7.1 数据结构
7.1.1 value 对象的通用结构
typedef struct redisObject{
unsigned type:4;
unsigned encoding:4;
unsigned lru:REDIS_LRU_BITS;
int refcount;
void *ptr;
} robj;
type指String、List等结构类型。
- encoding指这些结构化类型具体的实现(承载)方式,同一个类型可以有多种实现,例如String可以用int来承载,也可以用封装的char[]来承载,List可以用ziplist或者链表来承载。
- lru 表示本对象的空转时长,用于有限内存下长久不访问的对象的清理。
- refcount 是应用计数用于对象的垃圾回收。
- ptr 指向的是以encoding方式实现这个对象的实际承载者的地址,如string对象对应的是sds地址。
7.1.2 String
三种类型:
- 字符串
- 整数
- 浮点数
1.基本操作
2.内存数据结构
以int、SDS(simple dynamic string)作为结构存储。
int存放整形数据,sds存放字节/字符串和浮点型数据
1)sds结构
typedef struct sdshdr{
unsigned int len;
unsigned int free;
char buf[];
}

\0 在redis实现中仅作为字符串定界符,不表示业务数据内容不能包含\0字符。如上图sds的bufSize为8,len为5,free为2。
2)buf的扩容与缩容
字符串初始化时,buf的大小=len+1,即加上定界符\0刚好等于业务数据的长度
当字符串操作完成后预期的长度小于1MB时,扩容后的buf大小=业务串预期长度*2+1,即不考虑\0 ,buf加倍
对大于1MB的长串,buf总是流出1MB的free空间,即buf以业务串的2倍来扩容,但最大留出1MB的空间。
3)字符串与字节串
sds中存储的内容可以是ASCII字符串,也可以是字节串。由于sds通过len字段来确定业务串的长度,业务串可以存储非文本内容
7.1.3 List
1.基本操作
2.内存数据结构
List类型的value对象内部以linkedlist或ziplist承载。当List的元素个数和单个元素的长度较小时,Redis会采用ziplist实现减少内存,否则使用linkedlist结构。
3.linkedlist实现
双向链表实现,
typedef struct list{
listNode *head;
listNode *tail;
void *(*dup) (void *ptr);
void (*free) (void *ptr) ;
int (*match) (void *ptr , void *key);
unsigned long len;
} list;
typedef struct listNode{
struct listNode *prev;
struct listNode *next;
void *value;
} listNode;
list的定义了头尾元素指针和列表长度,所以POP/PUSH操作、LLEN操作的复杂度为O(1)。因为是链表,LINDEX类的操作的复杂度仍是O(N)
4.ziplist实现
1)列表结构
List的所有内容被放置在连续的内存中,结构如下:
<zlbytes><zltail><zllen><entry><entry>...<zlend>
zlbytes表示ziplist的总长度;zltail表示最末元素;ziplist是连续内存,所以实际zltail的值是最末元素距离ziplist头的偏移量;zllen表示元素个数;后续每个<entry>即元素自身内容,是自包含的;zlend恒为0xFF作为ziplist的定界符。
ziplist对于获取RPUSH、RPOP、LLEN等操作复杂度为O(1)。LPUSH/POP涉及全列表元素移动,复杂度为O(N),但是ziplist用于元素个数较少,N本身不大。
2)元素结构
每个entry包含两部分:
- 相邻的前一个entry的长度
- 自描述的本entry内容
前邻entry长度记录的作用是方便实现双向遍历,类似linkedlist的节点prev指针。
偏移量即前一个entry的长度-1,故直接记录长度。entry长度大于255需要超过1字节来表达。Reids支持最多5个字节来表达前邻entry长度,大多情况entry长度不会超过200,总是用5个字节会浪费存储。所以,Redis设计两种长度的长度实现,相邻entry的长度小于254时,其length用1字节存放,否则用5字节。
有一个问题:当前邻长度变化时,本entry长度也可能变化,从而引起本entry后一个相邻entry长度变化,以此类推。当然这二种情况概率极小。
entry本身的业务内容是自描述的,意味着第二部分包含了几个信息:本entry的内容类型、长度、和内容本身。
类型和长度同样采用变长编码:


可见ziplist的元素结构采用可变长度的压缩方法,针对值较小的整数、较短string具有较好的压缩效果。
1.4 Map
map内部的key和value不能再嵌套map了,只能是String类型所能表达的内容:整形、浮点型、字符串。
1.基本操作
2.内部结构
map可应用hashtable和ziplist两种承载方式来实现。对于数据量小的map,采用ziplist实现。
3.hashtable实现
哈希表在Redis中分为三层,自底向上分别是:
- dictEntry:管理一个key-value对,同时保留同一个桶中相邻元素的指针,一次维护哈希桶的内部链
- dictht:维护哈希表的所有桶链
- dict:当dictht需要扩容/缩容时,用于管理dictht的迁移。
1)哈希表
哈希表的核心结构是dictht,它的table字段维护着hash桶,它是一个数组,每个元素指向桶的第一个元素(dicEntry):
typedef struct dictht{
dictEntry **table;//数组
unsigned long size;//桶个数
unsigned long sizemask;//size-1
unsigned long used;//当前hash表存储了多少个键值对
}
由于桶的个数永远是2的n次方,可以用size-1做位运算&快速得到哈希值的模,所以dictht中引入了sizemask,其值恒等于size-1。
2)扩容
根据负载因子判定是否需要增加桶数,负载因子=哈希表中已有元素和哈希桶数的比值,目前有两个阀值:
- 小于1时一定不扩容;
- 大于5时一定扩容;
- 介于1到5之间时,Redis如果没有进行bgsave/bdrewrite操作时则扩容。
如果有大量空桶需要缩容,Redis同样根据负载因子决定是否缩容,目前的缩容阀值是0.1。
无论是扩容还是缩容,桶的数量都是指数变化:扩容时新的桶数秒是现有桶的2n倍,扩到刚好大于used值(??),缩容后新的桶是原有的0.5n倍,也是缩到刚好大于used值(??)。
扩/缩容通过新建哈希表的方式实现。扩容时存在两个hash表,一个源表,一个目标表。将原表迁移到目标表,迁移完成后,目标表覆盖原表。
dict对象维护着哈希表的迁移状态:
ypedef struct dict{
dictType *type;
void *privdata;
dictht ht[2];
long rahashidx;
int iterators;
} dict;
ht[0]代表源表,也是正常情况下访问的表。仅在迁移过程中,ht[1]可用,作为目标表。
此时首先访问源表,如果发现key对应的通已经完成迁移,则重新访问目标表,否则在源表中操作。
dict通过rehashindex记录已经完成迁移的通。如下图:
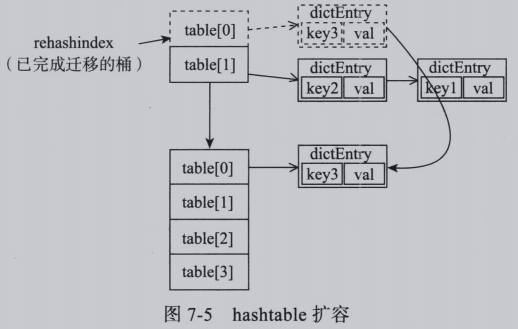
由于Redis是单线程处理请求,迁移和访问的请求在相同线程内时分复用地进行,因此迁移过程中不存在并发问题。结构性value的并发问题也无须加锁进行(后续7.4节详细介绍)
4.ziplist实现
这里的ziplist和list的ziplist实现类似,都是通过entry存放element。和List不同的是,map对应ziplist的entry个数总是2的整数倍,第奇数个entry存放key,key对应entry的下一个相邻entry存放该key对应的value。
ziplist实现下,map的大多数操作的复杂度不再是O(1)了,由哈希遍历变成链表的顺序遍历,复杂度编程O(N)。但由于采用ziplist的map大小通常偏小,所以性能损失可控。通常情况下,只有很少几个kv对的map,采用ziplist效率反而更高,省去hash计算、内存寻址等操作。尤其对于长字符串key,其hash值计算本身的开销甚至远大于顺序遍历时字符串比较的开销。(hash不一定比链表优越,具体问题具体分析)
7.1.5 Set
Set类似List,它是一个无序集合,元素不重复。
1.基本操作
2.内存结构
Set在Redis中以intset或hashtable来存储。hashtable前面介绍了,对于Set,hashtable中的value永远为NULL。当set中只包含整数类型的元素时,采用intset作为实现。
3.intset
intset的核心元素时一个字节数组,其中从小到大有序存放着set的元素,length和encoding分别表示元素个数和每个元素编码方式。编码方式指定了一个整型元素占用多少个contents数组位:
typedef struct intset{
uint32_t encoding;
uint32_t length;
int8_t contents[];
} intset;
由于元素有序排列,所以set的获取操作采用二分查找方式实现,复杂度O(log(N))。
插入操作,首先通过二分查找得到插入位置,在扩容,将预计位置后的元素后移一位,插入元素。插入复杂度为O(N)。删除操作类似。
为了使二分查找速度足够快,存储在content中的元素应该是定长的,即所有的元素占用content数组相同的格子。
如果set中所有元素值都在[-128,127]中,那么所有元素使用一个content位存储。如果Set中大于127的整数,和在[-128,127]中的整数并存,所有元素采用最大需要的字节数来存储,这就意味着,突然插入一个大整数(需要两位存储或更多)时,intset中原有的所有元素需要将占用字节数升级为2字节。这个过程设计全集合的移动。因为引起升级的元素一定大于(或小于)全部已有元素。所以新插入位置在头或者尾部。原有元素的移动过程可以只在单个数组内部进行。如图:
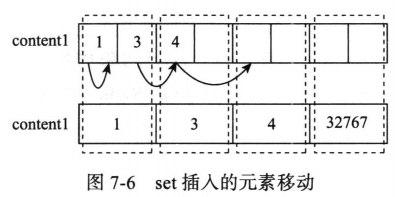
原有元素从后往前移动,移动过程不会发生覆盖。
intset针对小整数进行了性能优化,对不同类型的整数采用变长的存储,在元素均不大的情况下减少了内存开销。
7.1.6 Sorted-Set
Sorted-Set是redis特有数据类型,类似Map是一个key-value对,但是它是有序的:
key:键,不重复
value:一个浮点数,称为score
有序:sorted-set内部按照score从小到大排序。
1.基本操作
2.内存数据结构
Sorted-set类型的value对象内部以ziplist或skiplist+hashtable来实现。
ziplist的实现方式和map类似。由于sorted-set包含score的排序信息,ziplist内部的key-value元素对的排序方式也是按照score顺序递增排序的,意味着每次新元素插入都需要移动后面元素。因此ziplist适用于元素不多、元素内容不大的场景。
对于更通用的场景,sorted-set采用skiplist(跳表)来实现。
3.skiplist
和通用跳表实现不同,Redis为每一个level对象增加了span字段,表示该level指向forward节点和当前节点的距离,使用getByRank类的操作效率提升,skiplist定义如下:
typedef struct skiplist{
struct zskiplistNode * header,*tail;
unsigned long length;
int level;
} zskiplist;
如图:
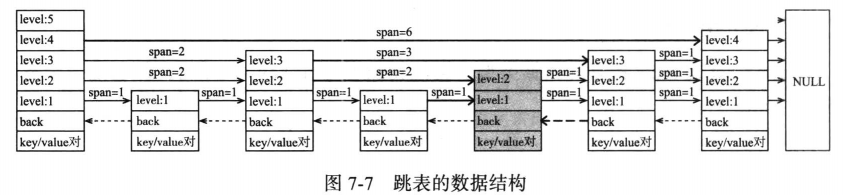
每次向skiplist新增或删除一个元素(如图中灰色元素),需要同时修改图中标粗的箭头,修改其forward指针和span字段值。可见,需要修改的箭头和skip进行查找操作遍历并废弃过的路径吻合,对span的修改仅仅是加1或减1(取决于是增加还是删除操作)。skiplist的查找复杂度平均是O(Log(N)),因此add/remove的复杂度也是O(Log(N))。因此redis新增span没有带来更多的复杂度和性能牺牲,同时提升了rank类的操作速度:求某一个元素在skiplist中的排名,仅需将遍历路径上的span相加。
skiplist每个节点的高度随机性,这点和通用的skiplist实现类似。
4.hashtable
跳表示一种实现顺序相关操作较高效的数据结构,但是他对于简单的ZSCORE操作效率并不高,Redis在实现sorted-set时,同时使用hashtable和skiplist,它的结构如下:
typedef struct zset{
dict *dict;
zskiplist *zsl;
} zset;
hashtable的存在使得sorted-set中的map特性操作复杂度从O(N)降低为O(1)。
Redis 还支持位图(Bitmaps)数据结构,在 2.8 版本之后,增加了基数统计(HyperLogLog),3.2 版本之后加入了地理空间(Geospatial)以及索引半径查询的功能,在 5.0 版本引用了数据流(Streams)数据类型。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号