
Hadoop的RPC工作原理
RPC远程过程调用:
Hadoop的远程过程调用(Remote Procedure Call,RPC)是Hadoop中核心通信机制,RPC主要通过所有Hadoop的组件元数据交换,如MapReduce、Hadoop分布式文件系统(HDFS)和Hadoop的数据库(Hbase)。RPC是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议,RPC假定某些协议如(TCP和UDP)存在,为通信程序之间携带信息数据。
TCP
TCP(Transmission Control Protol,传输文本协议)是一种面向连接、可靠的、基于字节流的传输层的通信信息,由IETF的RFC793定义。简化的计算网络OSI模型中,它完成第四层(传输层)所指定的功能,用户数据报协议(UDP)是同一层内另一个重要的传输协议,在因特网协议簇(Internel Protocol Suite)中,TCP基于IP层之上、应用层之下的中间层,不同主机的应用层之间经常需要可靠的、像管道一样的连接,但是IP层不提供这样的流机制,而是提供不可靠的包交换的。
当应用向TCP层发送用于网间传输的、用字节流表示的数据流时,TCP则把数据流分割成适当长度的报文段,最大传输段大小(MSS)通常受该计算机连接网络的数据链路层的最大传送单元(MTU) 限制。之后TCP把数据包传到IP层、由它通过网络将包传送给接收端实体的TCP层。TCP为了保证报文的可靠性,给每个包一个序列号,同时该序列号也保证了传送到接收端实体的包的按序接收。然后接收端实体对已经成功收到的字节发回一个相应的确认(ACK);如果发送端实体在合理的往返时延(RTT)内未收到去确认,则对应的数据包就被假设为以丢失,将会被重传。
UDP
UDP(User Datagram Protocol,用户数据报协议)是OSI(Open System Interconnection,开放式系统互联)参考模型中一种无连接的传输层协议,提供面向事务的简单不可靠信息传送服务,也就是说UDP不提供数据包分组、组装,并且不能对数据包进行排序,当报文发送之后,是无法得知其是否安全完整到达的。IETF RFC 768是UDP的正式规范。
与熟悉的TCP传输控制协议一样,UDP直接位于IP(网络协议)的上层,根据OSI(开放系统互连)参考模型,UDP和TCP都属于传输层协议。UDP的主要作用是将网络数据流量压缩成数据的形式。一个典型的数据包就是一个二进制数据的传输单位,每个数据包的前8个字节用来包含报头信息,剩余字节则用来包含具体的传输数据。
HTTP
HTTP(Hyper Text Transfer Protoco;超文本传输协议)是互联网上应用最为广泛的一种网络协议,所有的WWW文件都必须最受这个标准,设计HTTP最初的目的是提供一种发布和接收HTML页面的方法。
HTTP是客户端和服务器请求和应答的的标准。客户端是终端用户,服务器是终端用户,服务器是网站,通过使用Web浏览器、网络爬虫或者其他工具,客户端发起一个服务器到指定端口(默认80)的HTTP请求。这个客户端被称为用户代理(User Agent)。应答服务器上存储着(一些资源),如HTML的文件和图像。这个应答服务器被称为源服务器(Origin Server),在用户代理和源服务器中化建可能存在多个中间件,如代理、网关或者隧道(Tunnels)。尽管TCP/IP是互联网上最流行的应用,HTTP并没有规定必须用它和(基于)它支持的层。但事实上,HTTP可以在任何互联网协议上或者其他网络实现。HTTP并没有规定必须使用它和(基于)它支持的层。事实上,HTTP可以在任何互联网协议上或者其他网络上实现。HTTP只假定(其下层协议提供)可靠的传输,任何能提供这种保证的协议都可以被其使用。HTTP使用TCP而不是UDP的原因在于(打开)一个网页必须需要传送很多数据,而TCP提供传输控制,按顺序组织数据和纠正错误。
RPC简介
RPC的主要功能目标是构建分布式计算(应用场景)更容易,在提供强大的远程调用服务能力时。不损失本地调用的语义整洁性。
RPC由以下特点:
-
透明性:远程调用其他机器上的程序,对用户来说就像调用本地的方法一样。
-
高性能:RPC Server能够并发处理多个来自Client的请求。
-
可控性:JDK中已经提供了一个RPC框架———-RMI,但是该RPC框架过于重量级并且可控制指出比较少,所以Haoop实现了自定义的RPC框架。
实现RPC程序包括5个部分,即User、User-stub、RPCRuntime、Server-stub、Server
这里的User就是Client端,当User想发起一个远程调用的时候,它实际时通过本地调用User-stub。User-stub负责将调用的接口、方法和参数通过约定的协议规范进行编码并通过本地的RPCRuntime实例传输到远端的实例。远端RPCRuntime实例收到请求后交给Server-stub进行解码后,发起本地端调用,调用结果再返回给User。
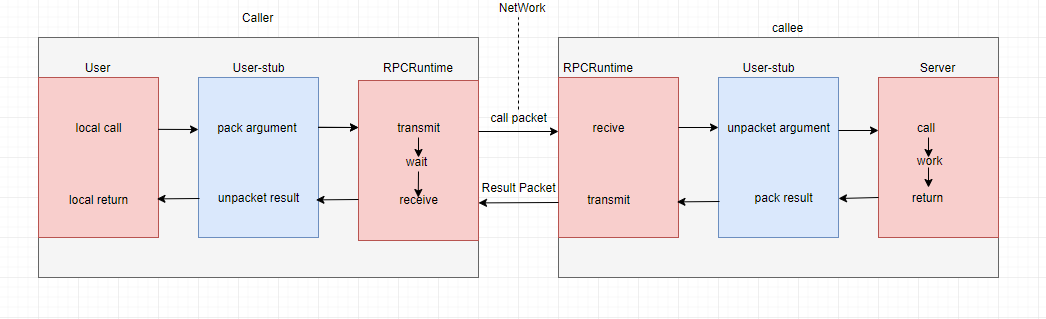
HadoopRPC简介
Hadoop中RPC的运行机制
同其他RPC框架一样,HadoopRPC分为4个部分
- 序列化从层:Client与Server端通信传递的信息采用了Hadoop提供的序列化或自定义的Writable类型。
- 函数调用层:HadoopRPC通过动态代理以及Java发射实现函数调用。
- 网络传输层:Hadoop RPC采用了基于TPC/IP的Socket机制。
- 服务端框架层:RPC Server利用Java NIO及采用了事件驱动的I/O模型,提高自己的并发处理能力。
Hadoop RPC 再整个Hadoop应用中十分 的广泛、Client、DataNode、NameNode之间的通信全靠它。例如人们平时操作HDFS的时候使用的时FileSystem类,它内部就有一个DFSClient对象,这个对象负责与 NameNode打交道。再运行时DFSClient在本地创建一个NameNode的代理。然后就操作这个代理,这个代理就会通过网络,远程调用NameNode方法,当然它也能返回值。
Hadoop RPC 默认设计时基于Java套接字通信,基于高性能网络的通信并不能达到最大的性能,也会是一个性能瓶颈,当一个调用要被发送到服务器时,RPC客户端首先分配DataOutputBuffer,它包含了一个常见的Java版本具有32字节的默认内部缓存器 。该缓冲区可以保存所有序列化的数据,然而一个很大的序列化数据不能保存在较小的内部缓存中。
设计艺术
动态代理
动态代理可以提供另一个对象的访问,同时隐藏实际情况的具体事务,因为代理对象对客户隐藏了实际的多项,目前Java开发包提供对动态代理的支持,但是现在只支持对接口的实现。
反射 ———— 动态加载类
反射机制时在运行状态中,对与任意一个类,都能够知道这个类的所有属性和方法:对于任意一个对象,都能够调用它的任意一个方法和属性。
使用反射类来动态加载类的步骤:定义一个接口,让所有功能类都实现该接口,通过类名来加载类, 得到该类的类型,命令为
Class mClass = Class.forName(“ClassName”):
使用newInstance()方法获取该类的一个对象,命令为
mClass.newInstance();
将得到的对象转换成接口类型,命令为
InterfaceName = objectName(InterfaceName)mClass.newInstance();
通过该类的对象来调用其中的方法。
序列化
序列化是把对象转换成字节序列的过程,反过来说就是反序列化。它有两方面的应用:一方面是存储对象,可以是永久存储在硬盘的一个文件上,也就是存储在redis支持序列化存储的一个容器中;另外一方面是远程传输对象。
非阻塞异步IO
非阻塞异步IO是指用户调用读写方法是不堵塞的,立即返回,而且用户不需要关注读写,需要提供回调操作,内核线程在完成读写后回调用户提供的callback。
使用RPC的步骤
-
定义RPC协议
RPC协议是客户端与服务端之间的通信接口,它定义了服务器端对外提供的服务接口。
-
实现RPC协议
Hadoop RPC协议通常是一个Java接口,需要用于实现该接口。
-
构造和启动RPC Server
直接使用静态类Builder构造一个RPC Server,并调用函数start()启动该 Server()。
-
构造RPC Client 并发送请求
使用静态方法getProxy构造客户端代理对象,直接通过代理对象调用远程端的方法。
应用实例
定义一个RPC协议
下面定义一个IProxyProtocol通信接口,声明一个Add()方法。
package rpc;
import org.apache.hadoop.ipc.VersionedProtocol;
public interface IRPCInterface extends VersionedProtocol {
long versionID = 1; //版本号,默认情况下不同版本号之间的server和client不能通信。
int add(int a, int b);
}
注意:
- Hadoop中所有自定义RPC接口都需要继承VersionedProtocol接口,它描述了协议的版本信息。
- 默认情况下,不同版本号的RPC Client 和Server之间不能相互通信,因为客户端和服务器端通过版本号标识。
实现RPC协议
Hadoop RPC 协议通常是一个Java接口,用户需要实现该接口。对IProxyProtocol接口进行简单的实现:
package rpc;
import org.apache.hadoop.ipc.ProtocolSignature;
import java.io.IOException;
class IRPCInterfaceImpl implements IRPCInterface {
public int add(int a, int b) {
return a + b;
}
public long getProtocolVersion(String s, long l) throws IOException {
return IRPCInterface.versionID;
}
public ProtocolSignature getProtocolSignature(String s, long l, int i) throws IOException {
return new ProtocolSignature(IRPCInterface.versionID, null);
}
}
这里实现Add方法很简单就是一个加法操作。
构建RPC Server 并启动服务
通过RPC静态方法getServer来获得Server对象
package rpc;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.ipc.RPC;
import org.apache.hadoop.ipc.RPC.Server;
import java.io.IOException;
public class RpcServer {
public static void main(String[] args) throws IOException {
Server server = new RPC.Builder(new Configuration()).
setBindAddress("127.0.0.1").setPort(8080).
setInstance(new IRPCInterfaceImpl()).
setProtocol(IRPCInterface.class).build();
server.start();
}
}
启动:
构造RPC Client 并发送请求
这里使用静态方法getPRoxy或者waitForProxy构造客户端代理对象,直接通过代理对象调用远程端的方法,具体代码如下
package rpc;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.ipc.RPC;
import java.io.IOException;
import java.net.InetSocketAddress;
public class RpcClient {
public static void main(String[] args) throws IOException {
IRPCInterface proxy = RPC.getProxy(IRPCInterface.class, 1,
new InetSocketAddress("127.0.0.1", 8080), new Configuration());
int result = proxy.add(2018, 1);
System.out.println("result = " + result);
}
}
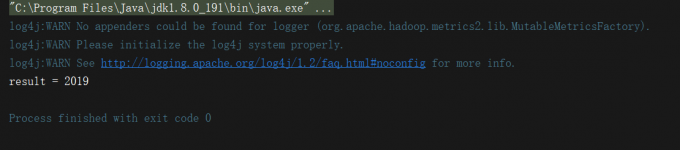
经过上面的四步,我们建立起了一个非常高效的客户机———-服务端网络模型
RPC的改进
目前的Hadoop RPC设计也存在性能瓶颈,人们通过InfiniBand提出了一个超过Hadoop,RPC的、高性能设计的RPCoIB,然后也提出了一个JVM——旁路缓冲管理方案,并在观察消息的大小,以免多重记忆分配、数据序列化和反序列化副本。这种新的设计可以在Hadoop中很容易地与HDFS、Hbase及MapReduce框架进行很好地继承。此外,RPCoIB还对外应用程序提高了很好的灵活性。
基本思想
RPCoIB使用与现在有的用于基于套接字的 Hadoop RPC 由相同的接口。它的基本思想是:
目前的Hadoop RPC 是基于Java 的InputStream 、OutputStream 及SocketChannel,InputStream和OutputStream主要用于客户端,SocketChannel由服务器使用,他们之间基本的读写操作都很相似.为了更好的权衡性能和向后兼容,要设计一条基于RDMA的Java IO 的接口兼容类这些类包括RDMAInputStream|、RDMAOutputStream及RDMAChanael。
JVM ——路缓冲管路
当RDMAOutStream或RDMAInputStream构建地时候,它们将获得一个从本地缓冲得到的本地缓冲区。当RPCoIB库加载时,这些缓冲区为RDMA操作进行预分配和预先登记。得到的缓存开销是非常小的,并且分配将所有的调用进行摊销。这些本地缓冲区将被包装在Java的DirectByteBuffer,它可以由Java层和本地IO层进行访问。在Java层的所有串行化数据可以直接存储在本地缓冲区,以避免中间缓冲区JVM中的堆空间,当缓冲区被填满时,意味着序列化的空间太大而被保存在当前缓冲区,当被请求调用时,所存储的数据将通过实时的JNI RDMA库被送出去。该库通过第一次直接缓冲区操作得到本地缓冲区地址,然后使用RDMA操作来访问数据。在接收和反序列化过程中,接收器也可以用RDMAInputStream,以避免额外的内存复制。
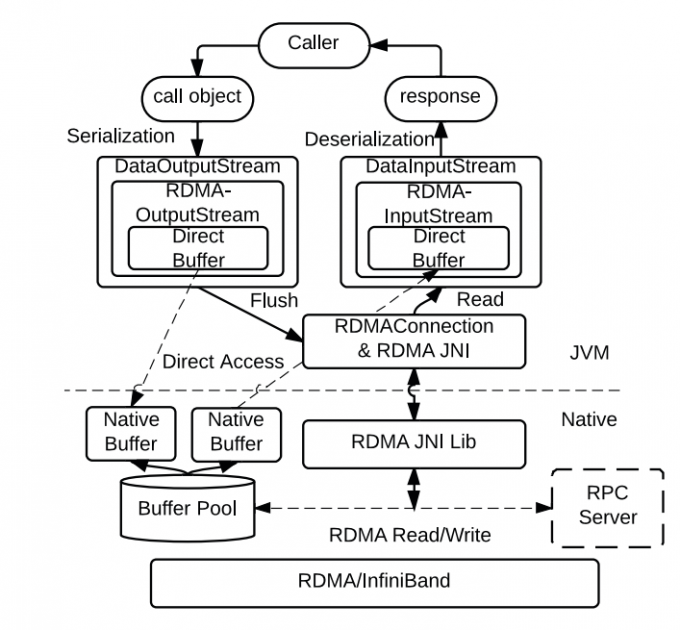
JVM 旁路缓冲区和通信管理中的RDMA输入和输出流
基于历史两级缓冲池:首先定义了一种元组。protocol时方法的类名,它需要Hadoop的RPC中注册。在整个MapReduce作业期间,许多类型的调用会保持很可靠的大小进行执行。然而。一些请求似乎有着不规则的消息大小。从图中可以看到JT_heartbeat 和NN_getFileInfo。

这表明,当得到一个缓冲区(具有适当尺寸)以处理当前调用时,缓冲区有较高的可能性利用与下一个调用相同的元组,这种现象被称为 Message Size Locality 因此人们提出可上图的缓冲池设计。
两级缓冲池模型如下:一个是本地内存池,另外一个是在JVM层的阴影池。阴影吃的内存缓冲来来自本地缓冲池,它指向本地缓冲区并提供Java层的DirectBuffer对象。
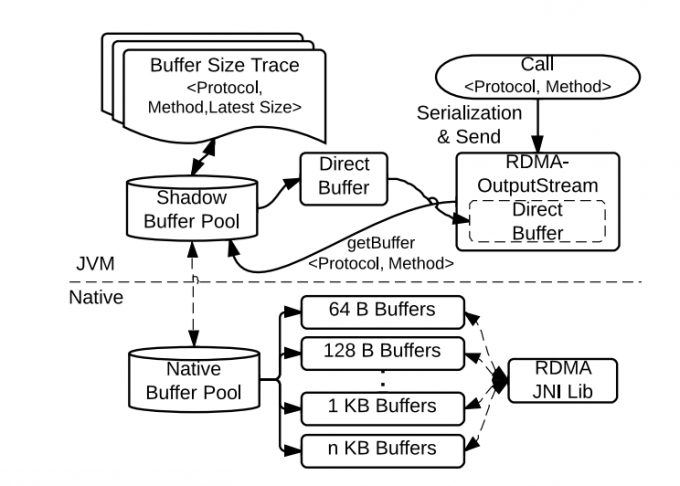
基于历史的两级缓存池
在默认Hadoop的RPC中,客户端客户端有两个主要线程一个是调用程序线程,它负责获取或创建连接,调用发送和等待来及RPC服务器的结果,另外一个是Connection进程。当RPC客户端希望使用远程过程调用时,首先与RPC服务器交换结束点信息。由于设计RDMAInputStream和RDMAOutputStream需要在Connection中修改setupIOStreams以提供基于RDMA的IO流。有了这个设计,可以看到,并不需要对现有的RPC并不惜要对RPC接口进行任何改变,这样可以与默认的Hadoop RPC 保持相同的接口语义和机制,因此,上层应用程序可以透明的使用这样的设计。
InfiniBand架构是一种支持多并发连接的“转换线缆”技术,在这种技术中,每种连接都可以2.5Gbit/s的运行速度。这种架构在一个连接的时候是500Mbit/s,4个链接的时候速度是2Gbit/s的运行速度,12个链接的时候速度可以达到6Gbit/s。
与当前计算机的I/O子系统不同,InfiniBand是一个功能完善的通信系统。InfiniBand贸易组织把这种新的总线结构称为I/O网络,并把它比作开关,因为所给信息寻求目的路径是由控制矫正信息决定的。InfiniBand使用的是IPv6的128位地址空间,因此它具有近乎无限量的设备拓展性。
论文
High-Performance Design of Hadoop RPC with RDMA over InfiniBand*.pdf

