秒杀笔记--极客时间
秒杀解决的两个问题:并发读,并发写
秒杀系统本质:一个满足高并发、高性能和高可用的分布式系统
浏览器到服务端请求需要保证用户请求数据尽量少,请求数尽量少,路径尽量短,依赖尽量少,不要有单点。
秒杀系统整体概括:稳,准,快(高可用,一致性,高性能)
一、3个关键点
高性能
大量的并发读写,需要支持高并发访问非常关键。
解决要点
-
- 设计数据动静分离
- 热点的发现与隔离
- 请求消峰与分层过滤
- 服务端机制优化
一致性
减库存的实现方式,在高并发中保证数据的准确性
高可用
PlanB
二、设计架构原则
- 数据尽量少,简化页面。因为网络传输需要时间,请求和返回都需要服务器做处理,服务器在写网络时的压缩和字符编码消耗CPU。其次,系统依赖的数据尽量少,包括某些业务逻辑需要读取和保存数据,而这些数据需要和数据库交互。调用其他服务的序列化,反序列化也是CPU大杀手,增加延迟。而且数据库本身容易成为瓶颈,数据应越简单,越小越好。
- 请求数尽量少,请求会有消耗如:三次握手连接,页面依赖,连接数限制,有时候需要串行加载,不用域名设计DNS解析可能耗时更久。可通过将多个js文件合并(URL中用逗号隔开,服务器解析次URL,动态合并为一个文件返回;这里文件合并不一定将文件全部合并,例如只合并首屏加载的资源,而其他资源在另外请求可以平衡首屏加载速度和页面加载性能)。
- 路径短(中间节点少),若节点可用性位99.9%,请求经过5个节点,则整体可用性位99.9%的五次方约等于99.5%。缩短路径不仅可以提高可用性,也能减少数据在节点间的学历恶化反序列化,以及网络延迟。解决方案:多个强依赖应用合并部署,把远程调用RPC变为JVM内部方法调用。
- 依赖尽量少,是指完成一次用户请求必须依赖的系统或服务尽量少,依赖是指强依赖。
如:秒杀展示页面强依赖与商品信息,用户信息,还有其他如优惠券,成交列表等这些对秒杀来说是非重要信息,可以去掉。
减少依赖,需要对系统分级,重要的系统尽量减少对次级系统的依赖,防止被次级系统拖垮。 - 不能有单点,分布式系统重要原则之一“消除单点”,没有备份,风险不可控。
如何避免单点:避免服务的状态和机器绑定,即服务无状态话,这样服务可以在机器中随意移动
如何把服务状态和机器解耦呢?如:把机器配置动态化,配置参数通过配置中心动态推送,在服务启动时动态拉取下来。
数据存储在磁盘上,本身就和机器绑定,这时一般通过冗余备份解决单点问题
不同场景下架构案例
- 搭建简单秒杀系统
只需要把商品购买页面增加一个“定时上架”功能,仅在秒杀开始才让用户看到购买按钮,商品卖完了也就结束了。 - 请求量加大(如1w/s到了10w/s量级),简单架构遇到了瓶颈,需要做架构改造来提升系统性能。改造如下:
a)把秒杀系统独立出来打造一个系统,做针对性的优化,例如独立出来的系统减少了店铺装修(?),减少了页面复杂度。
b)独立集群部署,秒杀大流量不会影响正常商品购买集群的机器负载。
c)热点数据单独到一个缓存系统中,提高读性能
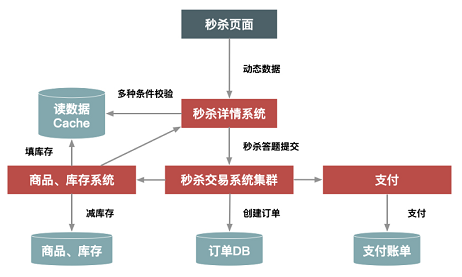
d)秒杀答题,防止秒杀器![]()
-
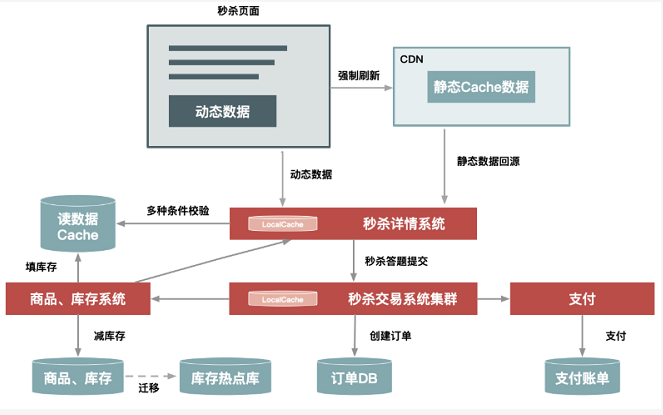
为了支持100w/s的请求量,进一步提升秒杀性能,需要进一步架构升级
a)页面彻底动静分离,使用户秒杀时不需要刷新整个页面,而只需要点击抢宝按钮,借此把页面刷新的数据降到最低
b)服务器对秒杀商品本地缓存,不需要依赖后台服务获取数据,不需要去公共缓存集群查找数据,减少系统调用,避免压垮公共缓存集群
c)增加系统限流保护,防止最坏情况发生
优化后如下图。这里对页面进一步静态化,秒杀过程不需要刷新整个页面,只需要请求少量动态数据。而且,最关键的详情和交易系统增加本地缓存,提前缓存秒杀商品信息,热点数据库也做了独立部署等![]()
从前几次升级发现,后面需要定制的地方越来越多,越来越不通用。例如把秒杀商品缓存在每台机器内存中,这种方式不适合太多商品同时秒杀的情况,因为单机内存有限。因此取得机制性能,就要在其他地方(如通用性,易用性,成本等方面)有所牺牲。
三、如何做好动静分离?有哪些方案可选择?
四、二八原则:有针对性地处理好系统的“热点数据”
1 热点
分为热点操作和热点数据
1.2 热点操作
可以抽象为 “读请求”和“写请求”
1.3 热点数据
可以分为“静态热点数据”和“动态热点数据”
1.3.1 静态热点数据
能提前预热的热点数据(如:1.通过卖家报名打标收集热点商品(实时性差,增加卖家使用成本,不灵活);2.通过大数据分析历史成交记录,用户购物车发现可能的热点数据(也是实时性差,不能再秒级内自动发现热点商品))
1.3.2 动态热点数据
不能被提前预测的,系统在运行过程中临时产生的热点数据(如因为某广告突然被大量购买)
2.动态热点数据的发现方案?
-
构建一个异步的系统,它可以收集交易链路上各个环节中的中间件产品的热点 Key,如 Nginx、缓存、RPC 服务框架等这些中间件(一些中间件产品本身已经有热点统计模块)。
- 建立一个热点上报和可以按照需求订阅的热点服务的下发规范,主要目的是通过交易链路上各个系统(包括详情、购物车、交易、优惠、库存、物流等)访问的时间差,把上游已经发现的热点透传给下游系统,提前做好保护。比如,对于大促高峰期,详情系统是最早知道的,在统一接入层上 Nginx 模块统计的热点 URL。
- 将上游系统收集的热点数据发送到热点服务台,然后下游系统(如交易系统)就会知道哪些商品会被频繁调用,然后做热点保护。
-
3.处理热点数据
- 优化
先来说说优化。优化热点数据最有效的办法就是缓存热点数据,如果热点数据做了动静分离,那么可以长期缓存静态数据。但是,缓存热点数据更多的是“临时”缓存,即不管是静态数据还是动态数据,都用一个队列短暂地缓存数秒钟,由于队列长度有限,可以采用 LRU 淘汰算法替换。 - 限制
限制更多的是一种保护机制,限制的办法也有很多,例如对被访问商品的 ID 做一致性 Hash,然后根据 Hash 做分桶,每个分桶设置一个处理队列,这样可以把热点商品限制在一个请求队列里,防止因某些热点商品占用太多的服务器资源,而使其他请求始终得不到服务器的处理资源。 - 隔离
秒杀系统设计的第一个原则就是将这种热点数据隔离出来,不要让 1% 的请求影响到另外的 99%,隔离出来后也更方便对这 1% 的请求做针对性的优化。
- 优化
3.3.1 “秒杀”业务,可以在一下几个层次隔离
- 把秒杀做成一种营销活动,卖家要参加秒杀营销活动需要报名,从技术上来说,卖家报名后对我们来说就有了已知热点,因此可以提前做好预热。
- 系统隔离更多的是运行时的隔离,可以通过分组部署的方式和另外 99% 分开。秒杀可以申请单独的域名,目的也是让请求落到不同的集群中。
- 秒杀所调用的数据大部分都是热点数据,比如会启用单独的 Cache 集群或者 MySQL 数据库来放热点数据,目的也是不想 0.01% 的数据有机会影响 99.99% 数据。
当然了,实现隔离有很多种办法。比如,你可以按照用户来区分,给不同的用户分配不同的 Cookie,在接入层,路由到不同的服务接口中;再比如,你还可以在接入层针对 URL 中的不同 Path 来设置限流策略。服务层调用不同的服务接口,以及数据层通过给数据打标来区分等等这些措施,其目的都是把已经识别出来的热点请求和普通的请求区分开。
五、流量削峰
针对秒杀这一场景,削峰从本质上来说就是更多地延缓用户请求的发出,以便减少和过滤掉一些无效请求
为什么削峰?带来的好处和坏处?
服务器处理能力是恒定有限的,出现峰值可能处理不过来,为了保证高峰处理能力需要根据峰值评估资源,导致闲的时候又有资源浪费。
削峰可以使服务器处理请求更加平稳,也可以节约服务器资源成本
5.1 削峰策略
-
- 排队
- 答题
- 分层过滤
5.1.1排队
把同步调用转换为异步间接推送,将流量洪峰平滑得消费推送出去。
排队方式:
- 消息队列
-
利用线程池加锁等待也是一种常用的排队方式
-
先进先出、先进后出等常用的内存排队算法的实现方式
-
把请求序列化到文件中,然后再顺序地读文件(例如基于 MySQL binlog 的同步机制??)来恢复请求等方式
这些方式都有一个共同特征,就是把“一步的操作”变成“两步的操作”,其中增加的一步操作用来起到缓冲的作用。
5.1.2 答题
答题增加了购买复杂度,但是可以减少作弊软件,也可以延缓用户请求,将瞬间流量延长到几秒的时间片内,大大减轻了压力。靠后的消息到不了下单就因为没有库存而终止了。
5.1.3 分层过滤
尽量把数据量和请求量一层一层地过滤和减少了。
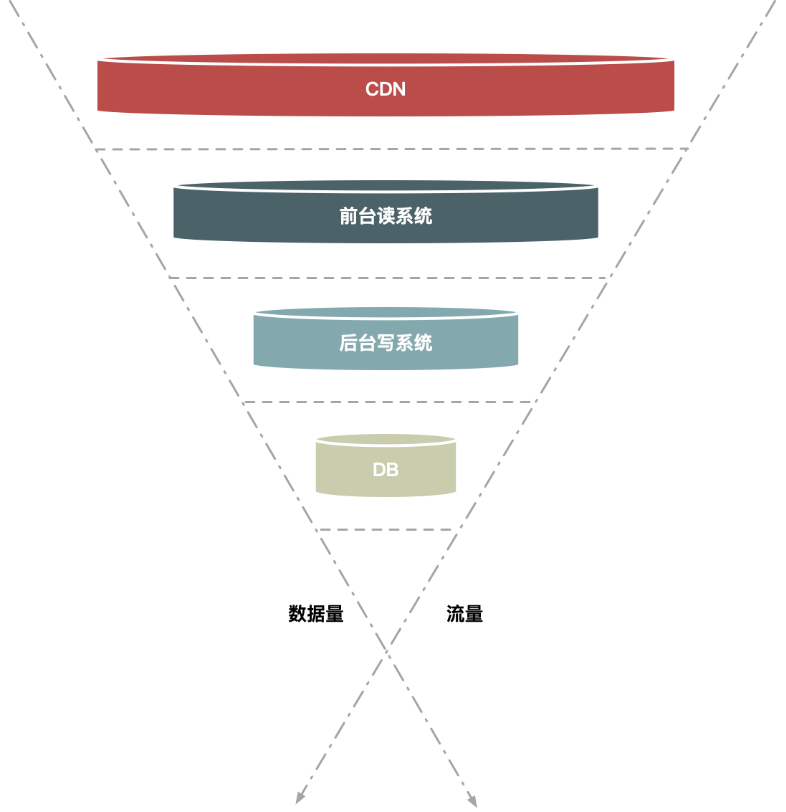
假如请求分别经过 CDN、前台读系统(如商品详情系统)、后台系统(如交易系统)和数据库这几层,那么:
- 大部分数据和流量在用户浏览器或者 CDN 上获取,这一层可以拦截大部分数据的读取
- 经过第二层(即前台系统)时数据(包括强一致性的数据)尽量得走 Cache,过滤一些无效的请求
- 再到第三层后台系统,主要做数据的二次检验,对系统做好保护和限流,这样数据量和请求就进一步减少
- 最后在数据层完成数据的强一致性校验
分层过滤非常适合交易性的写请求,比如减库存或者拼车这种场景,在读的时候需要知道还有没有库存或者是否还有剩余空座位。但是由于库存和座位又是不停变化的,所以读的数据是否一定要非常准确呢?其实不一定,你可以放一些请求过去(db减库存后,缓存失效前者短时间可能出现不一致),然后在真正减的时候再做强一致性保证,这样既过滤一些请求又解决了强一致性读的瓶颈。
5.1.4 业务手段
秒杀活动开启是开启其他优惠活动将流量分散。
六、影响性能的因素有哪些?如何提高系统性能?
6.1 影响性能的因素
不同设备的性能定义不同。例如,CPU主要看主频,磁盘主要看IOPS(Input/Output Operations Per Second,每秒钟读写次数)
系统服务端性能一般用 QPS 来衡量,还有响应时间RT(Response Time 分为CPU处理时间和线程等待时间)和QPS也息息相关
总QPS=(1000ms / RT) * 线程数
6.2 响应时间对QPS的影响
真正对性能有影响的是CPU的执行时间,执行真正消耗了服务器资源,经测试减少一半执行时间,可以增加一倍QPS,所以应该致力于减少CPU执行时间
6.3 线程数对QPS的影响
每个线程都消耗资源,而且线程切换成本也很高,所以设置合理线程数很关键。
公式:线程数 = [(线程等待时间 + 线程 CPU 时间) / 线程 CPU 时间] × CPU 数量
最好还是通过性能测试发现最佳线程数
6.4 如何发现瓶颈
就服务器而言,会出现瓶颈的地方有很多,如 CPU ,内存 , 磁盘 , 网络 不同的系统关注点也不同。
秒杀系统的瓶颈更多发生在CPU上,很多CPU诊断工具可以发现CPU的消耗
-
JProfiler 和 Yourkit 这两个工具,列出每个函数CPU执行时间,发现消耗时间最多的函数,针对性得优化
- jstack定时打印调用栈,如果某些函数调用频繁或耗时过多,就会多次出现在系统调用栈里,这样相当于采样的方式也能够发现耗时较多的函数。
-
简单判断CPU是不是瓶颈,但QPS达到极限时,服务器使用率是否超过95%,若果没有超过,则还有提升空间,要么是有锁限制,要么是过多本地I/O等待发生
6.5 如何优化系统
- 减少编码,每个字符的编码都需要查表,这种操作非常消耗资源。可以把静态资源提前编码成字节缓存,使用时直接输出。
- 减少序列化,往往和编码同时发生。合并部署减少RPC调用,不走本机Socket,避免序列化发生。
- java极致优化
- 并发读优化,采用LocalCache,静态数据预热,分层校验,读场景允许一定的脏数据,保证最终一致性
还可以做什么
- 减少数据,服务器处理数据不可避免存在字符到字节的转换,HTTP请求Gzip压缩
- 数据分级(动静分离),首屏优先,重要数据优先,次要信息异步加载,提升用户体验
- 减少中间环节,增加预处理(提前做字符到字节的转换)
7 减库存
7.1 减库存几种方式
- 下单减库存(可能存在下单不付款)
- 付款减库存(可能下单数多于实际秒杀数,不能付款,用户体验差)
- 预扣减库存(也可能被恶意下单,针对实际情况对多次下单不付款行为做限制,限制同一用户下单数等)
7.2 实际大型秒杀中减库存方式
因为秒杀商品一般“抢到就是赚到”所以下单后不付款情况很少发生,再加上秒杀商品库存有严格限制,而且更加简单,所以秒杀商品采用“下单减库存”更加合理。
在一致性上,保证数据库数据不能为负数:1.事务判断回滚 2.限制字段不能为负数,数据库自动报错 3.CASE WHEN 判断语句 UPDATE item SET inventory = CASE WHEN inventory >= 1 THEN inventory-1 ELSE inventory END
7.3 关键优化点
7.3.1 并发读优化
秒杀中不一定需要保证精确的读一致性,可以把数据放在缓存中,大大提升性能,在写时保证强一致性。
分离热点数据,采用LocalCache缓存商品数据和对数据分层过滤方式提升读性能
7.3.2 并发写优化
对同一数据写,会产生行锁的竞争,TPS会下降,RT上升,影响吞吐量
秒杀商品比普通商品少,交易时间也比较短,如果减库存的逻辑简单,不需要事务,可以将减库存在缓存中实现
防止热点数据并发行锁影响整个数据库性能,需要把热点数据分离到单独的热点库中。但是会带来维护麻烦,如热点数据迁移,单独数据库。
分离热点数据到单独的库中没有解决并发写,并发锁问题,我们如何解决呢?
解决并发行锁问题
- 应用层排队
按照商品维度设置队列顺序执行,这样能减少同一台机器对数据库同一行记录进行操作的并发度,同时也能控制单个商品占用数据库连接的数量,防止热点商品占用太多的数据库连接。 - 数据库层排队
应用层只能做到单机的排队,但是应用机器数本身很多,这种排队方式控制并发的能力仍然有限,所以如果能在数据库层做全局排队是最理想的。数据库层上对单行记录做到并发排队。 - 多条SQL合并,减少数据库操作
- 应用层排队
八、兜底方案
8.1 高可用建设的入手点
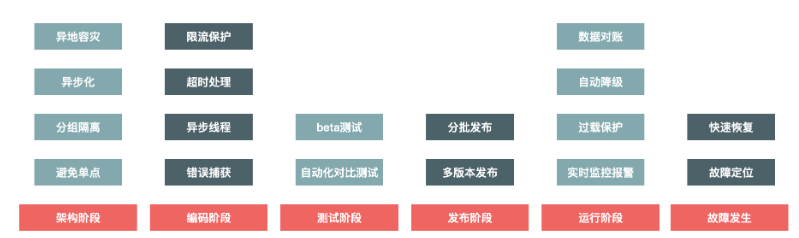
8.2 运行阶段的方案
- 降级
- 限流
- 拒绝服务
8.2.1 降级
当系统容量到达一定程度时,限制或者关闭非关键功能,把有限资源留给核心业务。降级提升了性能,但影响了用户体验。
8.2.2 限流
限流是更加极端的一种方式,当系统达到瓶颈时,我们需要限制一部分流量来保护系统,做到可以人工执行开关,自动化保护的措施。
总体来说限流可以分为客户端限流和服务端限流。
实现方式支持URL以及方法级别的限流,也要支持基于QPS和线程的限流。
在限流实现手段上讲,基于QPS和线程数的限流应用最多,最大QPS很容易通过压测提前获取,例如系统最高支持1wQPS时,可以设置8000来进行限流保护。线程数限流在客户端比较有效,如在远程调用时设置连接池的线程数,超出这个并发线程请求,就将线程进行排队或者直接超时丢弃
注意:限流必然会导致一部分请求失败,因此系统处理这种异常时一定要设置超时时间,防止被限流的请求不能快速失败(fast fail)而拖垮系统。
8.2.3 拒绝服务
最粗暴,最有效不得已执行的系统保护方案
过载保护虽然在过载时无法提供服务,但是防止了把服务器压垮而长时间彻底无法提供服务,系统仍可以运行,而且当负载下降时又容易恢复。
当系统负载达到一定阈值时,例如CPU使用率达到90%或者系统load达到2*CPU核数时,系统直接拒绝所有请求。
如:最前端Nginx上设置过载保护,机器负载达到某值时直接拒绝HTTP请求返回503错误码,在Java层同样可以设计过载保护。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号