
in exist 测试
表数情况:
CompanyBackup 803行 UserApplicationBackup 4.6w行 Company表Id非主键,有非聚集索引;UserApplication表CompanyId 有非聚集索引
Company.Id=UserApplication.CompanyId
一、
SQL 语句:
SELECT * FROM dbo.CompanyBackup c
WHERE EXISTS (SELECT * FROM dbo.UserApplicationBackup u WHERE u.companyid=c.id )
SELECT * FROM dbo.CompanyBackup c
WHERE c.id IN (SELECT u.companyid FROM dbo.UserApplicationBackup u )
执行计划:
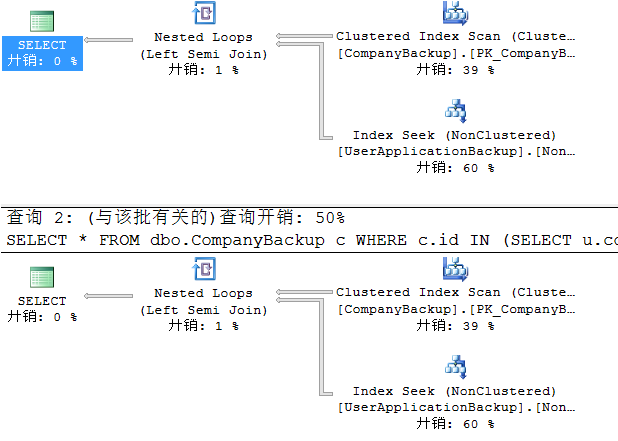
IO 和 Time:


扫描803次UA表的索引,每次从Company表取一行,扫描UserApplication表的CompanyId索引
二、
SQL 语句:
SELECT * FROM dbo.UserApplicationBackup u
WHERE u.companyid IN (SELECT c.id FROM dbo.CompanyBackup c )
SELECT * FROM dbo.UserApplicationBackup u
WHERE EXISTS (SELECT * FROM dbo.CompanyBackup c WHERE c.id=u.companyid )
执行计划:
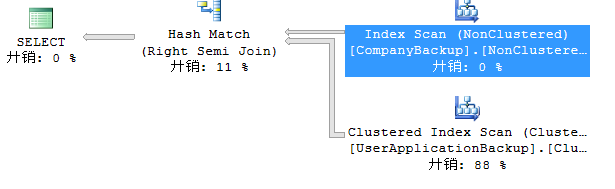
IO 和 Time:


扫描次数是1次,Hash Match 合并结果,相对的CPU时间消耗增加,当然结果集数据相差很大。
总结:
合并不同:1使用nested looops 2使用 hash match
结果集不同: 1 是Company表为结果集 2是UserApplication 表结果集
扫描情况不同: 1 扫描803次非聚集索引索引 2是聚集索引依次扫描
问题:
In Exist 的执行计划都一样 扫描次数,逻辑读取都相同,为什么CPU时间和占用时间有些误差呢?咋回事儿?感觉误差也不小呀?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号