户名与密码都是
hadoop- 建议你的电脑至少拥有16G内存以流畅运行该集群
- 该集群的主机名、身份、ip如下表,如果你运行该集群时ip地址与下表不符,应修改虚拟机的ip地址:
身份 主机名 ip地址 master focksor-hadoop-master 192.168.232.150 slave focksor-hadoop-slave1 192.168.232.151 slave focksor-hadoop-slave2 192.168.232.152 slave focksor-hadoop-slave3 192.168.232.153 slave focksor-hadoop-slave4 192.168.232.154
参考资料
本文主要参考的内容有:
Hadoop官方文档 Hadoop: Setting up a Single Node Cluster
树锐的Hadoop笔记

