

java网络爬虫基础学习(三)
尝试直接请求URL获取资源
豆瓣电影
https://movie.douban.com/explore#!type=movie&tag=%E7%83%AD%E9%97%A8&sort=time&page_limit=20&page_start=0
浏览器打开该地址:
发现是这样的

在这里我们需要用java抓取电影的信息,首先要找到资源链接,浏览器右键-》检查打开谷歌调试工具
我们可以看到下图
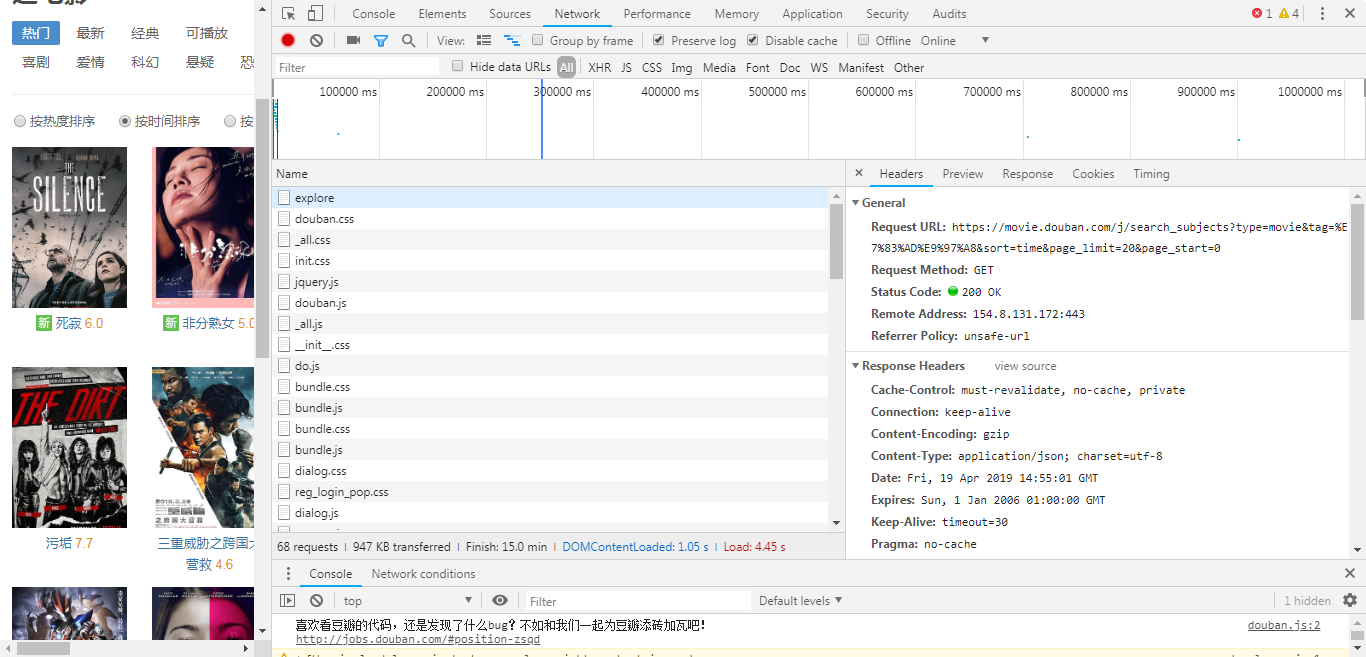
有很多的资源请求,在这里我是一个个搜索,看那个是电影信息的Headers
发现如下,找到一个search资源请求(即真实向后台发送的请求),这里tag=%E7%83%AD%E9%97%A是进行了编码。
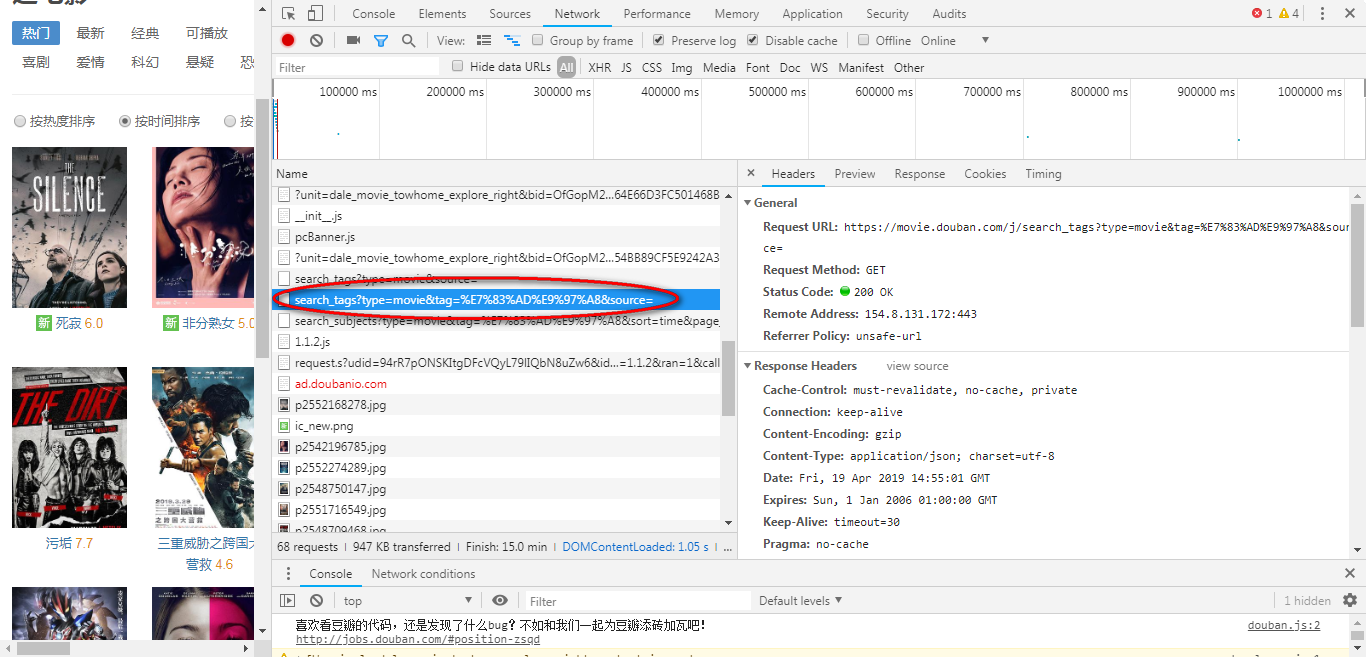
在这里我把该Header中的请求URL在网址上试了一下,显示如下json(还可以是html、xml)数据发现确实是电影信息资源(在这里我用了谷歌的Json Viewer插件显示)

也可以直接看Response

接下来我们使用jsoup工具,请看我的下一篇:java网络爬虫基础学习(四)

