
Sqoop
Sqoop的基本原理和相关参数配置:
简介
Sqoop(发音:skup)是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql、postgresql…)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
Sqoop项目开始于2009年,最早是作为Hadoop的一个第三方模块存在,后来为了让使用者能够快速部署,也为了让开发人员能够更快速的迭代开发,Sqoop独立成为一个Apache项目。
原理
导入
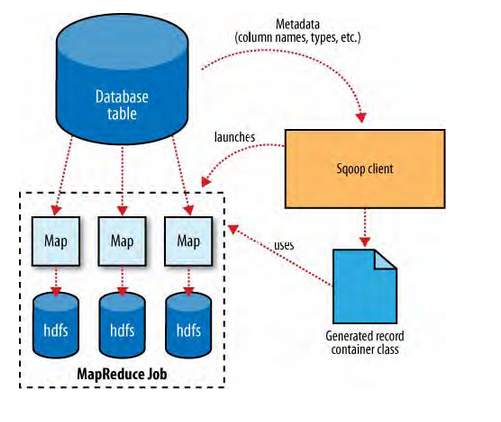
在导入开始之前,Sqoop使用JDBC来检查将要导入的表。他检索出表中所有的列以及列的SQL数据类型。这些SQL类型(VARCHAR、INTEGER)被映射到Java数据类型(String、Integer等),在MapReduce应用中将使用这些对应的java类型来保存字段的值。Sqoop的代码生成器使用这些信息来创建对应表的类,用于保存从表中抽取的记录。例如前面提到过的example类。
对于导入来说,更关键的是DBWritable接口的序列化方法,这些方法能使Widget类和JDBC进行交互:
Public void readFields(resultSet _dbResults)throws SQLException;
Public void write(PreparedStatement _dbstmt)throws SQLException;
JDBC的ResultSet接口提供了一个用户从检查结果中检索记录的游标;这里的readFields()方法将用ResultSet中一行数据的列来填充Example对象的字段。
Sqoop启动的MapReduce作业用到一个InputFormat,他可以通过JDBC从一个数据库表中读取部分内容。Hadoop提供的DataDriverDBInputFormat能够为几个Map任务对查询结果进行划分。为了获取更好的导入性能,查询会根据一个“划分列”来进行划分的。Sqoop会选择一个合适的列作为划分列(通常是表的主键)。
在生成反序列化代码和配置InputFormat之后,Sqoop将作业发送到MapReduce集群。Map任务将执行查询并将ResultSet中的数据反序列化到生成类的实例,这些数据要么直接保存在SequenceFile文件中,要么在写到HDFS之前被转换成分割的文本。
Sqoop不需要每次都导入整张表,用户也可以在查询中加入到where子句,以此来限定需要导入的记录:Sqoop –query (SQL)。
导入和一致性:在向HDFS导入数据时,重要的是要确保访问的是数据源的一致性快照。从一个数据库中并行读取数据的MAP任务分别运行在不同的进程中。因此,他们不能共享一个数据库任务。保证一致性的最好方法就是在导入时不允许运行任何进行对表中现有数据进行更新。
导出
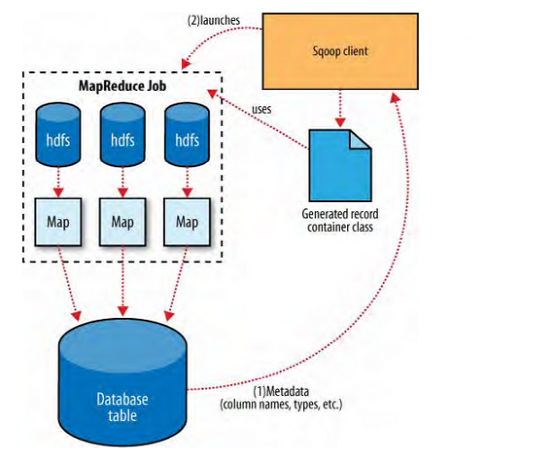
Sqoop导出功能的架构与其导入功能非常相似,在执行导出操作之前,sqoop会根据数据库连接字符串来选择一个导出方法。一般为jdbc。然后,sqoop会根据目标表的定义生成一个java类。这个生成的类能够从文本文件中解析记录,并能够向表中插入类型合适的值。接着会启动一个MapReduce作业,从HDFS中读取源数据文件,使用生成的类解析记录,并且执行选定的导出方法。
基于jdbc的导出方法会产生一批insert语句,每条语句都会向目标表中插入多条记录。多个单独的线程被用于从HDFS读取数据并与数据库进行通信,以确保涉及不同系统的I/O操作能够尽可能重叠执行。
虽然HDFS读取数据的MapReduce作业大多根据所处理文件的数量和大小来选择并行度(map任务的数量),但sqoop的导出工具允许用户明确设定任务的数量。由于导出性能会受并行的数据库写入线程数量的影响,所以sqoop使用combinefileinput类将输入文件分组分配给少数几个map任务去执行。
系统使用固定大小的缓冲区来存储事务数据,这时一个任务中的所有操作不可能在一个事务中完成。因此,在导出操作进行过程中,提交过的中间结果都是可见的。在导出过程完成前,不要启动那些使用导出结果的应用程序,否则这些应用会看到不完整的导出结果。
更有问题的是,如果任务失败,他会从头开始重新导入自己负责的那部分数据,因此可能会插入重复的记录。当前sqoop还不能避免这种可能性。在启动导出作业前,应当在数据库中设置表的约束(例如,定义一个主键列)以保证数据行的唯一性。
Sqoop还可以将存储在SequenceFile中的记录导出到输出表,不过有一些限制。SequenceFile中可以保存任意类型的记录。Sqoop的导出工具从SequenceFile中读取对象,然后直接发送到OutputCollector,由他将这些对象传递给数据库导出OutputFormat。为了能让Sqoop使用,记录必须被保存在SequenceFile键值对格式的值部分,并且必须继承抽象类com.cloudera.sqoop.lib.SqoopRecord。
安装
-
上传安装包sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz到虚拟机中
-
软件到指定目录
[hadoop@datanode1 software]$ tar -zxvf sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz -C /opt/module/ [hadoop@datanode1 module]$ mv sqoop-1.4.6.bin__hadoop-2.0.4-alpha/ sqoop
4. 修改配置文件
[hadoop@datanode1 conf]$ mv sqoop-env-template.sh sqoop-env.sh [hadoop@datanode1 conf]$ mv sqoop-site-template.xml sqoop-site.xml
修改配置文件sqoop-env.sh
#Set path to where bin/hadoop is available export HADOOP_COMMON_HOME=/opt/module/hadoop #Set path to where hadoop-*-core.jar is available export HADOOP_MAPRED_HOME=/opt/module/hadoop #set the path to where bin/hbase is available export HBASE_HOME=/opt/module/hbase #Set the path to where bin/hive is available export HIVE_HOME=/opt/module/hive #Set the path for where zookeper config dir is export ZOOKEEPER_HOME=/opt/module/zookeeper-3.4.10/ export ZOOCFGDIR=$ZOOKEEPER_HOME/conf
拷贝JDBC驱动sqoop的lib目录下
cp -a mysql-connector-java-5.1.27-bin.jar /opt/module/sqoop/lib
验证Sqoop
[hadoop@datanode1 sqoop]$ bin/sqoop help Warning: /opt/module/sqoop/bin/../../hcatalog does not exist! HCatalog jobs will fail. Please set $HCAT_HOME to the root of your HCatalog installation. Warning: /opt/module/sqoop/bin/../../accumulo does not exist! Accumulo imports will fail. Please set $ACCUMULO_HOME to the root of your Accumulo installation. ----------------------------------------------------------------------------------------- ##上面的警告可以忽略 19/01/08 13:35:58 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6 usage: sqoop COMMAND [ARGS] Available commands: codegen Generate code to interact with database records create-hive-table Import a table definition into Hive eval Evaluate a SQL statement and display the results export Export an HDFS directory to a database table help List available commands import Import a table from a database to HDFS import-all-tables Import tables from a database to HDFS import-mainframe Import datasets from a mainframe server to HDFS job Work with saved jobs list-databases List available databases on a server list-tables List available tables in a database merge Merge results of incremental imports metastore Run a standalone Sqoop metastore version Display version information See 'sqoop help COMMAND' for information on a specific command.
测试是否成功连接数据库
[hadoop@datanode1 sqoop]$ bin/sqoop list-databases --connect jdbc:mysql://datanode1:3306/ --username root --password 123456 19/01/08 13:38:11 INFO sqoop.Sqoop: Running Sqoop version: 1.4.6 19/01/08 13:38:11 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead. 19/01/08 13:38:12 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset. information_schema metastore mysql mysqlsource performance_schema [hadoop@datanode1 sqoop]$
案例
导入数据
RDBMS到HDFS
mysql) create database student; mysql) create table student.class(id int(4) primary key not null auto_increment, name varchar(255), age int);
数据库脚本
[hadoop@datanode1 sqoop]$ vim mysql.sh
STNAME="192.168.1.101" #数据库信息
PORT="3306"
USERNAME="root"
PASSWORD="123456"
DBNAME="student" #数据库名称
TABLENAME="class" #数据库中表的名称
for ((i=1;i(=100;i++)) ##添加100条数据
do
insert_sql="insert into ${TABLENAME}(name,age) values('student_$i',($RANDOM%4)+18)"
mysql -h${HOSTNAME} -P${PORT} -u${USERNAME} -p${PASSWORD} ${DBNAME} -e "${insert_sql}"
全部导入
bin/sqoop import \ --connect jdbc:mysql://datanode1:3306/student \ --username root \ --password 123456 \ --table class \ --target-dir /student/class \ --delete-target-dir \ --num-mappers 1 \ --fields-terminated-by "\t"
查询导入
bin/sqoop import \ --connect jdbc:mysql://datanode1:3306/student \ --username root \ --password 123456 \ --target-dir /student/class_query \ --delete-target-dir \ --num-mappers 1 \ --fields-terminated-by "\t" \ --query 'select name,age from class where id (=20 and $CONDITIONS;'
注意:must contain ‘$CONDITIONS’ in WHERE clause.
如果query后使用的是双引号,则$CONDITIONS前必须加转移符,防止shell识别为自己的变量。
—query选项,不能同时与—table选项使用
导入指定列
bin/sqoop import \ --connect jdbc:mysql://datanode1:3306/student \ --username root \ --password 123456 \ --target-dir /student/ \ --delete-target-dir \ --num-mappers 1 \ --fields-terminated-by "\t" \ --columns id,name \ --table class
注意:columns中如果涉及到多列,用逗号分隔,分隔时不要添加空格
使用sqoop关键字筛选查询导入数据
bin/sqoop import \ --connect jdbc:mysql://datanode1:3306/student \ --username root \ --password 123456 \ --target-dir /student/limit \ --delete-target-dir \ --num-mappers 1 \ --fields-terminated-by "\t" \ --table class \ --where "id(10"
RDBMS到Hive
bin/sqoop import \ --connect jdbc:mysql://datanode1:3306/student \ --username root \ --password 123456 \ --table class \ --num-mappers 1 \ --hive-import \ --fields-terminated-by "\t" \ --columns name,age \ --hive-overwrite \ --hive-table class_hive
该过程分为两步:
第一步将数据导入到HDFS 默认临时目录是/user/admin/表名
第二步将导入到HDFS的数据迁移到Hive仓库
RDBMS到HBase
bin/sqoop import \ --connect jdbc:mysql://datanode1:3306/student \ --username 'root' \ --password '123456' \ --table 'class' \ --hbase-table 'test' \ --hbase-row-key 'id' \ --column-family 'info'
需要先创建hbase表
导出数据
HIVE到RDBMS
bin/sqoop export \ --connect jdbc:mysql://datanode1:3306/student \ --username root \ --password 123456 \ --table class_from_hive \ --num-mappers 1 \ --export-dir /user/hive/warehouse/class_hive \ --input-fields-terminated-by "\t"
表要先创先好
HDFS到RDBMS
mkdir opt vi opt/job_HDFS2RDBMS.opt export --connect jdbc:mysql://linux01:3306/company --username root --password 123456 --table staff --num-mappers 1 --export-dir /user/hive/warehouse/staff_hive --input-fields-terminated-by "\t" bin/sqoop --options-file opt/job_HDFS2RDBMS.opt
Sqoop 常用参数
import
| 序号 | 参数 | 说明 |
|---|---|---|
| 1 | —enclosed-by (char) | 给字段值前后加上指定的字符 |
| 2 | —escaped-by (char) | 对字段中的双引号加转义符 |
| 3 | —fields-terminated-by (char) | 设定每个字段是以什么符号作为结束,默认为逗号 |
| 4 | —lines-terminated-by (char) | 设定每行记录之间的分隔符,默认是\n |
| 5 | —mysql-delimiters | Mysql默认的分隔符设置,字段之间以逗号分隔,行之间以\n分隔,默认转义符是\,字段值以单引号包裹。 |
| 6 | —optionally-enclosed-by (char) | 给带有双引号或单引号的字段值前后加上指定字符。 |
export
| 序号 | 参数 | 说明 |
|---|---|---|
| 1 | —input-enclosed-by (char) | 对字段值前后加上指定字符 |
| 2 | —input-escaped-by (char) | 对含有转移符的字段做转义处理 |
| 3 | —input-fields-terminated-by (char) | 字段之间的分隔符 |
| 4 | —input-lines-terminated-by (char) | 行之间的分隔符 |
| 5 | —input-optionally-enclosed-by (char) | 给带有双引号或单引号的字段前后加上指定字符 |
hive
| 序号 | 参数 | 说明 |
|---|---|---|
| 1 | —hive-delims-replacement (arg) | 用自定义的字符串替换掉数据中的\r\n和\013 \010等字符 |
| 2 | —hive-drop-import-delims | 在导入数据到hive时,去掉数据中的\r\n\013\010这样的字符 |
| 3 | —map-column-hive (map) | 生成hive表时,可以更改生成字段的数据类型 |
| 4 | —hive-partition-key | 创建分区,后面直接跟分区名,分区字段的默认类型为string |
| 5 | —hive-partition-value (v) | 导入数据时,指定某个分区的值 |
| 6 | —hive-home (dir) | hive的安装目录,可以通过该参数覆盖之前默认配置的目录 |
| 7 | —hive-import | 将数据从关系数据库中导入到hive表中 |
| 8 | —hive-overwrite | 覆盖掉在hive表中已经存在的数据 |
| 9 | —create-hive-table | 默认是false,即,如果目标表已经存在了,那么创建任务失败。 |
| 10 | —hive-table | 后面接要创建的hive表,默认使用MySQL的表名 |
| 11 | —table | 指定关系数据库的表名 |
| 序号 | 命令 | 类 | 说明 |
|---|---|---|---|
| 1 | import | ImportTool | 将数据导入到集群 |
| 2 | export | ExportTool | 将集群数据导出 |
| 3 | codegen | CodeGenTool | 获取数据库中某张表数据生成Java并打包Jar |
| 4 | create-hive-table | CreateHiveTableTool | 创建Hive表 |
| 5 | eval | EvalSqlTool | 查看SQL执行结果 |
| 6 | import-all-tables | ImportAllTablesTool | 导入某个数据库下所有表到HDFS中 |
| 7 | job | JobTool | 用来生成一个sqoop的任务,生成后,该任务并不执行,除非使用命令执行该任务。 |
| 8 | list-databases | ListDatabasesTool | 列出所有数据库名 |
| 9 | list-tables | ListTablesTool | 列出某个数据库下所有表 |
| 10 | merge | MergeTool | 将HDFS中不同目录下面的数据合在一起,并存放在指定的目录中 |
| 11 | metastore | MetastoreTool | 记录sqoop job的元数据信息,如果不启动metastore实例,则默认的元数据存储目录为:~/.sqoop,如果要更改存储目录,可以在配置文件sqoop-site.xml中进行更改。 |
| 12 | help | HelpTool | 打印sqoop帮助信息 |
| 13 | version | VersionTool | 打印sqoop版本信息 |
Sqoop常用命令
import
- 导入数据到HIVE中
bin/sqoop import \ --connect jdbc:mysql://datanode1:3306/student \ --username root \ --password 123456 \ --table class \ --hive-import
- 增量导入数据到hive中,mode=append
给MySQL添加几条数据
bin/sqoop import \ --connect jdbc:mysql://datanode1:3306/student \ --username root \ --password 123456 \ --table class \ --num-mappers 1 \ --fields-terminated-by "\t" \ --target-dir /user/hive/warehouse/class \ --check-column id \ --incremental append \ --last-value 3
注意:append不能与—hive-等参数同时使用(Append mode for hive imports is not yet supported. Please remove the
parameter —append-mode)
使用lastmodified方式导入数据要指定增量数据是要—append(追加)还是要—merge-key(合并):last-value指定的值是会包含于增量导入的数据中
| 序号 | 参数 | 说明 |
|---|---|---|
| 1 | —append | 将数据追加到HDFS中已经存在的DataSet中,如果使用该参数,sqoop会把数据先导入到临时文件目录,再合并。 |
| 2 | —as-avrodatafile | 将数据导入到一个Avro数据文件中 |
| 3 | —as-sequencefile | 将数据导入到一个sequence文件中 |
| 4 | —as-textfile | 将数据导入到一个普通文本文件中 |
| 5 | —boundary-query (statement) | 边界查询,导入的数据为该参数的值(一条sql语句)所执行的结果区间内的数据。 |
| 6 | —columns | 指定要导入的字段 |
| 7 | —direct | 直接导入模式,使用的是关系数据库自带的导入导出工具,以便加快导入导出过程。 |
| 8 | —direct-split-size | 在使用上面direct直接导入的基础上,对导入的流按字节分块,即达到该阈值就产生一个新的文件 |
| 9 | —inline-lob-limit | 设定大对象数据类型的最大值 |
| 10 | —m或–num-mappers | 启动N个map来并行导入数据,默认4个。 |
| 11 | —query或—e (statement) | 将查询结果的数据导入,使用时必须伴随参—target-dir,—hive-table,如果查询中有where条件,则条件后必须加上$CONDITIONS关键字 |
| 12 | —split-by <column-name) | 按照某一列来切分表的工作单元,不能与—autoreset-to-one-mapper连用(请参考官方文档) |
| 13 | —table (table-name) | 关系数据库的表名 |
| 14 | —target-dir (dir) | 指定HDFS路径 |
| 15 | —warehouse-dir (dir) | 与14参数不能同时使用,导入数据到HDFS时指定的目录 |
| 16 | —where | 从关系数据库导入数据时的查询条件 |
| 17 | —z或—compress | 允许压缩 |
| 18 | —compression-codec | 指定hadoop压缩编码类,默认为gzip(Use Hadoop codec default gzip) |
| 19 | —null-string (null-string) | string类型的列如果null,替换为指定字符串 |
| 20 | —null-non-string (null-string) | 非string类型的列如果null,替换为指定字符串 |
| 21 | —check-column (col) | 作为增量导入判断的列名 |
| 22 | —incremental (mode) | mode:append或lastmodified |
| 23 | —last-value (value) | 指定某一个值,用于标记增量导入的位置 |
export
从HDFS(包括Hive和HBase)中把数据导出到关系型数据库中。
bin/sqoop export \ --connect jdbc:mysql://datanode1:3306/student \ --username root \ --password 123456 \ --table class2mysql \ --export-dir /student \ --input-fields-terminated-by "\t" \ --num-mappers 1
| 序号 | 参数 | 说明 |
|---|---|---|
| 1 | —direct | 利用数据库自带的导入导出工具,以便于提高效率 |
| 2 | —export-dir |
存放数据的HDFS的源目录 |
| 3 | -m或—num-mappers | 启动N个map来并行导入数据,默认4个 |
| 4 | —table | 指定导出到哪个RDBMS中的表 |
| 5 | —update-key | 对某一列的字段进行更新操作 |
| 6 | —update-mode | updateonly allowinsert(默认) |
| 7 | —input-null-string | 请参考import该类似参数说明 |
| 8 | —input-null-non-string | 请参考import该类似参数说明 |
| 9 | —staging-table | 创建一张临时表,用于存放所有事务的结果,然后将所有事务结果一次性导入到目标表中,防止错误。 |
| 10 | —clear-staging-table | 如果第9个参数非空,则可以在导出操作执行前,清空临时事务结果表 |
codegen
将关系型数据库中的表映射为一个Java类,在该类中有各列对应的各个字段。
bin/sqoop codegen \ --connect jdbc:mysql://datanode1:3306/student \ --username root \ --password 123456 \ --table class \ --bindir /opt/moudle \ --class-name class_mysql \ --fields-terminated-by "\t"
| 序号 | 参数 | 说明 |
|---|---|---|
| 1 | —bindir |
指定生成的Java文件、编译成的class文件及将生成文件打包为jar的文件输出路径 |
| 2 | —class-name | 设定生成的Java文件指定的名称 |
| 3 | —outdir |
生成Java文件存放的路径 |
| 4 | —package-name | 包名,如com.z,就会生成com和z两级目录 |
| 5 | —input-null-non-string | 在生成的Java文件中,可以将null字符串或者不存在的字符串设置为想要设定的值(例如空字符串) |
| 6 | —input-null-string | 将null字符串替换成想要替换的值(一般与5同时使用) |
| 7 | —map-column-java | 数据库字段在生成的Java文件中会映射成各种属性,且默认的数据类型与数据库类型保持对应关系。该参数可以改变默认类型,例如:—map-column-java id=long, name=String |
| 8 | —null-non-string | 在生成Java文件时,可以将不存在或者null的字符串设置为其他值 |
| 9 | —null-string | 在生成Java文件时,将null字符串设置为其他值(一般与8同时使用) |
| 10 | —table | 对应关系数据库中的表名,生成的Java文件中的各个属性与该表的各个字段一一对应 |
eval
可以快速的使用SQL语句对关系型数据库进行操作,经常用于在import数据之前,了解一下SQL语句是否正确,数据是否正常,并可以将结果显示在控制台。
bin/sqoop eval \ --connect jdbc:mysql://datanode1:3306/student \ --username root \ --password 123456 \ --query "SELECT * FROM class"
| 序号 | 参数 | 说明 |
|---|---|---|
| 1 | —query或—e | 后跟查询的SQL语句 |
import-all-tables
可以将RDBMS中的所有表导入到HDFS中,每一个表都对应一个HDFS目录
bin/sqoop import-all-tables \ --connect jdbc:mysql://datanode1:3306/student \ --username root \ --password 123456 \ --warehouse-dir /all_tables
序号 参数 1 —as-avrodatafile 2 —as-sequencefile 3 —as-textfile 4 —direct 5 —direct-split-size 6 —inline-lob-limit 7 —m或—num-mappers 8 —warehouse-dir 9 -z或—compress 10 —compression-codec
job
用来生成一个sqoop任务,生成后不会立即执行,需要手动执行。
$ bin/sqoop job \ --create myjob -- import-all-tables \ --connect jdbc:mysql://datanode1:3306/student \ --username root \ --password 123456 $ bin/sqoop job --list $ bin/sqoop job --exec myjob
list-databases
bin/sqoop list-databases \ --connect jdbc:mysql://datanode1:3306/ \ --username root \ --password 123456
list-tables
bin/sqoop list-tables \ --connect jdbc:mysql://datanode1:3306/student \ --username root \ --password 123456
merge
bin/sqoop codegen \ --connect jdbc:mysql://datanode1/student \ --username root \ --password 123456 \ --table class \ --bindir /home/hadoop \ --class-name student \ --fields-terminated-by "\t"
bin/sqoop merge \ --new-data /test/new \ --onto /test/old \ --target-dir /test/merged \ --jar-file /home/hadoop/student.jar \ --class-name student \ --merge-key id
| 序号 | 参数 | 说明 |
|---|---|---|
| 1 | —new-data (path) | HDFS 待合并的数据目录,合并后在新的数据集中保留 |
| 2 | —onto(path) | HDFS合并后,重复的部分在新的数据集中被覆盖 |
| 3 | —merge-key (col) | 合并键,一般是主键ID |
| 4 | —jar-file (file) | 合并时引入的jar包,该jar包是通过Codegen工具生成的jar包 |
| 5 | —class-name (class) | 对应的表名或对象名,该class类是包含在jar包中的 |
| 6 | —target-dir (path) | 合并后的数据在HDFS里存放的目录 |
metastore
记录了Sqoop job的元数据信息,如果不启动该服务,那么默认job元数据的存储目录为~/.sqoop,可在sqoop-site.xml中修改。
bin/sqoop metastore
参考资料
https://student-lp.iteye.com/blog/2157983
| 序号 | 参数 | 说明 |
|---|---|---|
| 1 | —shutdown | 关闭metastore |

