
7.2 客户端与服务器交互
Redis实例运行在单独进程,系统和Redis通过Redis协议进行交互。
Redis协议上,客户端和服务器可以实现多种典型的交互模式:
- 串行的请求/响应模式
- 双工的请求/响应模式(pipeline)
- 原子化的批量请求/响应模式(事务)
- 脚本化的批量执行(脚本模式)
7.2.1 客户端/服务器协议
交互协议分为两部分:
- 网络模型:讨论数据交互的组织方式
- 序列化协议:数据本身如何序列化
1.网络交互
Redis协议位于TCP层之上,即客户端和Redis实例保持双工的连接,如图:
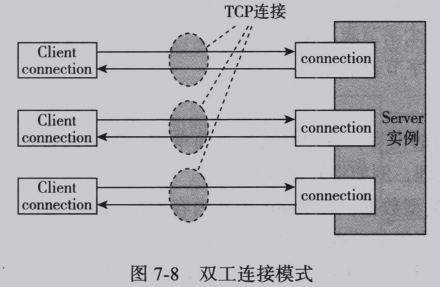
客户端和服务器交互的内容是序列化后的相应类型的协议数据,服务端为每个客户端建立对应的连接,在应用层维护一系列状态保存在connection中,connection间相互无关联。在Redis中,connection通过redisClient结构体实现。
2.序列化协议
客户端和服务器交互的内容是序列化后的相应类型的协议数据
Redis中,协议数据分为不同的类型,每种类型的数据均以CRLF(\r\n)结束,通过数据的首字符区分类型。
(1)inline command
表示Redis命令,首字符为Redis命令名的字符,如: “EXISTS key1”,首字符'E',表示检查key1是否存在。命令参数以空格分隔(????????????)
(2)simple string
首字符 ‘+’ ;后续字符为string内容,且该string不能包含‘\r'或'\n’ 两个字符;最后以'\r\n'结束。例如:“+OK\r\n”这5个字节,表示“OK”这个string数据。
simple string 本身不包含转义,所以客户端的反序列化效率很高,直接将‘+’和最后两个字节“\r\n”之间的内容拷贝即可。
(3)bulk string
simple string 不适用包含‘\r’或‘\n’的情况。通常有两种方法解决:转义和长度自描述。
转义需要遍历每一个字节,效率低下,Redis采用后者,称为“bulk string”
bulk string 首字符为‘$’,紧跟的是string数据长度,‘\r\n’后是string内容(内容可以包含'\r\n'在内特字符),最后以“\r\n”结束。例如:“$12\r\nhello\r\nworld\r\n”,这19个字节描述了 “hello \r\n”这两行字符串。
对于“ ”空字符串和null,通过‘$’后数字进行区分:
“$0\r\n\r\n” 6个字节表示空字符串。
“$-1\r\n” 5个字节表示null。
(4)error
error 的首字符为 ‘-’ 客户端通过首字符直接可判断本次交互是否出错。
如:“-ERR unknown command ‘foobar’\r\n”。
有的客户端需要对不同种类的error分别做不同处理,为了使得error种类的区分更加快速,在Redis序列化协议上层,还包含一个简单的error格式协议,以error种类开头。
(5)integer
以‘:’ 字符开头,紧跟整形数字本身,以'\r\n'结束。如: “:13\r\n”表示13这个整数。
(6)array
以 “ * ” 字符开头,紧跟数组长度,“\r\n”后是数组元素的序列化数据。如:“*2\r\n+abc\r\n:9\r\n”
13个字节表示["abc",9]。
数组长度为0或-1分别表示数组空或null
数组元素也可以是数组,多级数组是树状结构,采用类似现需遍历的方式序列化:[[1,2],["abc"]],序列化为: “*2\r\n*2\r\n:1\r\n:2\r\n*1\r\n+abc\r\n”。
(7)C/S两端使用的协议数据类型
客户端发送给服务端类型为:inline command 、由bulk string 组成的array
服务端发送给客户端类型为:inline command之外所有类型,并根据客户端命令或交互模式不同确定。如:
请求/响应模式下,客户端发送EXISTS key1 ,返回integer型数据。
发布/订阅模式下,对channel订阅者推送的消息,采用array型数据。
7.2.2 请求/响应模式
对7.1节所述数据结构的基本操作,都是通过请求响应模式完成的。
同一个连接上,请求/响应模式如下:
交互方向:客户端发送请求数据,服务器发送响应数据。
对应关系:每个请求数据有且仅有一个对应的响应数据。
时序:响应数据的发送发生在“服务器完全接收到其对应的请求数据”之后。
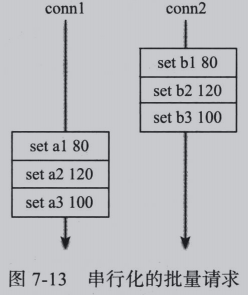
1.串行化实现
最简单的实现方式为串行化实现,即同一个连接上,客户端收完第一个请求的响应后,在发起第二个请求,如图:
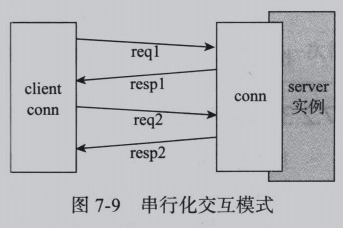
问题:同一个连接的每秒吞吐量低:
单链接吞吐量= 1 / (2 * 网络延迟 + 服务器单请求处理时间 + 客户端单请求处理时间 )
Redis对单个请求的处理时间通常比局域网的延迟小一个数量级,因此串行化模式下,単连结大部分时间都处于网络等待,没有充分利用服务器处理能力。
2.pipeline实现
由于依赖的TCP协议是全双工的,请求/响应即便穿插进行,也不会发生请求和响应数据的混淆,因此可将请求数据批量发送到服务器,再批量从服务器连接的字节流中依次读取每个响应数据,可极大提高単连接吞吐量,如图:
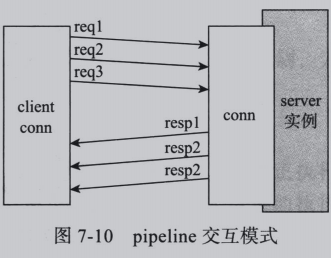
这种模式适合批量的独立写入操作(每次写入数据不依赖上次请求的执行结果)。上图中req全部结束后返回response,实际中两者可能穿插,如下图:
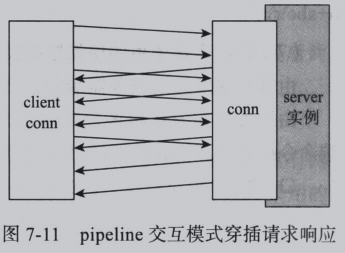
这种不等上一次结构返回就发送下一次请求的模式成为pipeline。
pipeline的实现取决于客户端,需要考虑一下方面:
通过批量请求发送还是异步化请求发送来实现。
非异步化的批量发送下需要考虑每个批次数据量,避免连接buffer满后死锁。
对使用者如何封装接口,使得pipeline使用简单。
pipeline能达到的単连接每秒最高吞吐量为:(???)
(n - 2 * 网络延迟 ) / (n * (服务器单请求处理时间 + 客户端单请求处理时间))
时间单位是秒。n无穷大时:
1 / (服务器单请求处理时间 + 客户端单请求处理时间)
7.2.3 事务模式
pipeline模式对于Redis服务器端来讲和普通的请求/响应模式没有太大区别,仅仅是客户端提交请求的时序控制做到了不依赖前置请求的响应结果。
当同时存在多个客户端时,一个客户端批量发送的每一条命令和另一个客户端的命令在Redis服务器端看来是同等的,其执行顺序可能存在交叉,类似于多个串行请求/响应模式的客户端并发发送命令的效果,如图:
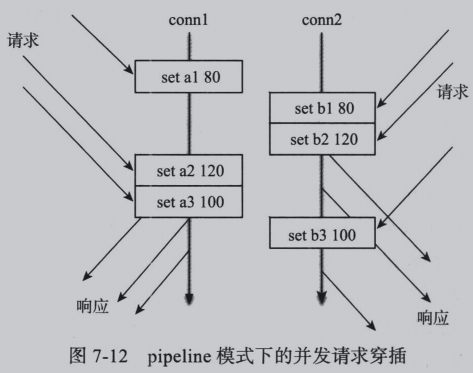
当需要批量执行的语句原子化时,需要引入Redis的事务模式,达到下图所示的效果。
一次事务中的多条命令以原子化的方式执行,不同事务的命令相互时序不再交叉。
1.入队/执行分离的事务原子性
客户端通过和redis服务器两阶段的交互做到批量命令原子化执行的事务效果:
入队阶段:客户端将请求发送到服务器端,后者将其暂存在连接对象对应的请求队列
执行阶段:发送完一个批次的所有请求后,Redis服务器依次执行连接对象队列中的所有请求。由于单个实例的Redis仅单线程执行所有请求(后文介绍),一个连接的请求在执行批量请求的过程中,不会执行其他客户端的请求。
由于Redis执行器单线程的一次执行的粒度是“命令”,所以为了让批量的请求一次性全部执行,引入“批量执行命令”: EXEC。
一次原子化批量执行的客户端/服务器交互过程,如下图:
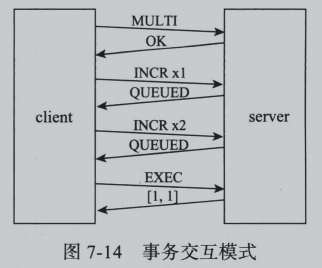
MULTI开启事务,随后发送的请求暂存在服务器端的连接上,最后通过EXEC一次性批量执行(发生实际的数据修改),并将所有执行结果作为一个响应,以array类型的协议数据返回给客户端。
2.事务一致性
入队阶段出现语法错误,不执行后续EXEC,不会对数据产生实际影响。
执行阶段一条请求执行失败,后续请求继续执行,只在返回客户端的array型响应中标记这条出错的结果,由客户端应用程序决定如何恢复,Redis自身不包含回滚机制(执行到一半的批量操作必须继续执行完)。
回滚机制的缺失使得Redis事务极大简化:无需为事务引入数据版本机制,无须为每个操作引入逆向操作。严格来讲,Redis事务不是一致的
3.事务的只读操作
只读操作放在批量执行中没有任何意义:它的结果不会改变事务的执行行为、也不会改变Redis的数据状态。所以入队的请求应该全是写操作。
但是一个事务经常需要只读操作,用来控制事务流程或作为后续操作参数。如a给b转账10元,如下:
GET a
GET b
MUTI --OK
SET b 100 --QUEUED
SET a 90 --QUEUED
EXEC --[1,1]
入队模式下所有操作返回的只是是否入队成功,只读操作无法在此状态下获取真正的数据结果,所以一个完整的业务事务,其只读操作需放到MULTI语句前执行。(???)
上面两条GET操作和EXEC是作为三条独立命令执行的,他们之间可能会穿插别的客户端的其他语句,如下:
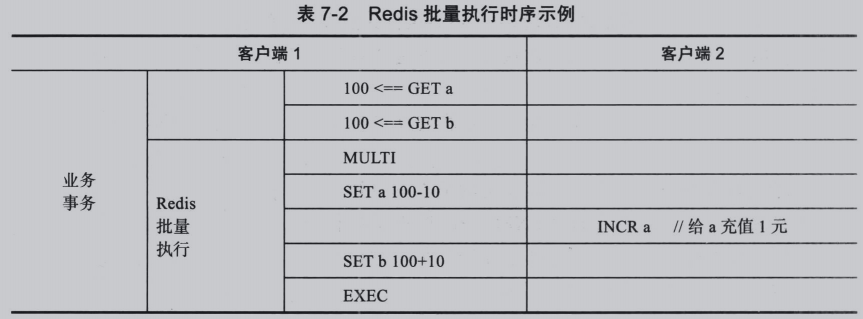
客户端2对a的操作被客户端1的事务覆盖了,导致数据不一致。
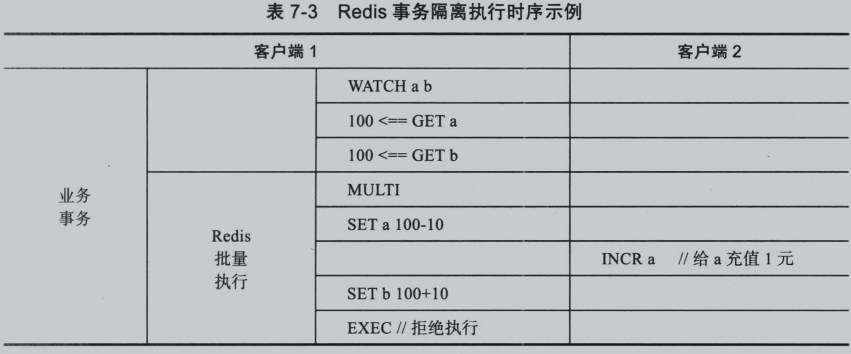
4.乐观锁的可串行化事务隔离
Redis通过WATCH机制实现乐观锁解决上述一致性问题:
- 将本次事务设计的所有key注册为观察模式,假设此时逻辑时间为tstart
- 执行只读操作
- 根据只读操作的结果组装写操作命令并发送到服务器端入队
- 发送原子化的批量执行命令EXEC视图执行连接的请求队列中的命令,假设此时逻辑时间为tcommit。
- 执行时有两种情况:
- tstart到tcommit之间注册为观察模式的key被修改,EXEC直接失败,拒绝执行。
否则顺序执行请求队列的所有操作。
5.事务实现
事务状态保存在redisClient中,通过两个属性控制:
typedef struct redisClient{
...
int flags;
multiState mstate;
...
} redisClient;
flags包含多个bit,其中两个bit分别标记了:当前连接处于MULTI和EXEC间、当前连接WATCH之后到现在它所观察的key是否被修改过;
mstate结构如下:
typedef struct multiState{
multiCmd *commands; // 连接的请求队列
int count; //标记MULTI到EXEC间共有多少个待执行命令
...
} multiState;
watch机制通过维护redisDb中的全局map来实现:
typedef struct redisDb{
dict *dict;
dict *expires;
dict *blocking_keys;
dict *ready_keys;
dict *watched_keys;
struct evictionPoolEntry * eviction_pool;
int id;
long long avg_ttl;
} redisDb;
map的键是被watch的key,值是watch这些key的redisClient指针的链表
每当redis执行一个写命令时,他会同时对执行命令的key在watched_keys中找到对应的client并将后者flag对应位置改为REDIS_DIRTY_CAS,后续这个client在执行EXEC前如果看到自己的flag对应位有REDIS_DIRTY_CAS标记,则拒绝执行。
事务的结束或显示UNWATCH都会重置redisClient中的REDIS_DIRTY_CAS标记并从redisDb对应watch_keys中的链表删除自己。
6.事务交互模式
综上,一个连接的事务,交互模式如下:
客户端发送四类请求:监听相关(WATCH、UNWATCH)、只读请求、写请求的批量执行或放弃执行请求(EXEC/DISCARD)、写请求的入队(MULTI和EXEC/DISCARD之间)
交互时序为:开启对读写主键的监听、只读操作、MULTI请求、根据前面读操作的结果编排/参数赋值/入队写操作、一次性批量执行队列中的写请求。
通过上述模式,事务隔离级别可以到到串行化级别:
其他类似的方式如快照隔离常见的write skew问题,都可通过Redis的watch机制解决
由于Redis没有原生的悲观锁或者快照实现repeatable read,fuzzy read 的问题通过乐观锁绕过了
Redis的执行器是单线程的,所以写操作的执行本身就是通过串行的方式实现的可串行化。
7.2.4 脚本模式
1.脚本交互模式
客户端发送eval lua_script_string 2 key1 key2 first second 给服务器端
服务器解析lua_script_string并根据string本身的内容通过sha1计算出sha值,存放在redisServer对象的lua_scripts成员变量中,它为map类型,sha作为键。
服务器端原子化地通过lua环境执行lua_script_string,后者可能包含对Redis的方法调用比如set key等命令。
执行完成后将lua的结果转化为Redis的类型返回给客户端。
2.script特性
每一个提交给服务端的lua_script_string都会在服务器端lua_script_map中常驻,除非显式通过FLUSH命令清除。
script在实例的主备间可通过script重放和cmd重放两种方式复制(???)
之前执行过的script后续可直接通过它的sha指定而不用再向服务器端发送一遍script内容。
7.2.5 发布/订阅模式
1.发布/订阅交互模式
角色关系:
客户端分为发布者和订阅者
发布端和订阅者通过channel关联
交互方向:
发布者和Redis服务器的交互仍为请求/响应模式
服务器向订阅者发送数据(推送)
时序:推送发生在服务器收到发布者消息后
2.两类channel
普通channel
pattern channel
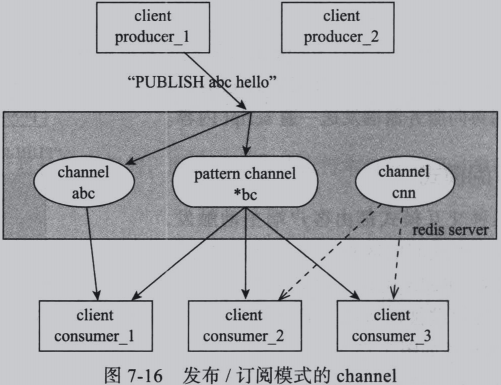
client2同时订阅普通channel abc和pattern channel *abc,当发布者向abc发来消息时,redis server 发给abc这个普通channel上的所以有订阅者,同时,abc也匹配上了pattern channel的名字,所以该消息也会同时发给pattern channel *bc上的所有订阅者。
3.订阅关系实现
channel的订阅关系,维护在Redis实例级别,独立于redisDb的key-value体系,由如下两个变量维护:
typedef struct redisServer{
...
dict *pubsub_channels;//普通channel和订阅者的关系:键是channel的名字,value是订阅者client的指针链表
list *pubsub_patterns;//pattern channel和订阅者的关系:...
...
};
发布者向某个channel 发布消息时,redis先从pubsub_channels中找到对应的value,向它的所有client发送该消息;同时,遍历pubsub_pattern列表,向能够匹配到的元素的client也发送该消息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号