
5.4 Memcached客户端分析
本节会对Java的Spymemcached客户端进行详细的分析
5.4.1 Memcached的Client
主要功能点:
- Memcached协议封装
- 连接池实现
- sharding机制
- 故障转移
- 序列化机制
5.4.2 Spymemcached设计思想解析
Java中最常用两大客户端,Spymemcached和Xmemcached,以下主要介绍Spymemcached设计与实现。
Spymemcached主要特性:
- memcached协议完善支持,同时支持Text和Binary协议
- 异步:NIO作为底层通信框架
- 集群:默认支持服务器集群的sharding机制
- 自动恢复:网络闪断,会异步重连,自动恢复
- failover机制:提供可扩展的容错机制
- 支持批量get:本地进行数据的聚合
- 序列化:默认支持JDK序列化机制,可自定义扩展
- 超时机制:支持访问超时等设置
1.整体设计
如图:
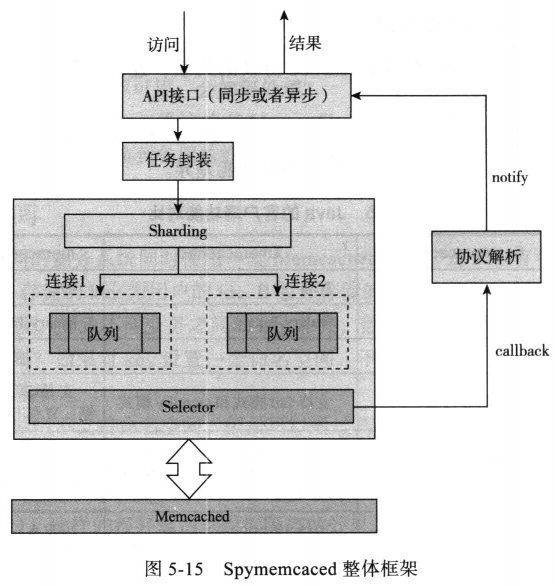
- API接口:对外提供同步和异步接口调用。
- 任务封装:将访问的操作及callback封装为Task
- 路由机制:通过默认的Sharding策略(支持arrayMod和Ketama),选择key对应的连接(connection)
- 将Task放到对应连接的队列。
- Selector线程异步获取连接队列的Task,进行协议的封装及发送。
- 收到Memcached返回的包,找到对应的Task,调用callback进行回调,对返回的结果进行协议的解析,并进行序列化。
2.API接口设计
对外的API接口一般是Memcached协议的原生命令进行封装,如调用get(userid)接口,实际客户端会转换为get userid 命令发送到Memcached服务器。
对外API接口一般有两种:同步接口和异步接口。同步接口返回数据(阻塞获取数据,一般性能较差),而异步返回future(一步获取数据,socket收到响应数据后,会进行回调通知)。
调用异步asyncGet接口返回future,调用future.get(timeout)来阻塞获取数据。如果应用是同步的,使用异步不能提升性能,所有的业务线程还是会阻塞,且会造成线程上下文切换,性能反而比同步差。只有应用是纯异步的,异步才能发挥价值。
3.线程设计
Spymemcached主要涉及两类线程:
- 业务线程
- selector线程
业务线程的工作:
- 封装请求task,对象的序列化,封装发送协议,并将task放到对应的连接队列。
- 对收到的数据反序列化为对象
selector线程的工作:
- 读取连接的队列,将队列的task的数据发送到mc端。
- 读取mc端返回的数据,协议的处理,及通知业务线程。
- 对失败的节点进行自动重连。
使用NIO可以避免业务线程阻塞等待,提升系统吞吐能力。
4.sharding机制及容错
如果后端memcached服务时集群部署,必然会设计如何选择mc服务问题,具体结构如图:
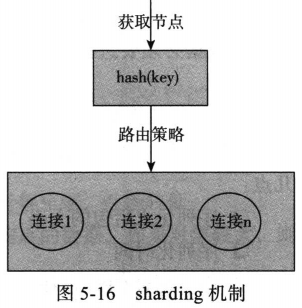
图5-16的描述核心点便是路由策略的选择。
(1)路由机制
路由是通过请求的key,选择对应的连接节点。路由机制的设计主要考虑两个方面:平衡性和单调性
平衡性:key尽可能均匀分布到所有节点
单调性:如果已经有一些内容通过哈希分派到后端缓存服务中又有新缓存服务加入到集群。哈希结果应能保证已分配的内容可以被映射到原有的或者新的缓存服务器中。取模路由策略显然不符合。
Spymemcached默认实现hash算法有:
- NATIVE_HASH:默认hash算法。使用hashCode方法计算
- CRC_HASH:使用crc32进行hash
- KETAMA_HASH:ketama的一致性hash(Spymemcached支持两种路由策略:arrayMod和ketama)
arrayMod:hash采用NATIVE_HASH,取模选择路由节点。但是取模带来了扩展性问题。比如扩容缩容,会导致大量缓存不命中。不推荐使用。
ketama:hash采用的是KETAMA_HASH,ketama算法选择路由节点。同时满足平衡性和单调性。有效解决了扩缩容带来的大量miss的问题。
(2)容错
如果key路由到服务对应的节点,但是服务节点挂掉了,该如何处理呢?
自动重连:失败节点,会从正常的队列中摘除,添加到重连队列中,定期对该节点进行重连。重连成功,在添加到正常的队列中。
failover处理:Spy默认支持三种容错机制
- Redistribute
- Retry
- Cancle
Redistribute:如果路由的是失败节点,则根据策略会选择下一个节点。直到选到正常的节点(推荐方式)。优点是一个节点挂掉,会自动failover到其他节点,容错性较强;缺点是自动failover到其他节点,导致大量回源,并且在启动的时候由于Memcached没有固化,导致再次大量回源。
Retry:如果路由的是失败节点,仍然使用该节点访问。会导致大量的访问失败。
Cancle:如果路由的是失败节点,则直接抛出异常。这会影响缓存的可用性。
5.序列化
面向对象编程中,需要操作的均是对象,但实际上存储在Memcached服务的是二进制数据,这里就涉及对象和二进制如何进行互相转换,如5-17所示。
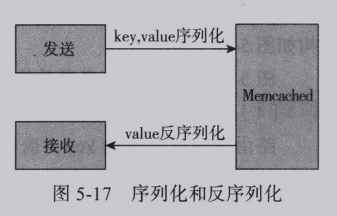
由于发送到Memcached的数据必须是二进制,所以发送的数据必须要进行序列化,同时接受的数据要进行反序列化。
序列化主要是将对象转换为二进制,反序列化是将二进制转换为对象。一般衡量序列化的性能主要有如下几点:
- 序列化后包的大小
- 序列化时间
- 序列化对CPU的损耗
- 序列化对GC的影响
Spymemcached提供自定义扩展序列化机制,只需要实现Transcoder的encode和decode接口即可。Spymemcached提供默认序列化实现,serializingTranscoder。实现的主要思路是根据不同的数据类型,使用不同的序列化方式。详情见P115。
为什么要进行压缩,为什么压缩设置一个阀值,而不是全部开启压缩?
这里可以借鉴HTTP的压缩机制,Web服务(比如Nginx或者Tomcat)在返回数据时候,判断body长度,超过一定阀值,则开启压缩,否则,不进行压缩。压缩可以继续数据报大小,但是却消耗CPU资源,需要在接收数据报和消耗CPU资源上做一个平衡。资源数据包达到一定大小的时候,才能产生网络传输和存储的瓶颈,使用没必要对全部数据开启压缩,而是需要设置一个阀值。
以下为压缩优缺点:
优点:
- 减少网络的传输
- 减少在Memcached存储的空间
压缩的缺点:
- 非常消耗CPU,在获取数据的时候,还需要进行解压缩,性能较低。
- 在压缩的时候,需要申请额外的地址空间来存储压缩后的数据,如果对象较大,则申请的空间较大,会影响GC。
如果全部不压缩,则对于大数据的情况下,会很容易导致网络或Memcached存储存在瓶颈。比如数据1M,那么1G的内存也只能存储1024个对象,并且网络的开销也很大。可以通过压缩很好地解决存储和网络的问题。
如果所有的数据全部都压缩,有压缩就有解压,两者都是很耗CPU的操作,如果频繁操作压缩解压的操作,会导致应用端CPU消耗过高,影响业务的稳定性。
所以这里设置一个阀值16384,主要是基于CPU消耗、网络和Memcached消耗的一个平均值。
Spymemcached默认实现的自定义对象序列化采用JDK序列化,性能较差。推荐使用Kyro的序列化机制。
6.反序列化
通过读取flag,确定数据的序列化方式,然后按照序列化的逆过程进行反序列化。
7扩缩容
初始化Spymemcached Client后,Spymemcached完成对所有Memcached接地那的连接。如果需要进行扩容、缩容,则需要重新修改配置,重启应用,而无法做的动态扩缩容。
如果需要动态扩容如何实现呢?
MC的集群实现主要有两种方式:
- 通过proxy实现集群
- 通过本地sharding实现集群
实现动态扩缩容考虑点:
- 操作便利性:运维可以方便往MC集群中增加或者删除实例
- 单调性:增加节点后,尽可能小影响原有数据,避免大量数据回源数据库,影响系统稳定性。
下面介绍ZooKeeper实现动态扩缩容。如下图:
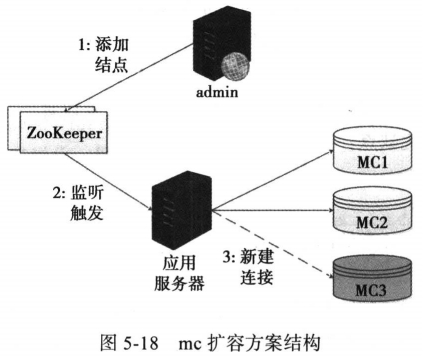
如上图,admin系统为MC节点的管理系统,可以在系统上面对MC集群的实例进行扩容或者缩容。如果需要扩容,则在管理系统中添加MC3,管理系统将MC3节点添加到ZooKeeper节点上。
应用服务器监听ZooKeeper节点的状态,如果有数据变更,应用服务器便会得到通知。
应用服务器会拿到MC3节点的信息,将该节点添加到本地原有的cluser集群里。这里注意采用一致性hash,否则不能满足单调性,对原有hash策略影响较大。
5.5 Memcached周边工具发展
- the InnoDB Memcached Plugin
- Twemcache
- Twemproxy
- MemcachedDB
- MemcacheQ
- Mcrouter
- Tokyo Cabinet

 浙公网安备 33010602011771号
浙公网安备 33010602011771号