5.3 典型问题解析
memcached的内存是有限的,对于大量的或者过期的数据,是如何进行管理的呢?
单实例memcached的业务场景下,随着业务规模的不断增长,一般会出现以下几个问题:
1.容量问题
单一服务节点无法突破单击内存上限。如新浪微博已经超过千亿数据,虽然无须将所有数据都放如缓存中,但在保证一定命中率的情况下(注:微波核心缓存命中率需要达到99%)缓存部分数据,也需要以百GB甚至TB为单位的内存容量。
2.服务高可用(HA)
在单实例场景下,缓存如果因为网络波动、机器故障等原因不可用,会让访问全部穿透到数据库层,这在架构上是致命风险。
3.扩展问题
单一服务节地那无法突破单实例请求峰值上限,比如热点问题,微波的热点事件,淘宝的热点单品秒杀都是属于此类。要确保高于日常N倍的请求到达,扩展问题也是分布式方案的基本问题。
5.3.1 过期机制
memcached有两种过期机制,一种是 Lazy Expiration,另一种是LRU算法
Lazy Expiration:memcached内部不会监视记录是否过期,而是在get时查看记录的时间戳,检查记录是否过期。这种技术被称为lazy expiration。因此,memcached不会再过期监视上耗费CPU时间
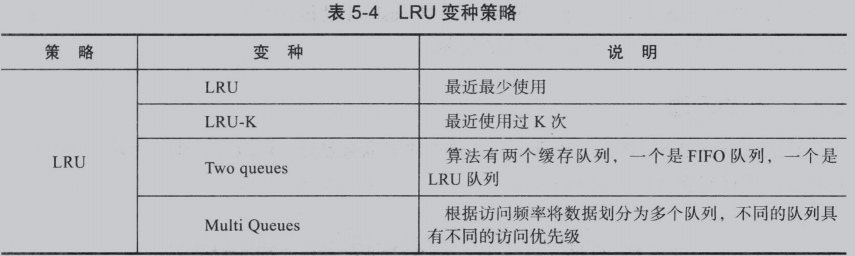
LRU算法:LRU顾名思义就是最近最少使用算法。而且LRU有一系列变种,如表5-4所示。
memcached启动时通过 “-M”参数可以禁止LRU,如下所示:
$ memcached -M -m 1024
注意小写的“-m”是指定内存大小的,默认值64MB
指定“-M”参数启动后,内存耗尽时,memcached会返回错误。
tips 这里的LRU是在Slab范围内,不是全局的。
5.3.2 哈希算法
哈希(Hash)就是:任意长度的输入,通过散列算法,变换成固定长度的输出。为了解决单实例的瓶颈,需要memcached进行分布式部署。常见分布式部署结构如图5-9。
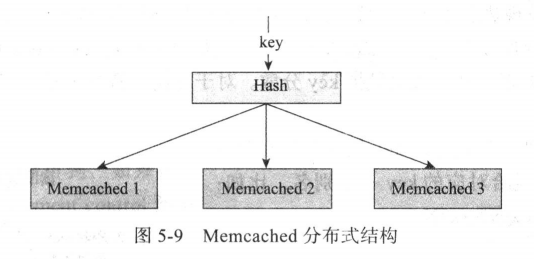
该分布式部署依赖的核心便是Hash算法。
如图5-9中有三个memcached实例,一般的Hash算法为:hash(key) mod 3 ,取得一台固定的memcached实例。该Hash方案接口简单 ,但是缺点非常突出。假如扩容一台memcached实例,那么该Hash算法便修改为:hash(key) mod 4 ,这会导致历史所有数据无法找到,导致大量访问回源。
分布式集群中,对机器的添加、删除或者机器故障自动脱离集群这些操作是分布式集群管理的基本功能,使用一致性hash可以很好地解决动态变化环境下使用memcached扩缩容带来的大量数据失效问题。
5.3.3 热点问题
热点数据就是hot数据,场景不同,热点数据也有差异,可以进一步分为热点数据和巨热数据,热点问题如图5-10所示。
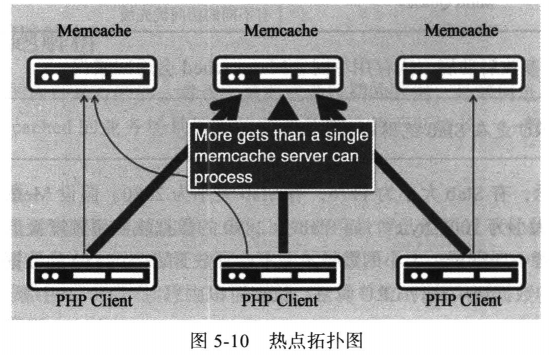
数据热点访问(读热点问题),比如电商Detail详情页面。对某些热点商品的访问度非常高,即使是第9章中介绍的Tair缓存这种Cache本身也是有瓶颈问题,一旦请求量达到单击极限也会存在热点保护问题。提供一个通用的解决思路,就是在Cache的Client端做本地LocalCache,当发现热点数据时直接Cache在Client里,而不要请求CacheServer。
巨热数据处理方式,在Facebook有一招,通过多个key_index(key:xxx#N),来获取热点key的数据,其实质也是把key分散。对于非高一致性要求的高并发读还是蛮有效的。
解决之道:
把巨热数据的key发布到所有服务器,每一个服务器对应的key一个别名,比如:get key:xxx => get key:xxx#N
5.3.4 缓存与数据库的更新问题
缓存和数据库更新的一致性,这是一个常会讨论的问题。假设,如果更新数据库,再删除缓存时出现这样的情况,数据库操作更新成功,缓存更新失败,结果时缓存中存在旧的数据,用户获取到旧的信息,存在不一致性,如图5-11所示。
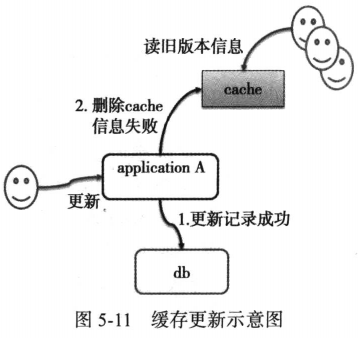
虽然这种方案在某些场景下没有问题,比如在SNS系统中查看好友头像或者基本信息。
5.3.5 别把缓存当存储
在分布式架构下,一切系统都可能fail,无论是缓存、存储(包括数据库)还是应用服务器,而且部分缓存本身就是未提供持久化机制。即使使用了持久化机制的cache,如果作为唯一存储的话也要慎用。
5.3.6 命名空间
防止key冲突,使用前缀区分。
5.3.7 CAS
主要解决原子操作问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号