最新的爬虫工具requests-html
2018-04-25 23:02 虫师 阅读(27531) 评论(7) 收藏 举报使用Python开发的同学一定听说过Requsts库,它是一个用于发送HTTP请求的测试。如比我们用Python做基于HTTP协议的接口测试,那么一定会首选Requsts,因为它即简单又强大。现在作者Kenneth Reitz 又开发了requests-html 用于做爬虫。
该项目从3月上线到现在已经7K+的star了!
GiHub项目地址:
https://github.com/kennethreitz/requests-html
requests-html 是基于现有的框架 PyQuery、Requests、lxml、beautifulsoup4等库进行了二次封装,作者将Requests设计的简单强大的优点带到了该项目中。
#安装:
> pip install requests-html
教程与使用:
使用GET请求 https://python.org 网站。
先来看看requests的基本使用。
from requests_html import HTMLSession
session = HTMLSession()
r = session.get('https://python.org/')
# 获取页面上的所有链接。
all_links = r.html.links
print(all_links)
# 获取页面上的所有链接,以绝对路径的方式。
all_absolute_links = r.html.absolute_links
print(all_absolute_links)
作为一个IT技术人员,是不是要时时关心一下科技圈的新闻,上博客园新闻频道,抓取最新的推荐新闻。
from requests_html import HTMLSession
session = HTMLSession()
r = session.get("https://news.cnblogs.com/n/recommend")
# 通过CSS找到新闻标签
news = r.html.find('h2.news_entry > a')
for new in news:
print(new.text) # 获得新闻标题
print(new.absolute_links) # 获得新闻链接
执行结果:
雷军:小米硬件综合净利率永远不超5%!
{'https://news.cnblogs.com/n/595156/'}
苦大仇深的“中国芯”,不妨学一学有趣的树莓派
{'https://news.cnblogs.com/n/595143/'}
我的快递,凭什么不能给我送到家!
{'https://news.cnblogs.com/n/595087/'}
倪光南回应方舟CPU失败论:企业失败不等于技术失败
{'https://news.cnblogs.com/n/595102/'}
清华大学突破纪录:首次实现25个量子接口间量子纠缠
{'https://news.cnblogs.com/n/595103/'}
定向免流量套餐用着爽,但背后的“坑”你可能不知道
{'https://news.cnblogs.com/n/595061/'}
你在微信群侃大山,有人却用微信群发大财
{'https://news.cnblogs.com/n/595059/'}
马云的三观
{'https://news.cnblogs.com/n/595047/'}
美国科技强大的全部秘密
{'https://news.cnblogs.com/n/595043/'}
盖茨看着听证会上的扎克伯格:满眼都是20年前的自己
{'https://news.cnblogs.com/n/595025/'}
史上最清晰癌细胞转移3D影像来袭
{'https://news.cnblogs.com/n/595019/'}
中兴员工:华为仅部分芯片自己设计 谁被美制裁都得死
{'https://news.cnblogs.com/n/594967/'}
作为曾经的华为员工,我想替中兴公司说两句公道话
{'https://news.cnblogs.com/n/594962/'}
匿名网友回评梁宁:方舟bug无数 贴钱给别人都未必用
{'https://news.cnblogs.com/n/594932/'}
一段关于国产芯片和操作系统的往事
{'https://news.cnblogs.com/n/594900/'}
芯片股总市值低于美国巨头 有公司靠政府补助盈利
{'https://news.cnblogs.com/n/594902/'}
被自家律师送上“枪口”的“二流”中兴
{'https://news.cnblogs.com/n/594859/'}
Google正在失去DeepMind?
{'https://news.cnblogs.com/n/594853/'}
扩展:我们可以进一步将这里数据做持久化处理,设计出自己的“头条”。
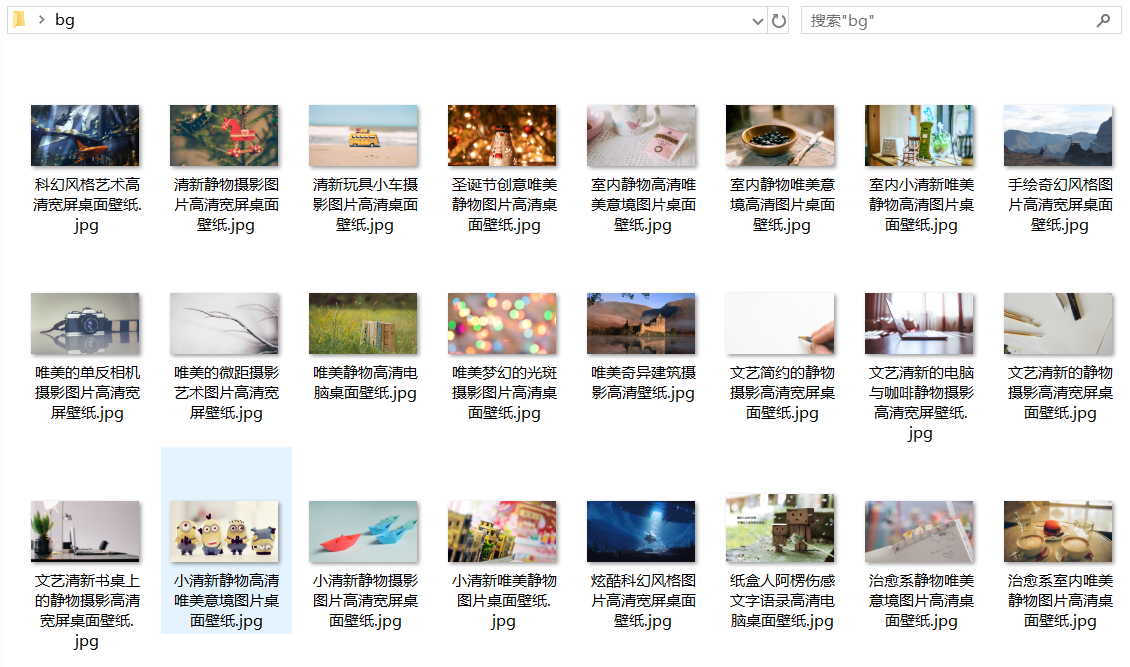
接下来我们到网站上下载壁纸,以美桌网(www.win4000.com)为例。
from requests_html import HTMLSession
import requests
# 保存图片到bg/目录
def save_image(url, title):
img_response = requests.get(url)
with open('./bg/'+title+'.jpg', 'wb') as file:
file.write(img_response.content)
# 背景图片地址,这里选择1920*1080的背景图片
url = "http://www.win4000.com/wallpaper_2358_0_10_1.html"
session = HTMLSession()
r = session.get(url)
# 查找页面中背景图,找到链接,访问查看大图,并获取大图地址
items_img = r.html.find('ul.clearfix > li > a')
for img in items_img:
img_url = img.attrs['href']
if "/wallpaper_detail" in img_url:
r = session.get(img_url)
item_img = r.html.find('img.pic-large', first=True)
url = item_img.attrs['src']
title = item_img.attrs['title']
print(url+title)
save_image(url, title)
这个网站上的图片还是很容易获取的,在上面的代码块中我加了注释。这里不再说明。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号