ElasticSearch的基本原理与用法
一、简介
ElasticSearch和Solr都是基于Lucene的搜索引擎,不过ElasticSearch天生支持分布式,而Solr是4.0版本后的SolrCloud才是分布式版本,Solr的分布式支持需要ZooKeeper的支持。
这里有一个详细的ElasticSearch和Solr的对比:http://solr-vs-elasticsearch.com/
语法参考:
Elasticsearch Java API
Elasticsearch Query DSL
ElasticSearch安装部署:http://nero.life/2017/10/27/Elasticsearch%E7%AC%94%E8%AE%B0-%E4%B8%80-%E5%AE%89%E8%A3%85%E9%83%A8%E7%BD%B2/
elasticsearch Docker:http://nero.life/2017/10/27/Elasticsearch%E7%AC%94%E8%AE%B0-%E4%BA%8C-Docker/
ElasticSearch笔记:http://nero.life/2017/10/27/Elasticsearch%E7%AC%94%E8%AE%B0/
二、基本用法
集群(Cluster): ES是一个分布式的搜索引擎,一般由多台物理机组成。这些物理机,通过配置一个相同的cluster name,互相发现,把自己组织成一个集群。
节点(Node):同一个集群中的一个Elasticsearch主机。
Node类型:
1)data node: 存储index数据。Data nodes hold data and perform data related operations such as CRUD, search, and aggregations.
2)client node: 不存储index,处理转发客户端请求到Data Node。
3)master node: 不存储index,集群管理,如管理路由信息(routing infomation),判断node是否available,当有node出现或消失时重定位分片(shards),当有node failure时协调恢复。(所有的master node会选举出一个master leader node)
详情参考:https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-node.html
主分片(Primary shard):索引(下文介绍)的一个物理子集。同一个索引在物理上可以切多个分片,分布到不同的节点上。分片的实现是Lucene 中的索引。
注意:ES中一个索引的分片个数是建立索引时就要指定的,建立后不可再改变。所以开始建一个索引时,就要预计数据规模,将分片的个数分配在一个合理的范围。
副本分片(Replica shard):每个主分片可以有一个或者多个副本,个数是用户自己配置的。ES会尽量将同一索引的不同分片分布到不同的节点上,提高容错性。对一个索引,只要不是所有shards所在的机器都挂了,就还能用。
索引(Index):逻辑概念,一个可检索的文档对象的集合。类似与DB中的database概念。同一个集群中可建立多个索引。比如,生产环境常见的一种方法,对每个月产生的数据建索引,以保证单个索引的量级可控。
类型(Type):索引的下一级概念,大概相当于数据库中的table。同一个索引里可以包含多个 Type。
文档(Document):即搜索引擎中的文档概念,也是ES中一个可以被检索的基本单位,相当于数据库中的row,一条记录。
字段(Field):相当于数据库中的column。ES中,每个文档,其实是以json形式存储的。而一个文档可以被视为多个字段的集合。比如一篇文章,可能包括了主题、摘要、正文、作者、时间等信息,每个信息都是一个字段,最后被整合成一个json串,落地到磁盘。
映射(Mapping):相当于数据库中的schema,用来约束字段的类型,不过 Elasticsearch 的 mapping 可以不显示地指定、自动根据文档数据创建。
| Database(数据库) | Index(索引) |
| Table(表) | Type(类型) |
| Row(行) | Document(文档) |
| Column(列) | Field(字段) |
| Schema(方案) | Mapping(映射) |
| Index(索引) | Everthing Indexed by default(所有字段都被索引) |
| SQL(结构化查询语言) | Query DSL(查询专用语言) |
Elasticsearch集群可以包含多个索引(indices),每一个索引可以包含多个类型(types),每一个类型包含多个文档(documents),然后每个文档包含多个字段(Fields),这种面向文档型的储存,也算是NoSQL的一种吧。
ES比传统关系型数据库,对一些概念上的理解:
Relational DB -> Databases -> Tables -> Rows -> Columns
Elasticsearch -> Indices -> Types -> Documents -> Fields从创建一个Client到添加、删除、查询等基本用法:
1、创建Client
1 public ElasticSearchService(String ipAddress, int port) { 2 client = new TransportClient() 3 .addTransportAddress(new InetSocketTransportAddress(ipAddress, 4 port)); 5 }
这里是一个TransportClient。
ES下两种客户端对比:
TransportClient:轻量级的Client,使用Netty线程池,Socket连接到ES集群。本身不加入到集群,只作为请求的处理。
Node Client:客户端节点本身也是ES节点,加入到集群,和其他ElasticSearch节点一样。频繁的开启和关闭这类Node Clients会在集群中产生“噪音”。
2、创建/删除Index和Type信息
1 // 创建索引 2 public void createIndex() { 3 client.admin().indices().create(new CreateIndexRequest(IndexName)) 4 .actionGet(); 5 } 6 7 // 清除所有索引 8 public void deleteIndex() { 9 IndicesExistsResponse indicesExistsResponse = client.admin().indices() 10 .exists(new IndicesExistsRequest(new String[] { IndexName })) 11 .actionGet(); 12 if (indicesExistsResponse.isExists()) { 13 client.admin().indices().delete(new DeleteIndexRequest(IndexName)) 14 .actionGet(); 15 } 16 } 17 18 // 删除Index下的某个Type 19 public void deleteType(){ 20 client.prepareDelete().setIndex(IndexName).setType(TypeName).execute().actionGet(); 21 } 22 23 // 定义索引的映射类型 24 public void defineIndexTypeMapping() { 25 try { 26 XContentBuilder mapBuilder = XContentFactory.jsonBuilder(); 27 mapBuilder.startObject() 28 .startObject(TypeName) 29 .startObject("_all").field("enabled", false).endObject() 30 .startObject("properties") 31 .startObject(IDFieldName).field("type", "long").endObject() 32 .startObject(SeqNumFieldName).field("type", "long").endObject() 33 .startObject(IMSIFieldName).field("type", "string").field("index", "not_analyzed").endObject() 34 .startObject(IMEIFieldName).field("type", "string").field("index", "not_analyzed").endObject() 35 .startObject(DeviceIDFieldName).field("type", "string").field("index", "not_analyzed").endObject() 36 .startObject(OwnAreaFieldName).field("type", "string").field("index", "not_analyzed").endObject() 37 .startObject(TeleOperFieldName).field("type", "string").field("index", "not_analyzed").endObject() 38 .startObject(TimeFieldName).field("type", "date").field("store", "yes").endObject() 39 .endObject() 40 .endObject() 41 .endObject(); 42 43 PutMappingRequest putMappingRequest = Requests 44 .putMappingRequest(IndexName).type(TypeName) 45 .source(mapBuilder); 46 client.admin().indices().putMapping(putMappingRequest).actionGet(); 47 } catch (IOException e) { 48 log.error(e.toString()); 49 } 50 }
这里自定义了某个Type的索引映射(Mapping):
1)默认ES会自动处理数据类型的映射:针对整型映射为long,浮点数为double,字符串映射为string,时间为date,true或false为boolean。
2)字段的默认配置是indexed,但不是stored的,也就是 field("index", "yes").field("store", "no")。
3)这里Disable了“_all”字段,_all字段会把所有的字段用空格连接,然后用“analyzed”的方式index这个字段,这个字段可以被search,但是不能被retrieve。
4)针对string,ES默认会做“analyzed”处理,即先做分词、去掉stop words等处理再index。如果你需要把一个字符串做为整体被索引到,需要把这个字段这样设置:field("index", "not_analyzed")。
5)默认_source字段是enabled,_source字段存储了原始Json字符串(original JSON document body that was passed at index time)。
详情参考:
https://www.elastic.co/guide/en/elasticsearch/guide/current/mapping-intro.html
https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-store.html
https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-all-field.html
https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-source-field.html
3、索引数据
1 // 批量索引数据 2 public void indexHotSpotDataList(List<Hotspotdata> dataList) { 3 if (dataList != null) { 4 int size = dataList.size(); 5 if (size > 0) { 6 BulkRequestBuilder bulkRequest = client.prepareBulk(); 7 for (int i = 0; i < size; ++i) { 8 Hotspotdata data = dataList.get(i); 9 String jsonSource = getIndexDataFromHotspotData(data); 10 if (jsonSource != null) { 11 bulkRequest.add(client 12 .prepareIndex(IndexName, TypeName, 13 data.getId().toString()) 14 .setRefresh(true).setSource(jsonSource)); 15 } 16 } 17 18 BulkResponse bulkResponse = bulkRequest.execute().actionGet(); 19 if (bulkResponse.hasFailures()) { 20 Iterator<BulkItemResponse> iter = bulkResponse.iterator(); 21 while (iter.hasNext()) { 22 BulkItemResponse itemResponse = iter.next(); 23 if (itemResponse.isFailed()) { 24 log.error(itemResponse.getFailureMessage()); 25 } 26 } 27 } 28 } 29 } 30 } 31 32 // 索引数据 33 public boolean indexHotspotData(Hotspotdata data) { 34 String jsonSource = getIndexDataFromHotspotData(data); 35 if (jsonSource != null) { 36 IndexRequestBuilder requestBuilder = client.prepareIndex(IndexName, 37 TypeName).setRefresh(true); 38 requestBuilder.setSource(jsonSource) 39 .execute().actionGet(); 40 return true; 41 } 42 43 return false; 44 } 45 46 // 得到索引字符串 47 public String getIndexDataFromHotspotData(Hotspotdata data) { 48 String jsonString = null; 49 if (data != null) { 50 try { 51 XContentBuilder jsonBuilder = XContentFactory.jsonBuilder(); 52 jsonBuilder.startObject().field(IDFieldName, data.getId()) 53 .field(SeqNumFieldName, data.getSeqNum()) 54 .field(IMSIFieldName, data.getImsi()) 55 .field(IMEIFieldName, data.getImei()) 56 .field(DeviceIDFieldName, data.getDeviceID()) 57 .field(OwnAreaFieldName, data.getOwnArea()) 58 .field(TeleOperFieldName, data.getTeleOper()) 59 .field(TimeFieldName, data.getCollectTime()) 60 .endObject(); 61 jsonString = jsonBuilder.string(); 62 } catch (IOException e) { 63 log.equals(e); 64 } 65 } 66 67 return jsonString; 68 }
ES支持批量和单个数据索引。
4、查询获取数据
1 // 获取少量数据100个 2 private List<Integer> getSearchData(QueryBuilder queryBuilder) { 3 List<Integer> ids = new ArrayList<>(); 4 SearchResponse searchResponse = client.prepareSearch(IndexName) 5 .setTypes(TypeName).setQuery(queryBuilder).setSize(100) 6 .execute().actionGet(); 7 SearchHits searchHits = searchResponse.getHits(); 8 for (SearchHit searchHit : searchHits) { 9 Integer id = (Integer) searchHit.getSource().get("id"); 10 ids.add(id); 11 } 12 return ids; 13 } 14 15 // 获取大量数据 16 private List<Integer> getSearchDataByScrolls(QueryBuilder queryBuilder) { 17 List<Integer> ids = new ArrayList<>(); 18 // 一次获取100000数据 19 SearchResponse scrollResp = client.prepareSearch(IndexName) 20 .setSearchType(SearchType.SCAN).setScroll(new TimeValue(60000)) 21 .setQuery(queryBuilder).setSize(100000).execute().actionGet(); 22 while (true) { 23 for (SearchHit searchHit : scrollResp.getHits().getHits()) { 24 Integer id = (Integer) searchHit.getSource().get(IDFieldName); 25 ids.add(id); 26 } 27 scrollResp = client.prepareSearchScroll(scrollResp.getScrollId()) 28 .setScroll(new TimeValue(600000)).execute().actionGet(); 29 if (scrollResp.getHits().getHits().length == 0) { 30 break; 31 } 32 } 33 34 return ids; 35 }
这里的QueryBuilder是一个查询条件,ES支持分页查询获取数据,也可以一次性获取大量数据,需要使用Scroll Search。
5、聚合(Aggregation Facet)查询
1 // 得到某段时间内设备列表上每个设备的数据分布情况<设备ID,数量> 2 public Map<String, String> getDeviceDistributedInfo(String startTime, 3 String endTime, List<String> deviceList) { 4 5 Map<String, String> resultsMap = new HashMap<>(); 6 7 QueryBuilder deviceQueryBuilder = getDeviceQueryBuilder(deviceList); 8 QueryBuilder rangeBuilder = getDateRangeQueryBuilder(startTime, endTime); 9 QueryBuilder queryBuilder = QueryBuilders.boolQuery() 10 .must(deviceQueryBuilder).must(rangeBuilder); 11 12 TermsBuilder termsBuilder = AggregationBuilders.terms("DeviceIDAgg").size(Integer.MAX_VALUE) 13 .field(DeviceIDFieldName); 14 SearchResponse searchResponse = client.prepareSearch(IndexName) 15 .setQuery(queryBuilder).addAggregation(termsBuilder) 16 .execute().actionGet(); 17 Terms terms = searchResponse.getAggregations().get("DeviceIDAgg"); 18 if (terms != null) { 19 for (Terms.Bucket entry : terms.getBuckets()) { 20 resultsMap.put(entry.getKey(), 21 String.valueOf(entry.getDocCount())); 22 } 23 } 24 return resultsMap; 25 }
Aggregation查询可以查询类似统计分析这样的功能:如某个月的数据分布情况,某类数据的最大、最小、总和、平均值等。
详情参考:https://www.elastic.co/guide/en/elasticsearch/client/java-api/current/java-aggs.html
查询准备
当我们获取到connection以后,接下来就可以开始做查询的准备。
-
1 首先我们可以通过client来获取到一个SearchRequestBuilder的实例,这个是我们查询的主干。
然后你需要给SearchRequestBuilder指定查询目标, Index以及Type(映射到数据库就是数据库名称以及表名) -
2 指定分页信息,setFrom以及setSize。
PS: 千万不要指望能一次性的查询到所有的数据,尤其是document特别多的时候。Elasticsearch最多只会给你返回1000条数据,
一次性返回过量的数据是灾难性,这点无论是Elasticsearch亦或是Database都适用。
1 SearchRequestBuilder searchRequestBuilder = client.prepareSearch(ES_ITEM_INDEX).setTypes(ES_ITEM_TYPE) 2 .setFrom((pageNum - 1) * pageSize) 3 .setSize(pageSize);
- 3 接下来,你可能需要指定返回的字段,可以用如下的代码设置:
1 String[] includes = {"id", "name"}; 2 searchRequestBuilder.setFetchSource(includes, null);
- 4 构建查询器
我们以自己熟悉的SQL来做实例讲解,如下sql:
select * from student where id = '123' and age > 12 and name like '小明' and hid in (...)
我们看SQL后面where条件。包含了’等于,大于,模糊查询,in查询’。
首先我们需要一个能包含复杂查询条件的BoolQueryBuilder,你可以将一个个小查询条件设置进去,最后将它设给searchRequestBuilder。
1 BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
id = ‘123’:
1 QueryBuilder idQueryBuilder = QueryBuilders.termQuery("id", 123); 2 boolQueryBuilder.must(idQueryBuilder);
age > 12:
1 RangeQueryBuilder ageQueryBuilder = QueryBuilders.rangeQuery("age").gt(12); 2 boolQueryBuilder.must(ageQueryBuilder);
name like ‘小明’:
1 MatchQueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("name", '小明'); 2 matchQueryBuilder.operator(Operator.AND); 3 boolQueryBuilder.must(matchQueryBuilder);
这个就是我们比较关注的关键字查询了。因为我的Elasticsearch中字段name,已经配置了ik_smart分词器。
所以此处会将我的条件”小明”进行ik_smart的分词查询。而我设置的Operator.AND属性,指的是必须要我传
入的查询条件分词后字段全部匹配,才会返回结果。默认是Operator.OR,也就是其中有一个匹配,结果就返回。
hid in (…):
1 QueryBuilder queryBuilder = QueryBuilders.termsQuery("hid", hidList); 2 boolQueryBuilder.must(queryBuilder);
PS: 上述的SQL条件中,皆是以AND关键字进行拼接。如果是其他的,比如OR,比如Not in呢?请看下面:
and – must
or – should
not in – must not
好,最后我们将queryBuilder设置进searchRequestBuilder中。
1 // 设置查询条件 2 searchRequestBuilder.setQuery(boolQueryBuilder);
- 5 排序
我们同样需要一个排序构造器:SortBuilder。
咱先根据age字段,做降序。如下代码:
1 SortBuilder sortBuilder = SortBuilders.fieldSort("age"); 2 sortBuilder.order(SortOrder.fromString("DESC"));
如果想要做一些较为复杂的排序,比如多个字段相加:
1 String scriptStr = "doc['clickCount'].value + doc['soldNum'].value"; 2 sortBuilder = SortBuilders.scriptSort(new Script(scriptStr), ScriptSortBuilder.ScriptSortType.NUMBER);
1 // 设置排序规则 2 searchRequestBuilder.addSort(sortBuilder);
- 6 高亮显示
在具体业务查询中,其实我们通常需要用到如该图的效果。
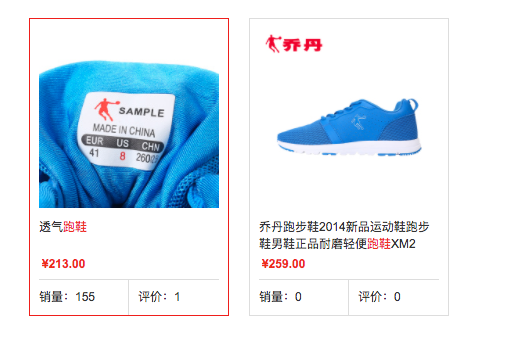
将查询命中的关键,进行标记颜色样式。
Elasticsearch同样提供了功能的实现,我们只需要设置被查询的字段即可。如下代码:
1 HighlightBuilder highlightBuilder = new HighlightBuilder(); 2 highlightBuilder.field("name"); 3 searchRequestBuilder.highlighter(highlightBuilder);
在下面的解析结果中,会具体介绍怎么解析出这么高亮结果。
- 7 聚合
当然,Elasticsearch也提供了强大的聚合功能:
1 // 年龄聚合计算 2 TermsAggregationBuilder ageTermsAggregationBuilder = AggregationBuilders.terms("ageAgg"); 3 brandTermsAggregationBuilder.field("age"); 4 brandTermsAggregationBuilder.size(1000); 5 searchRequestBuilder.addAggregation(ageTermsAggregationBuilder);
- 8 执行查询
1 // 开始执行查询 2 SearchResponse searchResponse = searchRequestBuilder.execute().actionGet();
- 9 解析结果
直接上代码:
1 SearchHits searchHits = searchResponse.getHits(); 2 List<Student> students = new ArrayList<>(); 3 for (SearchHit hit : searchHits.getHits()) { 4 String json = hit.getSourceAsString(); 5 # 读取json,转为成对象 6 Student student= ... 7 // 关键字高亮显示 8 HighlightField highlightField = hit.getHighlightFields().get("name"); 9 String highName = student.getName(); 10 if (highlightField != null) { 11 highName = highlightField.getFragments()[0].toString(); 12 } 13 student.setHighName(highName); 14 students.add(student); 15 }
我们可以从searchResponse中,获取到所有的命中目标列表。然后循环列表,每个命中的hit,可以直接转化成json。
然后可以json转化工具,映射到自己的bean上。
其中,当你设置了highlightBuilder以后,你可以在每个hit里,get到被标签包裹着的String。
(ps: 默认是em,你也可以设置其他的标签,以供前端渲染。)
使用QueryBuilders进行查询
elastcisearch-query-builder接受配置文件(特定json格式)或者json格式的字符串配置,配置格式如下:
{ "index": "user_portrait", "type": "docs", "from": "${from}", "size": "10", "include_source": ["name","age"], //需要哪些字段 "exclude_source": ["sex"], //排除哪些字段 "query_type": "terms_level_query", "terms_level_query": { "terms_level_type": "term_query", "term_query": { "value": "${value}", "key": "key", "boost": 2 } }, "aggregations": [ { "aggregation_type": "terms", "name": "", "field": "field", "sub_aggregations": { "aggregation_type": "terms", "name": "sub", "field": "field", "size": "${size.value}", "sort": "asc", "sort_by": "_count" } } ], "highlight":{ "fields": [ { "field": "content", "number_of_fragment": 2, "no_match_size": 150 } ], "pre_tags":["<em>"], "post_tags":["</em>"] }, "sort": [ "_score", { "field": "age", "order": "asc" } ] }
参数说明
# index
index表示elasticSearch中的索引或者别名。
# type
type表示elasticSearch索引或者别名下的type。
# from
from表示检索文档时的偏移量,相当于关系型数据库里的offset。
# include_source
include_source 搜索结果中包含某些字段,格式为json数组,"include_source": ["name","age"]。
# exclude_source
exclude_source 搜索结果中排除某些字段,格式为json数组,"exclude_source":["sex"]。
# query_type
query_type表示查询类型,支持三种类型terms_level_query,text_level_query,bool_level_query,并且这三种类型
不可以一起使用。
-
terms_level_query操作的精确字段是存储在反转索引中的。这些查询通常用于结构化数据,
如数字、日期和枚举, 而不是全文字段,包含term_query,terms_query,range_query,exists_query 等类型。 -
text_level_query查询通常用于在完整文本字段 (如电子邮件正文) 上运行全文查询。他们了解如何分析被查询的字段,
并在执行之前将每个字段的分析器 (或 search_analyzer) 应用到查询字符串。
包含 match_query,multi_match_query,query_string,simple_query_string 等类型。 -
bool_query与其他查询的布尔组合匹配的文档匹配的查询。bool 查询映射到 Lucene BooleanQuery。它是使用一个或多个布尔子句生成的, 每个子句都有一个类型化的实例。
布尔查询的查询值包括: must,filter,should,must_not. 在每个布尔查询的查询类型值中,可以包含terms_level_query 和 text_level_query中任意的查询类型,如此便可以构造非常复杂的查询情况。
QueryBuilder 是es中提供的一个查询接口, 可以对其进行参数设置来进行查询:
1 package com.wenbronk.javaes; 2 3 import java.net.InetSocketAddress; 4 import java.util.ArrayList; 5 import java.util.Iterator; 6 import java.util.Map.Entry; 7 8 import org.elasticsearch.action.ListenableActionFuture; 9 import org.elasticsearch.action.get.GetRequestBuilder; 10 import org.elasticsearch.action.get.GetResponse; 11 import org.elasticsearch.action.search.SearchResponse; 12 import org.elasticsearch.action.search.SearchType; 13 import org.elasticsearch.client.transport.TransportClient; 14 import org.elasticsearch.common.settings.Settings; 15 import org.elasticsearch.common.text.Text; 16 import org.elasticsearch.common.transport.InetSocketTransportAddress; 17 import org.elasticsearch.common.unit.TimeValue; 18 import org.elasticsearch.index.query.IndicesQueryBuilder; 19 import org.elasticsearch.index.query.NestedQueryBuilder; 20 import org.elasticsearch.index.query.QueryBuilder; 21 import org.elasticsearch.index.query.QueryBuilders; 22 import org.elasticsearch.index.query.QueryStringQueryBuilder; 23 import org.elasticsearch.index.query.RangeQueryBuilder; 24 import org.elasticsearch.index.query.SpanFirstQueryBuilder; 25 import org.elasticsearch.index.query.WildcardQueryBuilder; 26 import org.elasticsearch.search.SearchHit; 27 import org.elasticsearch.search.SearchHits; 28 import org.junit.Before; 29 import org.junit.Test; 30 31 /** 32 * java操作查询api 33 * @author 231 34 * 35 */ 36 public class JavaESQuery { 37 38 private TransportClient client; 39 40 @Before 41 public void testBefore() { 42 Settings settings = Settings.settingsBuilder().put("cluster.name", "wenbronk_escluster").build(); 43 client = TransportClient.builder().settings(settings).build() 44 .addTransportAddress(new InetSocketTransportAddress(new InetSocketAddress("192.168.50.37", 9300))); 45 System.out.println("success to connect escluster"); 46 } 47 48 /** 49 * 使用get查询 50 */ 51 @Test 52 public void testGet() { 53 GetRequestBuilder requestBuilder = client.prepareGet("twitter", "tweet", "1"); 54 GetResponse response = requestBuilder.execute().actionGet(); 55 GetResponse getResponse = requestBuilder.get(); 56 ListenableActionFuture<GetResponse> execute = requestBuilder.execute(); 57 System.out.println(response.getSourceAsString()); 58 } 59 60 /** 61 * 使用QueryBuilder 62 * termQuery("key", obj) 完全匹配 63 * termsQuery("key", obj1, obj2..) 一次匹配多个值 64 * matchQuery("key", Obj) 单个匹配, field不支持通配符, 前缀具高级特性 65 * multiMatchQuery("text", "field1", "field2"..); 匹配多个字段, field有通配符忒行 66 * matchAllQuery(); 匹配所有文件 67 */ 68 @Test 69 public void testQueryBuilder() { 70 // QueryBuilder queryBuilder = QueryBuilders.termQuery("user", "kimchy"); 71 QueryBUilder queryBuilder = QueryBuilders.termQuery("user", "kimchy", "wenbronk", "vini"); 72 QueryBuilders.termsQuery("user", new ArrayList<String>().add("kimchy")); 73 // QueryBuilder queryBuilder = QueryBuilders.matchQuery("user", "kimchy"); 74 // QueryBuilder queryBuilder = QueryBuilders.multiMatchQuery("kimchy", "user", "message", "gender"); 75 QueryBuilder queryBuilder = QueryBuilders.matchAllQuery(); 76 searchFunction(queryBuilder); 77 78 } 79 80 /** 81 * 组合查询 82 * must(QueryBuilders) : AND 83 * mustNot(QueryBuilders): NOT 84 * should: : OR 85 */ 86 @Test 87 public void testQueryBuilder2() { 88 QueryBuilder queryBuilder = QueryBuilders.boolQuery() 89 .must(QueryBuilders.termQuery("user", "kimchy")) 90 .mustNot(QueryBuilders.termQuery("message", "nihao")) 91 .should(QueryBuilders.termQuery("gender", "male")); 92 searchFunction(queryBuilder); 93 } 94 95 /** 96 * 只查询一个id的 97 * QueryBuilders.idsQuery(String...type).ids(Collection<String> ids) 98 */ 99 @Test 100 public void testIdsQuery() { 101 QueryBuilder queryBuilder = QueryBuilders.idsQuery().ids("1"); 102 searchFunction(queryBuilder); 103 } 104 105 /** 106 * 包裹查询, 高于设定分数, 不计算相关性 107 */ 108 @Test 109 public void testConstantScoreQuery() { 110 QueryBuilder queryBuilder = QueryBuilders.constantScoreQuery(QueryBuilders.termQuery("name", "kimchy")).boost(2.0f); 111 searchFunction(queryBuilder); 112 // 过滤查询 113 // QueryBuilders.constantScoreQuery(FilterBuilders.termQuery("name", "kimchy")).boost(2.0f); 114 115 } 116 117 /** 118 * disMax查询 119 * 对子查询的结果做union, score沿用子查询score的最大值, 120 * 广泛用于muti-field查询 121 */ 122 @Test 123 public void testDisMaxQuery() { 124 QueryBuilder queryBuilder = QueryBuilders.disMaxQuery() 125 .add(QueryBuilders.termQuery("user", "kimch")) // 查询条件 126 .add(QueryBuilders.termQuery("message", "hello")) 127 .boost(1.3f) 128 .tieBreaker(0.7f); 129 searchFunction(queryBuilder); 130 } 131 132 /** 133 * 模糊查询 134 * 不能用通配符, 不知道干啥用 135 */ 136 @Test 137 public void testFuzzyQuery() { 138 QueryBuilder queryBuilder = QueryBuilders.fuzzyQuery("user", "kimch"); 139 searchFunction(queryBuilder); 140 } 141 142 /** 143 * 父或子的文档查询 144 */ 145 @Test 146 public void testChildQuery() { 147 QueryBuilder queryBuilder = QueryBuilders.hasChildQuery("sonDoc", QueryBuilders.termQuery("name", "vini")); 148 searchFunction(queryBuilder); 149 } 150 151 /** 152 * moreLikeThisQuery: 实现基于内容推荐, 支持实现一句话相似文章查询 153 * { 154 "more_like_this" : { 155 "fields" : ["title", "content"], // 要匹配的字段, 不填默认_all 156 "like_text" : "text like this one", // 匹配的文本 157 } 158 } 159 160 percent_terms_to_match:匹配项(term)的百分比,默认是0.3 161 162 min_term_freq:一篇文档中一个词语至少出现次数,小于这个值的词将被忽略,默认是2 163 164 max_query_terms:一条查询语句中允许最多查询词语的个数,默认是25 165 166 stop_words:设置停止词,匹配时会忽略停止词 167 168 min_doc_freq:一个词语最少在多少篇文档中出现,小于这个值的词会将被忽略,默认是无限制 169 170 max_doc_freq:一个词语最多在多少篇文档中出现,大于这个值的词会将被忽略,默认是无限制 171 172 min_word_len:最小的词语长度,默认是0 173 174 max_word_len:最多的词语长度,默认无限制 175 176 boost_terms:设置词语权重,默认是1 177 178 boost:设置查询权重,默认是1 179 180 analyzer:设置使用的分词器,默认是使用该字段指定的分词器 181 */ 182 @Test 183 public void testMoreLikeThisQuery() { 184 QueryBuilder queryBuilder = QueryBuilders.moreLikeThisQuery("user") 185 .like("kimchy"); 186 // .minTermFreq(1) //最少出现的次数 187 // .maxQueryTerms(12); // 最多允许查询的词语 188 searchFunction(queryBuilder); 189 } 190 191 /** 192 * 前缀查询 193 */ 194 @Test 195 public void testPrefixQuery() { 196 QueryBuilder queryBuilder = QueryBuilders.matchQuery("user", "kimchy"); 197 searchFunction(queryBuilder); 198 } 199 200 /** 201 * 查询解析查询字符串 202 */ 203 @Test 204 public void testQueryString() { 205 QueryBuilder queryBuilder = QueryBuilders.queryStringQuery("+kimchy"); 206 searchFunction(queryBuilder); 207 } 208 209 /** 210 * 范围内查询 211 */ 212 public void testRangeQuery() { 213 QueryBuilder queryBuilder = QueryBuilders.rangeQuery("user") 214 .from("kimchy") 215 .to("wenbronk") 216 .includeLower(true) // 包含上界 217 .includeUpper(true); // 包含下届 218 searchFunction(queryBuilder); 219 } 220 221 /** 222 * 跨度查询 223 */ 224 @Test 225 public void testSpanQueries() { 226 QueryBuilder queryBuilder1 = QueryBuilders.spanFirstQuery(QueryBuilders.spanTermQuery("name", "葫芦580娃"), 30000); // Max查询范围的结束位置 227 228 QueryBuilder queryBuilder2 = QueryBuilders.spanNearQuery() 229 .clause(QueryBuilders.spanTermQuery("name", "葫芦580娃")) // Span Term Queries 230 .clause(QueryBuilders.spanTermQuery("name", "葫芦3812娃")) 231 .clause(QueryBuilders.spanTermQuery("name", "葫芦7139娃")) 232 .slop(30000) // Slop factor 233 .inOrder(false) 234 .collectPayloads(false); 235 236 // Span Not 237 QueryBuilder queryBuilder3 = QueryBuilders.spanNotQuery() 238 .include(QueryBuilders.spanTermQuery("name", "葫芦580娃")) 239 .exclude(QueryBuilders.spanTermQuery("home", "山西省太原市2552街道")); 240 241 // Span Or 242 QueryBuilder queryBuilder4 = QueryBuilders.spanOrQuery() 243 .clause(QueryBuilders.spanTermQuery("name", "葫芦580娃")) 244 .clause(QueryBuilders.spanTermQuery("name", "葫芦3812娃")) 245 .clause(QueryBuilders.spanTermQuery("name", "葫芦7139娃")); 246 247 // Span Term 248 QueryBuilder queryBuilder5 = QueryBuilders.spanTermQuery("name", "葫芦580娃"); 249 } 250 251 /** 252 * 测试子查询 253 */ 254 @Test 255 public void testTopChildrenQuery() { 256 QueryBuilders.hasChildQuery("tweet", 257 QueryBuilders.termQuery("user", "kimchy")) 258 .scoreMode("max"); 259 } 260 261 /** 262 * 通配符查询, 支持 * 263 * 匹配任何字符序列, 包括空 264 * 避免* 开始, 会检索大量内容造成效率缓慢;对于通配符查询必须注意一个问题,就是参数必须小写,即例子中“kihy”必须小写,这是个坑 265 */ 266 @Test 267 public void testWildCardQuery() { 268 QueryBuilder queryBuilder = QueryBuilders.wildcardQuery("user", "ki*hy"); 269 searchFunction(queryBuilder); 270 } 271 272 /** 273 * 嵌套查询, 内嵌文档查询 274 */ 275 @Test 276 public void testNestedQuery() { 277 QueryBuilder queryBuilder = QueryBuilders.nestedQuery("location", 278 QueryBuilders.boolQuery() 279 .must(QueryBuilders.matchQuery("location.lat", 0.962590433140581)) 280 .must(QueryBuilders.rangeQuery("location.lon").lt(36.0000).gt(0.000))) 281 .scoreMode("total"); 282 283 } 284 285 /** 286 * 测试索引查询 287 */ 288 @Test 289 public void testIndicesQueryBuilder () { 290 QueryBuilder queryBuilder = QueryBuilders.indicesQuery( 291 QueryBuilders.termQuery("user", "kimchy"), "index1", "index2") 292 .noMatchQuery(QueryBuilders.termQuery("user", "kimchy")); 293 294 } 295 296 297 298 /** 299 * 查询遍历抽取 300 * @param queryBuilder 301 */ 302 private void searchFunction(QueryBuilder queryBuilder) { 303 SearchResponse response = client.prepareSearch("twitter") 304 .setSearchType(SearchType.DFS_QUERY_THEN_FETCH) 305 .setScroll(new TimeValue(60000)) 306 .setQuery(queryBuilder) 307 .setSize(100).execute().actionGet(); 308 309 while(true) { 310 response = client.prepareSearchScroll(response.getScrollId()) 311 .setScroll(new TimeValue(60000)).execute().actionGet(); 312 for (SearchHit hit : response.getHits()) { 313 Iterator<Entry<String, Object>> iterator = hit.getSource().entrySet().iterator(); 314 while(iterator.hasNext()) { 315 Entry<String, Object> next = iterator.next(); 316 System.out.println(next.getKey() + ": " + next.getValue()); 317 if(response.getHits().hits().length == 0) { 318 break; 319 } 320 } 321 } 322 break; 323 } 324 // testResponse(response); 325 } 326 327 /** 328 * 对response结果的分析 329 * @param response 330 */ 331 public void testResponse(SearchResponse response) { 332 // 命中的记录数 333 long totalHits = response.getHits().totalHits(); 334 335 for (SearchHit searchHit : response.getHits()) { 336 // 打分 337 float score = searchHit.getScore(); 338 // 文章id 339 int id = Integer.parseInt(searchHit.getSource().get("id").toString()); 340 // title 341 String title = searchHit.getSource().get("title").toString(); 342 // 内容 343 String content = searchHit.getSource().get("content").toString(); 344 // 文章更新时间 345 long updatetime = Long.parseLong(searchHit.getSource().get("updatetime").toString()); 346 } 347 } 348 349 /** 350 * 对结果设置高亮显示 351 */ 352 public void testHighLighted() { 353 /* 5.0 版本后的高亮设置 354 * client.#().#().highlighter(hBuilder).execute().actionGet(); 355 HighlightBuilder hBuilder = new HighlightBuilder(); 356 hBuilder.preTags("<h2>"); 357 hBuilder.postTags("</h2>"); 358 hBuilder.field("user"); // 设置高亮显示的字段 359 */ 360 // 加入查询中 361 SearchResponse response = client.prepareSearch("blog") 362 .setQuery(QueryBuilders.matchAllQuery()) 363 .addHighlightedField("user") // 添加高亮的字段 364 .setHighlighterPreTags("<h1>") 365 .setHighlighterPostTags("</h1>") 366 .execute().actionGet(); 367 368 // 遍历结果, 获取高亮片段 369 SearchHits searchHits = response.getHits(); 370 for(SearchHit hit:searchHits){ 371 System.out.println("String方式打印文档搜索内容:"); 372 System.out.println(hit.getSourceAsString()); 373 System.out.println("Map方式打印高亮内容"); 374 System.out.println(hit.getHighlightFields()); 375 376 System.out.println("遍历高亮集合,打印高亮片段:"); 377 Text[] text = hit.getHighlightFields().get("title").getFragments(); 378 for (Text str : text) { 379 System.out.println(str.string()); 380 } 381 } 382 } 383 }
elasticsearch查询api:match query:
match query
- 与term query不同,match query的查询词是被分词处理的(analyzed),即首先分词,然后构造相应的查询,所以应该确保查询的分词器和索引的分词器是一致的;
- 与terms query相似,提供的查询词之间默认是or的关系,可以通过
operator属性指定; - match query有两种形式,一种是简单形式,一种是bool形式;
match query VS match_phrase query
注意其差别:
- match query:会对查询语句进行分词,分词后查询语句中的任何一个词项被匹配,文档就会被搜索到。如果想查询匹配所有关键词的文档,可以用and操作符连接;
- match_phrase query:满足下面两个条件才会被搜索到
- (1)分词后所有词项都要出现在该字段中
- (2)字段中的词项顺序要一致

 浙公网安备 33010602011771号
浙公网安备 33010602011771号