
Hadoop简介与分布式安装
Hadoop的基本概念和分布式安装:
Hadoop
简介
Hadoop 是Apache Lucene创始人道格·卡丁(Doug Cutting)创建的,Lucene是一个应用广泛的文本搜索库,Hadoop起源于开源网络搜索引擎Apache Nutch,后者是Lucene项目的一部分.
Apache Hadoop项目的目标是可靠的、可拓展的分布式计算开发开源软件。
Apache Hadoop平台本质是一个计算存储框架,允许使用简单的编程模型跨计算机集群地处理大型数据集,将计算存储操作从单个服务器拓展到数千台服务器(小型机)每台服务器提供本地计算和存储。平台本身不是依靠提升硬件来提高高可用的,而是在应用层检测和处理故障。从而在一组计算机上提供高性能的服务,每个计算机都可能出现故障,Hadoop中所有的模块。都基于一个假设,即硬件故障是常见事件,应由框架自动处理。
Hadoop是一个用Java编写的Apache开放源代码框架,它允许使用简单的编程模型在计算机集中环境分布式处理大型数据集。Hadoop框架式应用程序在跨计算机集群提供分布式存储在计算集群提供的存储和计算环境中工作,Hadoop旨在从单个服务器扩展到数千台机器,每台机器提供了本地计算和存储。
其核心构成分别为 HDFS(分布式文件系统)、MapReduce(分布式计算系统)、Yarn(资源管理系统)
HDFS
HDFS是Google发布于2003年10月的《Google FS》的开源实现。
Hadoop分布式文件系统(HDFS)能够提供对数据访问的高吞吐量,适用于大数据场景的数据存储,因为HDFS提高了高可靠性(主要通过多副本实现)、高拓展性(通过添加机器来达到线性拓展)、和高吞吐率的数据存储服务,Hadoop是被设计成能够运行在通用的硬件上的分布式文件系统,因此可以使用廉价的通用机器。大大减少了公司的成本。
HDFS的基本原理是将数据文件以指定大小拆分成数据块,并将数据块以副本的方式存储到多台机器上,即使其中某一个节点出现故障,那么该节点上的数据块副本丢失还有其对应的其他节点的数据副本,但是前提是你的副本系数大于1,HDFS将数据文件拆分、容错、负载均衡等透明化(用户感知不到整个过程,只知道上传了一个文件到HDFS上其中数据的切分、存储在那些机器上是感知不到的)我们可以把HDFS看成是一个容量巨大的、具有高容错的磁盘,在使用的时候完全可以当作本地的磁盘进行使用,所以说HDFS是适用于海量数据的可靠性存储。
Mapreduce
Mapreduce是一个分布式、并发处理的编程模型,用于进行大数据量的计算,MapReduce的名字源于模型中的两个操作:Map(映射)和Reduce(归纳)。Mapreduce是一种简化并进行应用程序开发的编程模型,能够让没有多少并行应用经验的开发人员可以进行快速地学会并行应用开发,而且不需要去关注并行计算中地一些底层问题,按照Mapreduce API的编程模型实现业务逻辑的开发即可。
一个Mapreduce作业通常会把输入的结果集切分成若干个独立的数据块,由map任务以并行处理的方式,对map的输出先进行排序,然后把结果输入给reduce任务由reduce任务来完成最终的统一处理。通常Mapreduce作业的输入和输出都是用HDFS进行存储的,也就是说Mapreduce框架处理数据的输入源和输出目的地大部分场景都是储存在HDFS上。
在部署Hadoop集群时,通常是将计算节点和存储节点部署在同一个节点上,这样做的原因是允许计算框架在任务调度时,可以先将作业优先调度到那些已经存有数据节点上进行数据计算,这样可以使整个集群的网络带宽十分高效地利用,这也是大数据中十分著名地话“移动计算而不是移动数据”。
Yarn
Yarn的全成是 Yarn Another Resource Negotiator,是一个同源资源管理系统,可以为运行在YARN之上的分布式程序提供统一的资源管理和调度。在Yarn我们可以运行不同类型的作业,如:Mapreduce、Spark、TEZ等不同的计算框架
Yarn是随着Hadoop发展而催生的新框架,Yarn的基本思想是将Hadoop1.x中的Mapreduce架构中的JobTracker的资源管理和作业调度监控功能进行分离,解决了Hadoop1.x只能运行 Mapreduce框架的限制。
安装
机器
准备3台linux机器
本教程ip配置如下
| hostname | ip | 角色 |
|---|---|---|
| datanode1 | 192.168.1.101 | NameNode Datanode |
| datanode2 | 192.168.1.102 | SecondaryNameNode Datanode |
| datanode3 | 192.168.1.103 | ResourceManager DataNode |
修改主机名
vim /etc/sysconfig/network ETWORKING=yes HOSTNAME=datanode1 #其他机器依次执行
SSH
设置master节点和两个slave节点之间的双向ssh免密通信,下面以master节点ssh免密登陆slave节点设置为例,进行ssh设置介绍(以下操作均在master机器上操作):
首先生成master的rsa密钥:ssh-keygen -t rsa 设置全部采用默认值进行回车 将生成的rsa追加写入授权文件:cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys 给授权文件权限:chmod 600 ~/.ssh/authorized_keys 进行本机ssh测试:ssh datasnode1 正常免密登陆后所有的ssh第一次都需要密码,此后都不需要密码 将master上的authorized_keys传到datanode1 sudo scp ~/.ssh/id_rsa.pub hadoop@datanode1:~/ 登陆到slave1操作:ssh slave1输入密码登陆 cat ~/id_rsa.pub >> ~/.ssh/authorized_keys 修改authorized_keys权限:chmod 600 ~/.ssh/authorized_keys 退出slave1:exit 进行免密ssh登陆测试:ssh slave1
JAVA
1.解压
tar -zxvf jdk-8u162-linux-x64.tar.gz -C /opt/module/
2.配置
# 修改 /etc/profile #JAVA_HOME export JAVA_HOME=/opt/module/jdk1.8.0_162 export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
3.更新
source /etc/profile
NTP 时间同步
修改配置
vim /etc/ntp.conf
主机配置
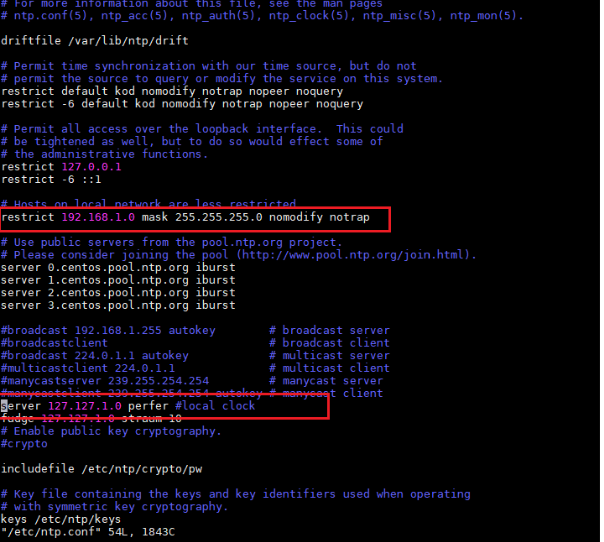
从机配置

从节点同步时间
service ntpd restart chkconfig ntpd on # 开机启动 ntpdate -u datanode1 crontab -e * */1 * * * /usr/sbin/ntpdate datanode1 #每一小时同步一次
同步脚本
#!/bin/bash
#1 获取输入参数个数,如果没有参数,直接退出
pcount=$#
if((pcount==0)); then
echo no args;
exit;
fi
#2 获取文件名称
p1=$1
fname=`basename $p1`
echo fname=$fname
#3 获取上级目录到绝对路径
pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir
#4 获取当前用户名称
user=`whoami`
#5 循环
for((host=1; host<4; host++)); do
#echo $pdir/$fname $user@datanode$host:$pdir
echo --------------- datanode$host ----------------
rsync -rvl $pdir/$fname $user@datanode$host:$pdir
done
解压文件
tar -zxvf hadoop-2.7.2.tar.gz -C /opt/module/ mv hadoop-2.7.2 hadoop
修改配置
core-site
<configuration>
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://datanode1:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop/data</value>
</property>
<property>
<!-- 指定垃圾回收时间每隔60分钟 -->
<name>fs.trash.interval </name>
<value>60</value>
</property>
</configuration>
hdfs-site
<configuration>
<property>
<!--指定副本数-->
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<!-- 指定 secondaryNamenode -->
<name>dfs.namenode.secondary.http-address</name>
<value>datanode2:50090</value>
</property>
</configuration>
yarn-site
<configuration>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>datanode3</value>
</property>
<!--开启历史查看任务-->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
</configuration>
hadoop-env
export JAVA_HOME=/opt/module/jdk1.8.0_162
yarn-env
#some Java parameters export JAVA_HOME=/opt/module/jdk1.8.0_162
mapred-env
export JAVA_HOME=/opt/module/jdk1.8.0_162
mapred-site
<configuration>
<!-- 指定mr运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
分发
[hadoop@datanode1 module]$ xsync hadoop/ [hadoop@datanode1 module]$ xsync jdk1.8.0_162/
格式化hdfs
hdfs namenode -format
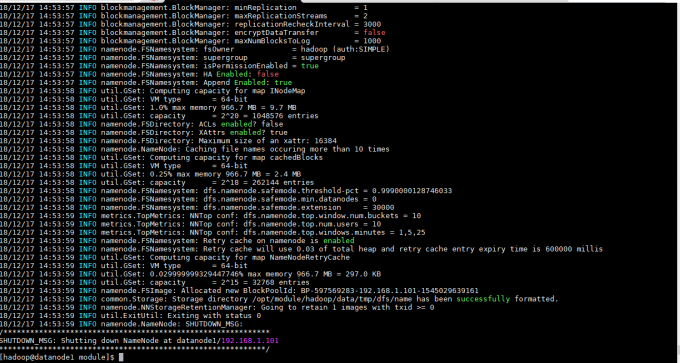
启动
[hadoop@datanode1 hadoop]$ start-dfs.sh [hadoop@datanode1 hadoop]$ jps 51235 NameNode 51356 DataNode 52111 Jps 51919 NodeManager [hadoop@datanode3 hadoop]$ start-yarn.sh [hadoop@datanode3 hadoop]$ jps 22260 ResourceManager 22090 DataNode 22384 NodeManager 23013 Jps
界面
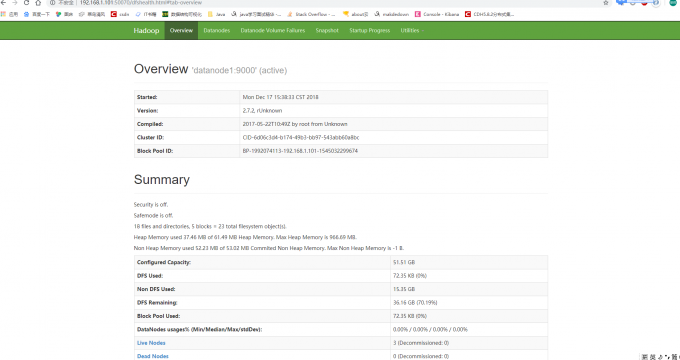


 浙公网安备 33010602011771号
浙公网安备 33010602011771号