
Mapreduce入门和优化方案
MapReduce基本原理和高性能网络下优化:
Mapreduce概述
Mapreduce式谷歌开源的一项重要技术,是一个编程模型,用来进行大数据量的计算,对于大数据量的计算通常采用的处理方式式并行计算,对于许多开发者来说,自己完全实现一个并行计算程序难度太大.而MapReduce就是一种简化并行计算的模型,它使得那些没有多少并行计算经验的开发人员也可以开发出并行计算应用程序,通过简化编程模型,降低了开发并行应用程序的难度。
工作原理
并行计算模型通常从并行计算的设计和分析出发,将各种并行计算机(至少某以类并行计算机)的基本特征抽象出来,形成一个抽象的计算模型,广义上来讲,并行计算模型为并行计算提供了硬件和软件界面。在该界面的约定下,并行计算软件和硬件设计者可以开发对并行那个计算支持的机制,从而提高系统性能。由代表性的并行计算 模型包括PRAM模型、BSP模型、LogP模型、C^3模型。
并行计算
同时使用多种计算资源解决计算问题的过程,是提高计算机系统计算速度和处理能力的一种有效手段,基本思想是:用多个处理器来协同求求解同一问题,即将被求解的问题分解成若干部分,各部分均由一个独立的处理机来并行计算,并行计算系统可以是专门设计的、包含多个处理器的超级计算机,也可以式以某种方式互连的若干台独立计算机构成的集群。通过并行计算集群完成数据的处理,再将处理的结果返回给用户。
并行计算处理系统
同时执行多个任务、多条指令或同时对多个数据项进行处理的计算机系统。主要包括以下两种类型的计算机:
-
同时能够多条指令或同时处理多个数据项的单中央处理器计算机。
-
多处理联机系统。
并行计算处理计算机的结构特点主要包括两个方面:
- 单机处理机内广泛采用各种并行措施。
- 由单处理机发展成各种不同耦合度的多处理系统。并行处理的主要目的式提高系统的处理能力。有些类型的并行处理计算机系统(如多处理机系统)还可以提高系统的可靠性。由于器件的发展,并行处理计算机系统具有良好的性能性价比,而且还有进一步提高的趋势。
Mapreduce工作原理
MapReduce是一个编程模型是处理和生成超大数据集的算法模型的相关实现。用于首先用一个Map函数处理一个基于键值对的数据集合,输出中间的基于键值对的数据集合;然后创建一个Reduce函数来合并所有的相同中间键(key)和中间值(value)对。MapReduce架构的程序能够在大量普通配置的计算机上实现并行化处理。这个系统运行时只关心:如何分隔输入数据,在大型计算机组成的集群上的调度,集中处理计算机的错误处理,管理集群中计算机之间的必要的通信 采用MapReduce架构,可以使那些没有并行计算和分布式处理系统开发经验的程序员有效利用分布式的资源。
设计这个抽象模型的灵感来自于Lisp和许多函数时语言的Map和Reduce原语:在输入数据的“逻辑”上应用Map操作得出一个中间键值对(key-value)集合,然后把所有的具有相同键值(key)的中间值(value)应用到Reduce操作,从而达到合并中间的数据得到想要的结果目的。使用MapReduce模型 ,结合用户自身需求实现Map和Reduce函数,可以十分容易实现大规模的并行化计算,MapReduce自带“再次执行”(re-execution)功能。也提供了初级的灾备实现方案,MapReduce框架模型让我们很容易地通过简单的接口来实现自动地并行化和大规模地分布式计算,通过MapReduce接口,实现大量普通的PC进行高效地并行计算。
通常计算节点和存储节点是在一起地。MapReduce框架和分布式文件系统HDFS运行在相同地节点上,这种配置允许框架在那些已经存好数据的节点上高效地调度,这可以使整个集群的网络带宽被非常高效地利用。
MapReduce计算模型
MapReuce编程框架适用于大数据计算:大数据管理、大数据分析、大数据清洗、大数据预处理。
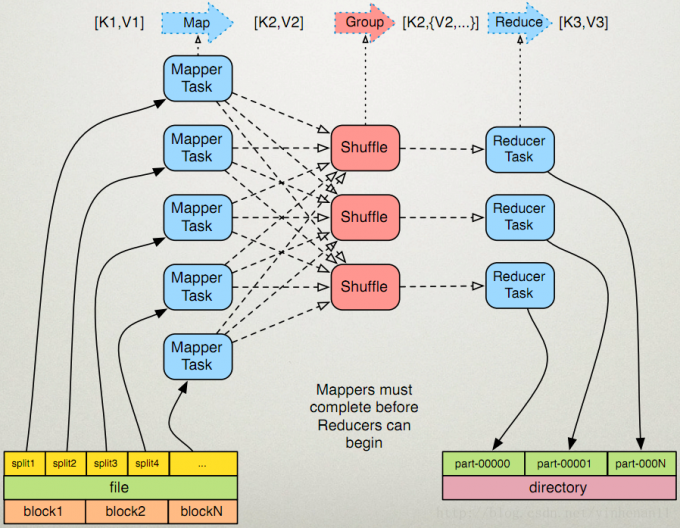
一个MapReduce作业(job)通常会把输入的数据集切分为若干独立的数据Block,用Map任务(task)以完全并行的方式处理它们。框架首先对Map输出先进行排序,然后结果输出给Reduce任务。典型的作业的输入输出都会被存储在文件系统中。整个框架负责任务的调度、监控、已失效的任务重新执行。 MapReduce在计算时分为几个步骤:
HDFS
存储大文件切分后的数据块,Block块大小为128M。
分片
进行Map计算之前,MapReduce会根据输入文件计算输入分片(input split),每个输入分片只针对一个Map任务,输入分片存储的给数据本身,而是一个分片长度和一个记录数据的位置的数组。

block分片并非完全是1:1关系,Hadoop1.x
默认的块大小是64M,Hadoop2.0之后默认的块大小是128M,可以再hdfs-site.xml中设置dfs.block.size,单位是Byte。minSplitSize的大小默认是1B,MaxSplitSize的大小默认是Long.MAX_VALUE=9223372036854775807。
分片大小的计算公式如下
minsize =max{minSplitSize,mapred.min.split.size}
maxSize=mappred.max.split.size
splitSize=max{minSize,min{maxSize,blockSize}}
Map
将输入键值对(key/value pair)映射到一组中间格式的键值对集合。Map的数目通常是由输入数据的大小决定的,一般就是所有输入文件的总块数(Block)。官网给参考值Map正常的并行规模是10~100个Map,对于CPU消耗比较小的Map任务可以设置到300个左右。由于每个任务初始化需要一定的事件,因此比较合理的情况是Map执行的事件至少超过1分钟。可以通过setNumMapTasks(Int)将这个数值设置得更高,Map任务数与Block对应关系会改变。
Shuffle
Hadoop的核心是MapReduce,而Shuffle是MapReduce的核心。Shuffle的主要任务是从Map结束到Reduce开始之间的过程。Shuffle阶段完成了数据的分区、分组、排序的工作,
Reduce
将与一个key关联的一组中间数值集归约(Reduce)为一个更小的数据集。Reducer时输入的是Mapper已经排序的输出。这个过程和排序两个阶段时同时进行的:Map的输出也是一边被取回。一边被合并的。Reducer的输出是没有被排序的。Reduce的数目建议是0.95或者1.78乘以(no. of nodes ∗
no. of maximum containers per node )。系数为0.95的时候所有Reduce可以再Map已完成就立即启动,开始计算Map的输出结果,系数是1.75的时候,速度快的节点可以再完成第一轮的Reduce任务后,立即开始第二轮,这样可以得到比较好的负载均衡效果。增加Reduce数目会增加整个框架的开销,但是可以改善负载均衡,降低由于执行失败带来的负面影响,上述比例因子比整体数目稍小一些,是为了给框架中的推测任务或失败任务预留一些Reduce资源,无Reducer时, 如果没有规约要求进行,那么设置Reduce的数目为0是合法的.这种情况下Map任务的输出会直接写入由setOutputPath(Path)指定的输出路径,框架再把他们写入FileSystem之前并没有对他们进行排序 。
输出:记录MapReduce结果的输出。
MapReduce经典案例
从HDFS上获取指定的Block进行分片后,将分片结果输如Mapper进行Map处理,讲解过输出给Shuffle完成分区,排序、分组的计算过程,之后计算结果会被Reducer指定业务进一步处理。
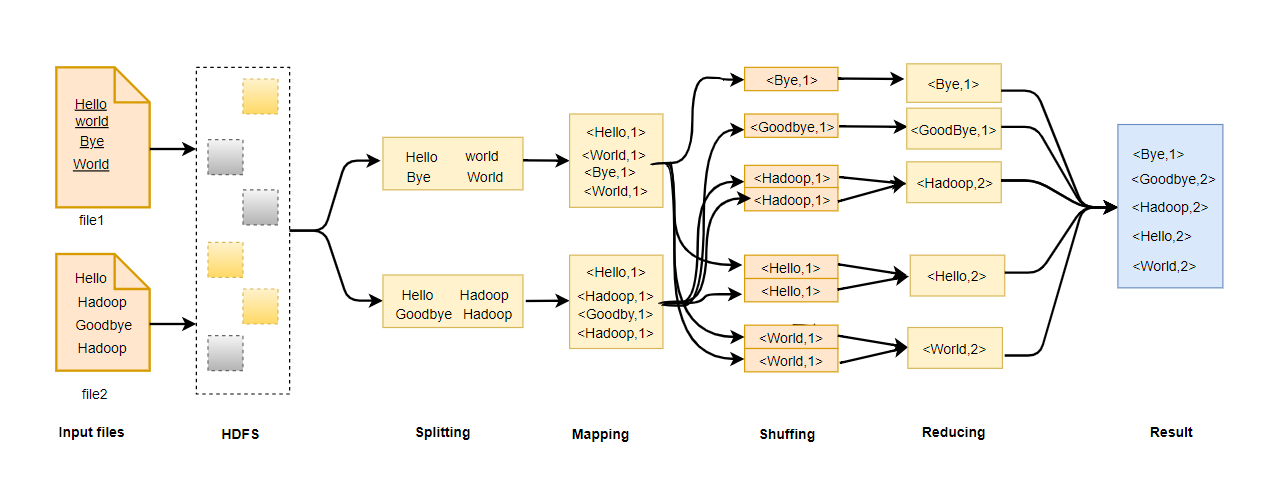
为了方便框架执行排序操作,key类必须实现WritableComparable接口。MapReduce输入和输出的类型描述。
(input) (k1,v1) →map→(k2,v2)→(combine → (k2,v2) →reduce →(k3,v3)(output)
MapReduce应用场景
MapReduce框架透明性强,易于编程、易拓展;对于宕机等原因导致的错误,容错性很强;能够处理PB级以上的海量数据的离线处理。单由于它的工作机制有延迟性,对于类似于Mysql这种毫秒级或者秒级内返回结果的情况达不到要求。MapReduce自身的设计特点决定了数据源必须必须时静态的,故不能处理动态变化的数据,如流式计算等。
由于在MapReduce的计算过程中,大量的数据需要经过Map到Reduce端的传送,故在进行一些如两张表或者多张表的Join计算时,通过Map任何分别将两表的文件记录处理成(Join Key, Value),然后按照Join Key做Hash分区后,送到不同的Reduce任务去处理。Reduce任务一般使用Nested Loop方式递归左表的数据,并便利右表的每一行,对于相等的Join Key,处理Join结果并输出。由于大量数据需要经过Map到Reduce端的传送,Join计算性能并不高。华为的FusionInsight擦产品对HDFS进行了文件快集中分布式的加强,使需要做关联和汇总计算的两张表FileA和FileB,通过或指定一个分布ID,使其所有的Block分布在一起,不需要再跨节点读取数据就能完成计算,极大地提高了MR Join地性能。
LATE:算法
Hadoop一个最大的优点是能够自动处理失败。如果一个节点坏了,Hadoop会将此节点的任务放到另一个节点上执行。同样地,工作但速度慢的节点称之为掉队节点,Hadoop会将此节点上的任务随机复制到另外一台机器上进行更快速的处理。此行为称之为推测执行。推测执行带来了如下几个难题:
- 推测执行要占用资源,如网络等。
- 选择节点和选择任务同样重要。
- 异构性能环境中,很难确定哪一个节点的速度慢。
Hadop被广泛应用用于短小任务中,其中应答时间是一个很重要的因素。Hadoop的性能与任务调度程序有着很大的关系,任务调度程序假定集群的节点均匀并且任务是线性执行的,根据这些假设决定何时重新执行掉队任务。事实上,集群并不一定是均匀的,如在虚拟数据中心就不具备均匀性。Hadop的任务在异构环境容易引起严重的性能退化。在亚马逊EC2的一个具有200个虚拟机的集群中,LATE调度算法可以缩短Hadoop的应答时间至原来的一半。
Hadoop的推测执行
当一个节点空闲时,Hadoop从3种任务中选择一个执行;第一种时失败任务,第二种是没有被执行任务,第三种是随机地选择一个任务,为了推测执行任务,Hadoop用一个进度得分来衡量任务的进度,最小值为0,最大值为1。对于Map来说,进度得分就是输入数据中被读入比例。对于Reduce来说,执行被分为3部分,任务读取Map结果,Map结果排序。以及Reduce任务执行。每部分为1/3,在每部分中,分数为被处理的数据比例。
Hadoop根据每类任务的平均得分来定义一个阈值,每当一个任务的进度得分小于该类任务的平均得分减去0.2,并且该任务运行了至少一分钟,那些任务可被看成掉队任务。调度程序保证每个任务最多只有一个被推测执行。
当运行多个任务时,Hadoop利用先进先出的规则,运行最早提交的任务,同样有一个优先级系统来提高任务的优先级。
Hadoop调度程序前提
每个节点的工作速率相同。一个任务执行速率始终保持一致。将一个任务复制到另一个节点时没有花销。一个任务的进度得分等于它被完成的比例。特别地,在一个Reduce阶段中,复制,排序、执行各占总时间的1/3。任务是成波浪型结束的,因此一个进度的得分低的任务更可能时掉队任务。同一种任务的工作量大致相等。
LATE调度程序的基本思想
每次选取最晚结束的任务来推测执行,从而极大地减少响应时间,有很多方法能够评估任务的剩余时间。可以 用一个简单的方法,此方法经过实验验证具有很好的效果。假设任务是以恒定的速度来执行,那么一个任务的进度根据公式ProgressScore/T
来估计,即每分钟处理的任务进度是多少。剩余时间根据公式(1−ProgressScore)/ProgressRate
来估计。
每次推测任务复制到快速执节点上运行,并且通过一个简单的机制来实现,即不要把任务复制到进度总分在阈值以下的节点中,其中进度总分为该节点所有已经完成及正在运行的任务的进度得分相加。
为了解决推测执行需要消耗资源的事实,用两个启发式方法来增强LATE算法。
- 每次同时能够执行的推测任务数设定一个上限,叫做SpeculativeCap。
- 一个任务的进度率需要与SlowTaskThreshold比较来决定其是否足够慢。这防止了全部任务均是快速任务,产生无意义的推测执行。
综上所述,LATE算法的工作流程如下。
当一个节点申请任务,并且执行的推测任务数小于上限,则:当此节点的总进程得分小于SlowNodeThreshold时,忽视请求;根据剩余时间将当前正在运行的非推测任务排序;将进度率低于SlowNodeThreshold的任务中排名最高的任务,复制到此节点。
与Hadoop类似,LATE算法仅仅对于执行至少一分钟的任务进行判断。LATE算法是一个简单、适应性强的程序调度算法、其有一系列的优点:首先,适合异构环境:其次,LATE算法在决定哪个节点来运行推测任务时考虑了异构节点;最后,通过强制估计剩余时间而不是进度率,LATE算法只推测执行能够缩短总时间的的任务。此算法通过估计任务剩余时间来推测地执行任务,并且能够最大限度地缩短响应时间。
Mantri:MapReduce 异常处理
MapReduce作业通常有无法预测的性能表现。一个作业由一个分阶段执行任务集合构成,这些任务会有前后依赖的关系——有的任务依赖于其他任务的计算结果。很多任务是并行的,如果一个任务的执行时间超过相似任务的时间,则依赖这个任务的结果的任务就都会被延迟。在一个作业中,少数几个这样的异常可以组织作业剩余任务的执行,甚至可以使作业执行时间增加34%。
Mantri 是一个能够监视任务并根据导致异常的原因来剔除异常的系统。它主要采用了以下的技术:
-
重启已经认识到资源约束和工作不均匀的异常任务;
-
根据集群网络环境情况安排任务;
-
根据开销-收益分析结果来保护任务的输出结果。
Mantri设计

如果一个任务因为争抢资源而延后,重启或者复制一份该任务已经完成的结果可以加快任务进度。不要在低宽带条件下进行跨机架的数据传送,如果这些无法避免,则需要一个系统的配置避免热点。为了加速那些正在等待已经丢失的输入的任务,使用一些方法来保护输出。最后,当遇到任务量分布不均匀的问题时,Mantri优先执行大的任务,以避免再快要完成作业时卡在大的任务上。
估计 trem
和 tnew
trem
表示完成一个正在运行中的任务所需要的剩余时间,tnew
表示重新运行该任务所需的时间。
计算trem
的模型:
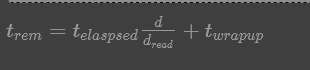
参数标识
dread
表示一个任务已经读取的数据量;
d
表示这个任务总数需要处理的数据量;
telaspsed
代表加工dread
所需的时间,所以前半部分代表加工剩余所需的时间;
twrapup
表示代表所有数据已经读取进来之后需要计算时间,这个时间时根据之前的任务进行评估的。
tnew
模型
计算模型:tnew=processRate∗locationFactor∗d+schedLag
Mantri的实现方法
实现重启的方法:Mantri使用两种不同的方法来实现重启。第一种杀死一个进程中的任务并在别的地方重新运行,第二种制作一个这个任务的副本。执行这两种方法均需要一个条件,及P{tnew< trem} 比较大。
配置任务的方法:已知任务链接情况和输入数据的位置,使用一个中心调度机制可以最优地对所有任务进行配置,但是这要求掌握实时地网络信息和中心调度机,进行大量地协调计算。Mantri没有采用这种方法,而是采用了以中近似最优的算法,这种算法时根据集群网络情况配置任务的,既不需要知道实时网络情况,也不需要进行作业间的协调工作。
避免重新计算的方法:为了减轻重新计算造成的作业完成时间的增加,Mantri通过复制任务的输出结果来避免数据丢失的问题。
Mantri最根本的优势在于它将静态的MapReduce作业的结构和在运行过程中动态获取的信息整合在一个完整的框架里。这个框架可以依据整合的信息发现异常,对可以采取的针对性措施、可以获得的收益和消耗进行衡量,如果值得采取,就实施针对性措施。
SKewTune:MapReduce中数据偏斜处理
对于很多运行在该平台的应用来说:数据偏斜是一个显著的挑战。当数据偏斜发生的时候,一些分区的操作在处理输入数据时,比其他分区花费的时间更长,造成了整个计算时间变长。一个MapReduce工作主要由Map阶段和Reduce阶段组成。在每个阶段,输入数据的一个子集被计算机集群进行分布式任务处理。Map任务完成后通知Reduce任务接收新的可用数据,这个转换过程被称为重分配,直到所有的Map任务完成后,Reduce阶段的重分配才完成,然后开始Reduce操作,负载不均衡可能发生在Map阶段,也可以发生在Reduce阶段,数据偏斜会显著增加作业执行时间,以及降低吞吐率 。
Map阶段
高代价记录,Map任务一个接一个处理由键值对组成的一系列记录.理想情况下处理事件在不同的记录之间的差距不大. 然而根据不同的应用,有些记录可能需要更多的CPU和内存.这些高代价记录可能比其他的记录大,也可能是Map算法的运行时间取决于记录的值。
异构的Map,MapReduce是一个一元运算符,但是也可以通过逻辑级联多个数据集,作为一个单一的输入和模拟实现n
元运算。每个结果集可能需要不同的处理,从而不导致运行时间是多峰分布。
Reduce阶段
分区偏移。在MapReduce中,Map任务的输出会通过默认的散列分区或者用户自定义分区逻辑分布在不同的Reduce任务。默认散列分区通常是足够的均匀分布数据。然而散列分区不保证均匀分布。
高代价的关键字组。在MapReduce中Reduce任务处理(关键字、值域)对序列,被称为关键字组。类似于Map任务处理高代价记录一样,高代价关键字会造成Reduce运行时间的偏移。
数据偏斜是一个众所周知的问题,已经在数据库管理系统、自适应和流处理系统中被广泛研究。
以往的解决方案都会产生其他的代价或者有较为严格的要求,而SkewTune不要求来自用户的输入,它被广泛使用,因为它并不是探究是什么原因导致数据偏斜发生的,而是观察工作的执行,重新均衡负载,使资源变得可用。当集群中的一个节点空闲时,SkewTune通过最大预期的剩余处理时间来标识任务,然后这个任务的未处理输入数据会主动的地重新分区,重分区会充分利用集群中的节点,并且会保留输入数据的顺序,使原始输出可以通过串联来重建。
SkewTune是一个共享集群,SkewTune假定一个用户可以访问集群中的所有的资源,在共享集群中和有两种方法来使用SkewTune:
- 用一个任务调度程序为每个用户定义一个资源集。
- 通过实施SkewTune 感知调度程序来优化缓存器。

SkewTune 设计用于设计MapReduce的引擎,特征在于通过基于磁盘的处理和面向记录的数据模型。通过拓展Hadoop并行数据处理系统来实现SkewTune技术。SkewTune通过优化在减小数据偏斜的同时,还能保持容错和MapReduce的可扩展性。
特点
-
SkewTune能够减少两种非常常见的数据偏斜:由于操作分区的数据不均匀造成的数据偏斜和由于一些数据子集执行花费时间比其他的数据子集长造的数据偏斜。
-
SkewTune可以优化为修改的MapReduce程序;程序员不需要改变代码。
-
SkewTune保持其他UDO(User Defined Operations,用户自定义操作)的互操作性,它保证没有在SkewTune下执行时,数据以相同的排序序列出现在每个分区内,并且操作的输出由同样数的分区组成。
-
SkewTune与流水线优化兼容,它不要求连续的操作之前的同步屏障。
设计理念
- 开发者透明:让MapReduce开发者开发出高性能的产品更加容易。研究者希望SkewTune是一个改进版的运行更快的Hadoop。不用开发者使用任何特殊的模板来完成任务。或者需要他们进行类似于代价函数这样的输入。
- 解决方案透明:设计者希望使用SkewTune与不使用SkewTune的输出是一样,包括同样数量的文件和同样的顺序。
- 最大的适用性: 在MapReduce中或者其他的并行数据数据处理系统中,很多因素可以导致UDO的数据倾斜。设计者希望SkewTune能够处理各种不同的数据倾斜,而不是针对一种数据倾斜,它监控执行,并且在数据倾斜发生时发出通知,做出相应的响应,而不是纠结是什么原因导致任务变慢了。
- 没有同步屏障:并行数据处理系统尽量减少全局同步的屏障,以确保高性能并能够增量产出。即使在MapReduce种,Reducer也可以在Mapper执行完之前开始复制数据。此外新的MapReduce扩展力图促进流水线操作。因此,Skew Tune避免任何设计方案要求阻塞。
SkewTune假设MapReduce工作遵循API的规定:每个map()和reduce()函数调用时独立的。这个假设使SkewTune自动缓解数据偏斜技术。因为重新在Map函数和Reduce函数调用边界分区输入数据使安全的,不会破坏程序的逻辑性。
SkewTune实现方法简介:SkewTune以Hadoop的任务作为输入,将任务Map和Reduce阶段看作是独立的,SkewTune的数据偏斜环节技术被设计用于MapReduce的类型的数据处理引擎。
这些引擎在数据偏斜处理时有以下的重要的特征:
- 一个协调 —— 工作架构:其中协调节点做出调度决策,而工作节点运行分配给他们的任务。一个任务完成后,工作节点从协调节点哪里获取新的任务。
- 去耦执行:一个操作符不会对它的前一个操作符产生反馈,二者彼此独立。
- 独立处理记录:执行一个UDO时每条记录都是独立的。
- 任务进度估计:估计剩余时间,然后工作节点定期传给协调节点。
- 任务统计:跟踪一些基本的统计,例如处理过的或者为处理过的数据大小或记录数。
SkewTune工作原理如图:
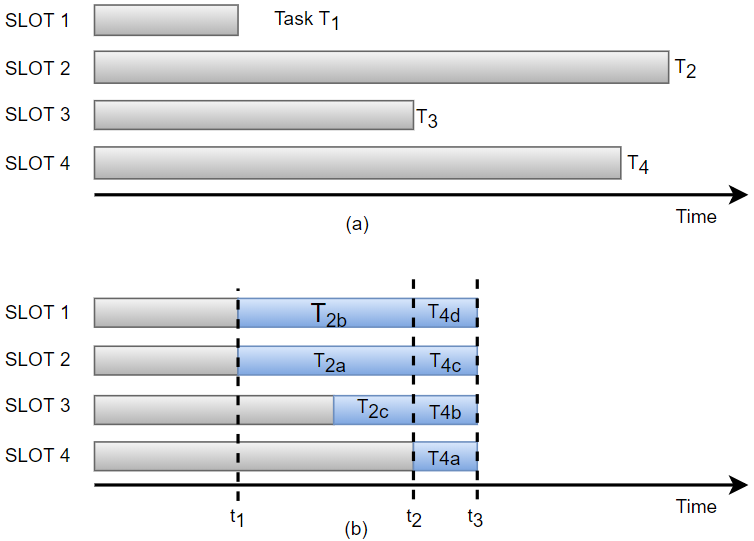
(a)显示了在没有SkewTune时,发生数据偏斜后的运行时间有最慢的任务T2决定;
(b)显示了在使用SkewTune后,在任务T1完成后检测到了数据偏斜,此时标记T2为落后者,然后重新分区T2种未处理完的数据。系统会根据剩余的数据全部分给T1、T2、T3者三个节点而不仅仅时分配给了T1、T2两个节点。这样T3结束后也可以继续工作,从图中也可以看出,重新分配的目的是保证任务是同时完成的。重新分配后的子任务T2a、T2b、T2c被称作mitigators。SkewTune重复这个检测-减少循环。当检到T4的剩余未处理数据重新分区。检测时间太早会导致任务拆分,从而造成不必要的开销,太晚会错过最佳时间,从而使减缓数据偏斜的效果变得更差。
对于整个过程有如下的解释:
-
后数据偏斜检测:由于任务在连续的阶段使彼此分离的,也就是说,Map任务尽可能地输入数据,产生输出结果,不会因为等待Reduce任务取走输出结果而阻塞。同时Reduce任务也不会因为连续的Map任务中阻塞。因此SkewTune采用延缓数据偏斜矫正、直到有空闲的节点处理的策略,类似于MapReduce种的预测推测执行机制。重新分配开销只发生在有闲置资源时,从而降低了误报率,同时通过立即给空闲节点分配资源来避免漏报。
-
识别落后者:一次识别并重分配一个落后任务是最有利的。SkewTune通过估计最大剩余时间来落后任务。
-
标记数据偏斜的原则:剩余处理时间的一半大于重分区的开销,即 Tremain2>w
,即式中w
式在30s的量级上的,也就是说任务剩余时间在1min以上才会出发重分区。
因而我们得到了下属数据的偏斜检测算法:
算法1:数据偏斜检测算法。
输入:R是正在执行的任务集;W未为调度等待中的任务及;inProgress为全局表示,指导数据偏斜减缓。
输出:一个任务调度。
task<-null if w ≠ φ then task<-chooseNextTask(W) //ChoseNextTask()为普通任务调度函数 else if inProgress ≠ 0 ≠ φ then task<-argmax time_remain(task) //其中task∈R,这就是要找到的最大的剩余时间任务 if task ≠ φ && time_remain(task)>2*w then //时间满足上式公式 stopAndMitigate(task) //通知被选中的任务停止任务,并提交处理玩的输出。 task=NULL inProgress<-true; end if end if
SkewTune实现数据偏斜减缓的原则如下:尽量减少重分区次数以减少重分区开销(通过标识一个落后者);尽量减少重分区的可见副作用以实现透明度(使用范围分区);尽量减少总的开销(使用一种廉价的、线性时间的启发式算法)。
算法步骤:
停止落后的算法:协调者通知落后者停止运算,并且记录下最后处理的位置,然后对剩余数据重分区。如果发生落后者处在不能停下来或者很难停下来的状态时,协调者选择另外一个落后者,或者如果该落后者是最后一个任务,重分区该后者的整个输入。
扫描剩余数据:为了保证数据倾斜减缓的透明性,SkewTune使用范围分区分配工作给mitigator,这样能够保证数据顺序保持不败你。如果使用Hash函数的方式不能保证均匀分派。范围分配落后者的剩余输入数据需要收集剩余数据的一些信息,SkewTune采用了对输入数据的压缩摘要来收集,摘要使用了一些列关键字间隔的方式,每个间隔大致相等。
选择间隔大小|S|标识集群的总节点数,Δ标识未处理的字节数。由于SkewTune想要分配不均匀的工作量给不同的mitigator,所以生成了 k∗|S|
个间隔,实现更细粒度的数据分配,但他们也通过增加数量增加了开销。
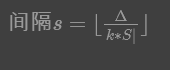
算法2:间隔生成算法。
输入:I为有序间隔流;b为初始单位间隔字节大小,在本地扫描中被设置为s;s为目标单位间隔字节大小,也就是阈值;k为间隔的最小值,在本地扫描中被忽略。
输出:间隔列表。
result = NULL
cur = new_interval() (当前间隔)
for all i ∈ I do
if i.bytes>b || cur.bytes>=b then
if b<s then
result.appendIfnotEmpty(cur)
if |result|>=2*k then
b=min{2*b,s}
result=GenerateIntervals(result,b,b,k)
end if
else
result.appendInNotEmpty(cur)
end if
cur = i
else
cur.updateStat(i)
cur.end=i.end
end if
end for
result.appendIfnotEmpty(cur)
return result
选择本地扫描或者并行扫描;SkewTune会比较两种选择的开销。对于本地扫描,Δ标识剩余输入数据的字节,β标识本地磁盘带宽,时间为 Δ/β,对于并行扫描,时间为安排一个额外的MapReduce任务和该任务完成需要时间之和。后者等于最慢的节点(设为n)需要的时间
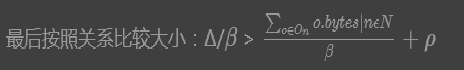
SkewTune实现方法的规划减缓器;目标是找到一个连续的、保持顺序的分配间隔给mitigator由于规划算法在减缓数据偏斜流程的关键路径上,为此要求速度足够快。因此人们提出了具有线性时间复杂度的启发式算法。
该算法分为两个阶段,第一个阶段计算最快的完成时间opt(假设能够对剩余的工作完美分隔),当一个节点的分配工作小于2 x w
时,停止以防止产生任意小碎片。在第二个阶段中,算法依次给最早可用的减缓器分配的间隔值,不但重复,直到分配完所有的间隔。时间复杂度为O(|I|+|S|+log|S|),其中I是间隔数目,S
是集群中的节点数。
SkewTune能够显著地减少作业在偏斜状态下的工作时间,并且对没有偏斜的开销增加很小,SkewTune同样能够保证输出 和初始未优化的顺序和分区特性,使平台和现有的代码兼容。
基于RDMA的MapReduce设计:
由于Map和Reduce过程得到的数据可能分布在不同聚类中,网络性能在考察使用Hadoop MapReduce框架实现的数据密集的应用程序的性能上起到关键作用。由于大数据应用的数据集常有TB或者PB量级,基于Hadoop MapReduce 框架中默认的基于Socket通信模型的数据传输方式成为系统性能的瓶颈。为了避免这种潜在的瓶颈,企业数据中心的开发者开始使用高性能互联网技术(如InfiniBand)网络来提升其大数据应用的性能和规模。虽然这样的系统正在被使用。当前的Hadoopn中间层组件还不能完全利用由InfiniBand所提供的高性能通信功能,研究分析指出,在InfiBand网络使用不同的云计算中间件,可带来性能上的巨大地飞跃。所以当一个高性能网络存在时,人们不得不重新思考Hadoop系统地设计方案。由此,人们提出了一种在InfiniBand网络上基于RDMA的Hadoop MapReduce的设计。这种InfiniBand网络基于MapReduce新的设计方案及检索中间数据的高效预取和高速缓存机制表现良好。

上图是实现Hadoop MapReduce框架的两种设计方案(a)是通常的设计方案,(b)是通常的设计方案,是基于RDMA的设计方案。在图(a)中默认的MapReduce工作流程中,映射输出被保存在本地磁盘上的文件,可以通过TaskTracker访问,在运行ReduceTask、Shuffle、Readuc的过程中,系统通过HTTP提供的这些映射输出。(b)是基于RDMA的MapReuce设计,在经历Shuffle阶段,该设计修改了TaskTracker和ReduceTask两者,以充分发挥RDMA的好处,而不是使用HTTP协议。
关键技术
基于RMDA的shuffle设计
在重排阶段,为了实现RDMA的好处,修改了TaskTracker和ReduceTask。
TaskTracker增加以下的心组件。
RDMA监听器
每个TaskTracker创建的时候有一个RDMA监听器。Tasker中的RDMA监听器从ReduceTask发来连接请求,并预先建立的队列中添加一个链接,在有需要的情况下启动RDMA接收器。UCR作为一个建立在终端的连接库,一个终端与一个Socket连接相似。RDMA监听器使用UCR连接终端并未每个终端分配响应的缓存。
RDMA接收器
每个RMDA接收器对应来及ReduceTask的请求做出响应,RDMA接收器获得终端列表,并从终端接收请求。当收到请求时,其把请求放入DataRequest队列中。
DataRequest队列
DataRequest队列用来保存ReduceTask中得到的所有请求。其中从RDMA接收获取并保存储存这些请求,直到RMDA相应其开始进一步处理。
RMDA 响应器
RDMA响应器从属于一个等待从DataRequest队列输入请求的线程池。每当DataRequest队列获得一个新的请求,RDMA响应器的一个会对请求做出响应,其是一个轻量级的线程,在发送响应后,如果没有其他请求,就会进入等待状态。
ReduceTask增加了RDMA备份器:
在原来的MapReduce设计中,备份线程响应TaskTracker的请求数据并未Merge操作排序数据。同样的,RDMACopier请求发给TaskerTrackers,并把数据存储到DataToMerge队列等候合并操作。
快速Merge设计
在MapReduce默认设计中,每个HTTP响应由整个Map的输出文件组成,并将其划分到多个数据包中,在使用高性能网络后,通信时间显著降低,这使一次完成向多个通信步骤传输Map输出文件成为可能。这样,就可以在一些键值对从Map输出到归约器的瞬间合并。因此,在设计中RMDA响应器的一侧TaskTracker发送一定数量的键值对,其发生在Map输出的开始部分而不是整个Map。在接收来自所有Map位置的键值对的同时,一个ReduceTask合并所有这些数据,建立一个优先队列。然后,它不断从优先队列中提取按顺序排序的键值对,并把这些数据写入到一个先入先出的结构体DataToReduce队列中。当每个Map输出文件已经再Map中排序时,ReduceTask的合并操作只有从优先级队列中提取数据,直到来自特定Map的键值对数目减少到零。此时,它需要从特定Map任务得到下一组键值对,并写入到优先队列中。
中间数据预提取和缓存
为了确保TaskTracker更快地响应,本地磁盘中地映射输出文件地中间数据要有一个高效地缓存机制。
TaskTracker在缓存时添加了MapOutput预提取器,MapOutput预提器。MapOutput预提器时用于尽可能快速地缓存那些中间映射输出地守护线程池。完成一个任务映射后,守护进程地一个进程开始从该映射输出数据。并缓存再本地预提取缓存中。这个缓存的新功能就是它可以根据数据获得的难易程度和必要性调整缓存、可以更迅速地根据Reduce Task需求任务优先进行缓存。
论文
SkewTune:Mitigating Skew in Mapreduce Applications.pdf
High-Performance Design of Hadoop RPC with RDMA over InfiniBand.pdf
