
MongoDB聚合
MongoDB 除了基本的查询,还有强大的聚合工具:
distinct
distinct用来找出给定键的所有不同的值。使用时必须指定集合和键。
元数据
> db.user.find()
{ "_id" : ObjectId("5c0df99fbc6d47cbcdb55fd0"), "name" : "jack", "age" : 19 }
{ "_id" : ObjectId("5c0df9abbc6d47cbcdb55fd1"), "name" : "rose", "age" : 20 }
{ "_id" : ObjectId("5c0df9b0bc6d47cbcdb55fd2"), "name" : "jack", "age" : 18 }
{ "_id" : ObjectId("5c0df9c3bc6d47cbcdb55fd3"), "name" : "tony", "age" : 21 }
{ "_id" : ObjectId("5c0df9cdbc6d47cbcdb55fd4"), "name" : "adam", "age" : 18 }
{ "_id" : ObjectId("5c0e0824bc6d47cbcdb55fd5"), "age" : 2, "name" : 1 }
{ "_id" : ObjectId("5c0e0826bc6d47cbcdb55fd6"), "age" : 2, "name" : 2 }
{ "_id" : ObjectId("5c0e0828bc6d47cbcdb55fd7"), "age" : 2, "name" : 3 }
{ "_id" : ObjectId("5c0f3476478f8e67a82bc840"), "name" : "jack", "age" : 19 }
> db.runCommand({distinct:"user","key":"age"})
{ "values" : [ 2, 18, 19, 20, 21 ], "ok" : 1 }
group
group做的聚合稍复杂一些。先选定分组所依据的键,而后MongoDB就会将集合依据选定键值的不同分成若干组。然后可以通过聚合每一组内的文档,产生一个结果文档。
元数据
{"day":"2010/10/03","time":"10/3/2010 03:57:01 GMT-400","price":4.23}
{"day":"2010/10/04","time":"10/4/2010 11:45:01 GMT-400","price":4.27}
{"day":"2010/10/05","time":"10/5/2010 05:43:01 GMT-400","price":4.11}
{"day":"2010/10/06","time":"10/6/2010 06:56:01 GMT-400","price":4.01}
group查询语句
> db.runCommand({
... "group": {
... "ns": "stocks",
... "key": "day",
... "inital": {
... "time": 0
... },
... "$reduce": function(doc, prev) {
... if (doc.time > prev.time) {
... prev.price = doc.price;
... prev.time = doc.time;
... }
... }
... }
... })
{
"ok" : 0,
"errmsg" : "initial has to be an object",
"code" : 2,
"codeName" : "BadValue"
}
“ns”: “stocks” 指定进行分组的集合
“key”: “day”, 指定文档分组一句的键,这里就是”day”,所有”day”值相同的w文档被划分到了一组,
“inital”: { “time”: 0 } 每一组reduce函数调用的初始时间,会作为初始文档,传递给后续过程,每一个组员的所有成员都是用这个累加器,所以改变会保留住.
“$reduce”: function(doc, prev)每个文档都对应一次这个调用。系统会传递两个参数:当前文档和累加器文档(本组当前的结果)。本例中,想让reduce函数比较当前文档的时间和累加器的时间。如果当前文档的时间更近,则将累加器的日期和价格替换成当前文档的值。别忘了,每一组都有一个独立的累加器,所以不必担心不同的日斯使用同一个累加器。
如果只要最近30天的股价可以使添加condition
> db.runCommand({
... "group": {
... "ns": "stocks",
... "key": "day",
... "inital": {
... "time": 0
... },
... "$reduce": function(doc, prev) {
... if (doc.time > prev.time) {
... prev.price = doc.price;
... prev.time = doc.time;
... }
... },
... "condition":{"day":{$gt:"2010/09/30"}}
...
... }
... })
这里每组的”price”都是显式设置的,”time”先由初始化器设置,然后也是主动更新。”day”是默认被加进去的,因为分组依据的键默认被加入到每个”retval”内嵌文档中。要是不想返回这个键,可以用完成器把累加器文档变成任意形态,甚
至变换成非文档(例如数字或字符串)。
aggregate
aggregate 提供的是类似SQL(结构化查询语言)的聚合操作,例如每个操作符都可以找到对应的sql关键字
| MySQL | MongoDB |
|---|---|
| WHERE | $match |
| GROUP BY | $group |
| HAVING | $match |
| SELECT | $project |
| ORDERY BY | $sort |
| LIMIT | $limit |
| SUM | $sum |
| COUNT() | sum |
| SortByCount | |
| join | $lookup |
sql语句 与对应的聚合函数

MapReduce
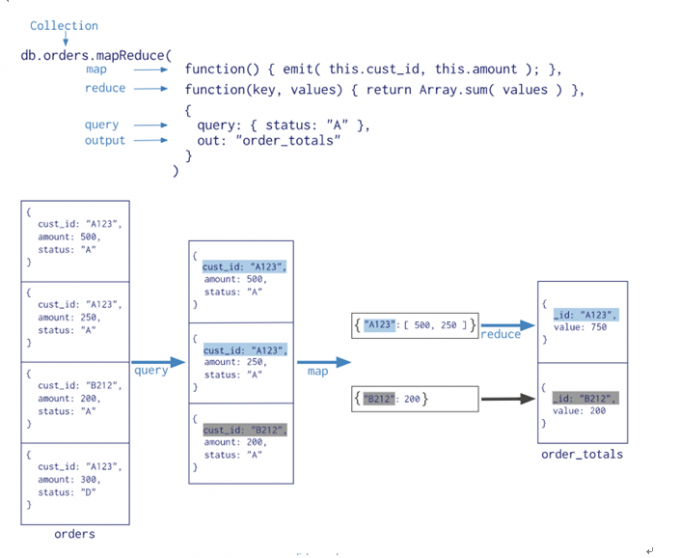
Python 脚本导入数据
from pymongo import MongoClient
from random import randint
import datetime
client = MongoClient()
db = client.get_database('taobao')
order = db.order_info
status = ['A', 'B', 'C']
cust_id = ['A123', 'B123', 'C123']
price = [500, 250, 200, 300]
sku = ['mmm', 'nnn']
for i in range(1, 100):
items = []
items_count = randint(2, 6)
for n in range(items_count):
# sku 库存量 qty 数量
items.append({"sku": sku[randint(0, 1)], "qty": randint(1, 10), "price": randint(0, 5)})
new = {
"status": status[randint(0, 2)],
"cust_id": cust_id[randint(0, 2)],
"price": price[randint(0, 3)],
"ord_date": datetime.datetime.utcnow(),
"items": items
}
print(new)
order.insert_one(new)
print(i)
print(order.estimated_document_count())
数据格式
{
"_id" : ObjectId("5c0f1bc52a3cde1260163371"),
"status" : "B",
"cust_id" : "C123",
"price" : 300,
"ord_date" : ISODate("2018-12-11T02:07:01.598Z"),
"items" : [
{
"sku" : "nnn",
"qty" : 2,
"price" : 5
},
{
"sku" : "mmm",
"qty" : 1,
"price" : 4
}
]
}
查询每个cust_id 的所有price总和MapReduce
> #定义 map函数
> var mapFunction1 = function() {
... emit(this.cust_id, this.price);
... };
> #定义reduce函数
> var reduceFunction1 = function(keyCustId, valuesPrices) {
... return Array.sum(valuesPrices);
... };
> #执行mapreduce,输出到当前db的map_reduce_example集合中
> db.order_info.mapReduce(
... mapFunction1,
... reduceFunction1,
... { out: "map_reduce_example" }
... )
{
"result" : "map_reduce_example",
"timeMillis" : 284,
"counts" : {
"input" : 99,
"emit" : 99,
"reduce" : 3,
"output" : 3
},
"ok" : 1
}
查看结果
> db.map_reduce_example.find()
{ "_id" : "A123", "value" : 8350 }
{ "_id" : "B123", "value" : 9150 }
{ "_id" : "C123", "value" : 12800 }
>
聚合管道操作命令
> db.order_info.aggregate({ $group: { _id: "$cust_id", total: { $sum: "$price" }}})
{ "_id" : "A123", "total" : 8350 }
{ "_id" : "B123", "total" : 9150 }
{ "_id" : "C123", "total" : 12800 }
>
计算所有items 的平均库存 Mapreduce
# map函数
> var mapFunction2 = function() {
... for (var idx = 0; idx < this.items.length; idx++) {
... var key = this.items[idx].sku;
... var value = {
... count: 1,
... qty: this.items[idx].qty
... };
... emit(key, value);
... }
... };
>
#reduce函数
> var reduceFunction2 = function(keySKU, countObjVals) {
... reducedVal = { count: 0, qty: 0 };
...
... for (var idx = 0; idx < countObjVals.length; idx++) {
... reducedVal.count += countObjVals[idx].count;
... reducedVal.qty += countObjVals[idx].qty;
... }
...
... return reducedVal;
... };
#finalize函数
> var finalizeFunction2 = function (key, reducedVal) {
...
... reducedVal.avg = reducedVal.qty/reducedVal.count;
...
... return reducedVal;
...
... };
>
# 执行mapreduce
> db.order_info.mapReduce( mapFunction2,
... reduceFunction2,
... {
... out: { merge: "map_reduce_example" },
... finalize: finalizeFunction2
... }
... )
{
"result" : "map_reduce_example",
"timeMillis" : 121,
"counts" : {
"input" : 99,
"emit" : 406,
"reduce" : 2,
"output" : 5
},
"ok" : 1
}
查看
> db.map_reduce_example.find()
{ "_id" : "A123", "value" : 8350 }
{ "_id" : "B123", "value" : 9150 }
{ "_id" : "C123", "value" : 12800 }
{ "_id" : "mmm", "value" : { "count" : 211, "qty" : 1135, "avg" : 5.37914691943128 } }
{ "_id" : "nnn", "value" : { "count" : 195, "qty" : 1016, "avg" : 5.21025641025641 } }
聚合管道操作命令实现,计算其所有items 的平均库存,要求输出结果包含count和qty;
> db.order_info.aggregate({$unwind:"$items"},{$group:{_id:"$items.sku",count:{$sum:1},totallyqty:{"$sum":"$items.qty"},avgsku:{"$avg":"$items.qty"}}})
{ "_id" : "nnn", "count" : 195, "totallyqty" : 1016, "avgsku" : 5.21025641025641 }
{ "_id" : "mmm", "count" : 211, "totallyqty" : 1135, "avgsku" : 5.37914691943128 }
用聚合管道操作命令实现:根据cust_id,仓库编号进行分组,计算其所有items 的平均库存;
> db.order_info.aggregate({$unwind:"$items"},{$group:{_id:{cust_id:'$cust_id',skunn:'$items.sku'},avgsku:{"$avg":"$items.qty"}}})
{ "_id" : { "cust_id" : "B123", "skunn" : "mmm" }, "avgsku" : 5.283783783783784 }
{ "_id" : { "cust_id" : "B123", "skunn" : "nnn" }, "avgsku" : 5.121212121212121 }
{ "_id" : { "cust_id" : "C123", "skunn" : "nnn" }, "avgsku" : 5.216216216216216 }
{ "_id" : { "cust_id" : "A123", "skunn" : "nnn" }, "avgsku" : 5.3090909090909095 }
{ "_id" : { "cust_id" : "A123", "skunn" : "mmm" }, "avgsku" : 5.508196721311475 }
{ "_id" : { "cust_id" : "C123", "skunn" : "mmm" }, "avgsku" : 5.368421052631579 }

