MySQL相关及执行计划-explain
最近开发时,配合数仓,进行数据展示及处理,这种情况下的数据量呈增量,且原数据不变,不断增加,那么在进行开发时,就必须考虑sql查询等的影响,无论是增加索引,还是优化sql本身,都是必须要做的事情,但是如何知道sql优化是所期望的呢?想到了MySQL 执行计划 -- Explain,但是其中部分字段还是一知半解,于是就有了这篇博文哈。
设计表 - 主键
是否是数值自增还是字符串?
主键是用来定位该表中,记录的唯一性,同时也可以用其来做外键关联其他表数据。
1. 如果使用数值自增(bigint unsigned),可以很好的保障每次增加的数据进行ID排序查询的顺序性,这样能够很好地处理数据信息。
对于Mysql来说,主键与索引也是相关的,数值型使用auto_increment进行自增,除了该点,字符串无法使用数据库的这种默认的自增规则;
还有一点与索引结构相关,而索引结构又与效率相关,MySQL使用B+Tree作为索引的结构,使用自增,插入数据最多只会引起节点的裂变,而使用字符串则有可能插入到任何地方,这种随机性不可控,有可能引起节点的移动与分裂,尤其是插入、查询数据时,字符串之间的顺序比较也比数值型的慢。
2. 如果使用字符串作为主键,当然随机字符串(UUID)这种的肯定不行,原因请参考 第1点,但是如果该字符串可以保证指定长度,且肯定是逐渐增长的值,那么对于特殊的业务需求,这种的也是可取的,类似于redis生成的主键,雪花算法、MongoDB生成的ID,这种在分布式系统中可以生成的全局唯一的ID,且同样也是增长的。
具体的还是参考业务本身,如果只是表示唯一性,而不对用户进行展示等,使用数值型是个不错的选择,如果需要对用户透出,那使用字符串可自行增长是较好的选择(强迫症绝佳选择)。
小白提问:为什么雪花算法与Mongo生成的ID,肯定是全局唯一且自增的字符串呢? (这个百度一下吧,生成规则基本上都是 时间戳+机器码ID+序列号 如果长度规定之后,随时间的变化,该值肯定是自增的)

索引
索引,及如何添加?
索引,对大多数场景,有简单的了解,基本上可以应对了,但是万一遇到剩下的可能性呢?这就有点无奈了。 此处只介绍概念,具体什么的可以查看其他博主的博文,就不细致介绍了
索引之于表,相当与目录之于书籍,这么理解是不是非常清晰了,实质上就是一种不断缩减查询范围的一种手段罢了,对于全表查询,效率能够更高一些,除了查询表记录头部记录外,查询其他元素都需要挨个查询,这样效率太低了
索引结构为B+Tree,树状结构能够很好的满足百万级数据量的查询,问为什么? 这个问题很难吗? 百度一下吧,看看这种结构就清楚了。
mysql中的primary key, index,unique,联合唯一也都是索引,这些索引除了加速查找以外,还有约束的功能。
对于一张表结构,其索引的数量最好不超过6个,还有就是尽量使用联合索引,最左浅醉(前缀)原则也是很有用的哇。
遇到一个问题: 表中有5个字段,每个字段值分布很少,或基数很少,也就是只为 01,02,03这种的类似于状态值的字段值,这种是否需要对该字段添加索引呢?
查看了一些博文以及自己的理解,最终的结论是:通常是不用索引,但是如果值的记录行分布概率差别过大,查询概率小的数据为主,这个时候就需要加上索引。
原因:1、假如值的分布是均匀的,那么查询的概率基本上都是50%,33%...这种,可以不用对该字段增加索引,全文查询与增加索查询的效率提升并非很大,通常来说,终端SQL查询时间在100ms是可以接受的
2、假如值的分布不均匀,这样存在两种情况:
①、如果类似于逻辑删除标记之类的,且没有删除的数据量占比重大,那查询时全文检索同样是可以接受的;
②、如果类似于状态生效标记之类的,且生效的数据比重较少,如订单状态等等,那查询时就需要针对这种占比重少的数据进行整理,而索引本身就是排序,这样操作比全文检索效率会有很大的提升,此时必须加索引。
举例:如在一所高校中,查询是否是学生的人,是不是一抓一大把? 但是如果在高校中查询领导级别的人,这种情况是不是先按照层级排序,再查询能够更快一些.......(好像不是很恰当,但是可以理解的吧.....)
索引的结构等详细信息后续可以补充哈,本期就不涉及过多了... ...(索引)
子查询
嵌套子查询 相关子查询 ?
子查询实质上就是在一个查询内部使用了另一个查询的结果,不过这个有可能是另一个查询的条件,又或是另一个查询的依赖,所以进行区分。
1. 嵌套子查询 --- --- 嵌套子查询的执行不依赖与外部的查询。执行过程:
(1)执行子查询,其结果不被显示,而是传递给外部查询,作为外部查询的条件使用。 (2)执行外部查询,并显示整个结果。
例:select 用户id, 用户名称, 用户手机号, 用户地址 from user where 用户id in ( -----订单时间大于2020-01-01的用户信息
select 用户id from order where 订单时间 > '2020-01-01' )
2. 相关子查询 --- --- 相关子查询的执行依赖于外部查询。多数情况下是子查询的WHERE子句中引用了外部查询的表。执行过程:
(1)从外层查询中取出一个元组,将元组相关列的值传给内层查询。 (2)执行内层查询,得到子查询操作的值。
(3)外查询根据子查询返回的结果或结果集得到满足条件的行。 (4)然后外层查询取出下一个元组重复做步骤1-3,直到外层的元组全部处理完毕。
例:select 用户id, 订单id from order i where 支付金额 = ( -------- 查询每种支付金额最大的用户订单信息
select max(支付金额) from order j where i.订单类别 = j.订单类别)
EXPLAIN
执行计划?
使用EXPLAIN关键字可以模拟优化器执行SQL查询语句,从而知道MySQL是 如何处理你的SQL语句的。分析你的查询语句或是表结构的性能瓶颈。
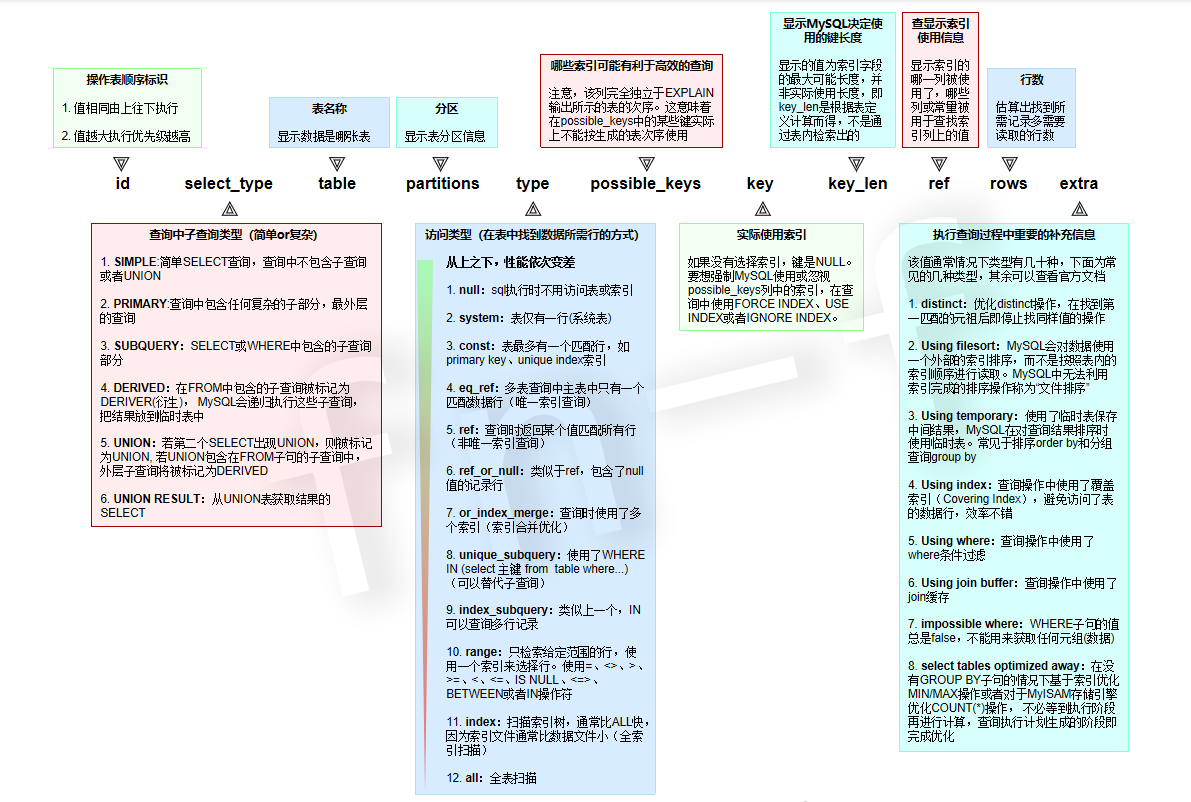
从上面可得知:
优点: explain执行计划可得知:查询SQL的相关执行顺序、读取数据的类型与实际使用的索引、被查询的行数等等信息。
缺点:explain执行计划局限性:执行查询语句时的具体优化情况、部分数据是估算的并非准确值、不会告知缓存,存储等信息的影响、除select外的其他语句不支持
(开发使用普遍的技术,自我提升呢?需要稍深入研究,不然与他人差距如何表现呢? ------ fn)
