Elasticsearch分布式机制探究
Elasticsearch是一套分布式的系统,分布式是为了应对大数据量隐藏了复杂的分布式机制
分片机制
shard = hash(routing) % number_of_primary_shards
Routing值可以是一个任意的字符串,默认情况下,它的值为存数数据对应文档 _id 值,也可以是用户自定义的值。Routing这个字符串通过一个hash的函数处理,并返回一个数值,然后再除以索引中主分片的数目,所得的余数作为主分片的编号,取值一般在0到number_of_primary_shards - 1的这个范围中。通过这种方法计算出该数据是存储到哪个分片中。
正是这种路由机制,导致了主分片的个数为什么在索引建立之后不能修改。对已有索引主分片数目的修改直接会导致路由规则出现严重问题,部分数据将无法被检索。
集群发现机制
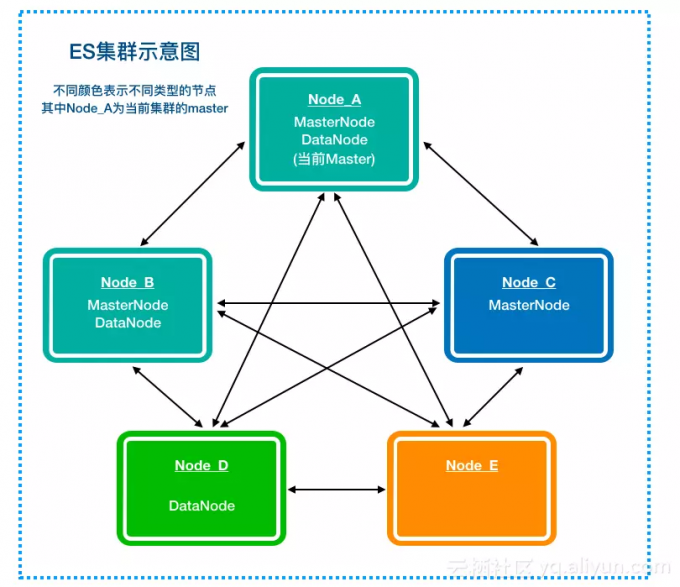
discovery.zen.ping_timeout (默认3秒)配置允许对选举的时间进行调整,用来处理缓慢或拥挤的网络。当一个节点请求加入主节点,它会发送请求信息到主节点,请求的超时时间配置为discovery.zen.join timeout,这个时间比较长,是discovery.zen.ping timeout 时间的20倍。当主节点发生问题的时候,现有的节点又会通过ping来重新选举一个新的主节点。当 discovery.zen.masterelection.filter_client 设置为 true 的时候,在选举主节点的时候从客户端节点(node.client为true,或者node.data和node.master同时为(false)的ping 操作将被忽略,该参数默认为 true当 discovery.zen.master election.filter data 为true时,在选举主节点的时候从数据节点(node.data为ture, node.mas..ter同时为false)的ping操作将被忽略,默认为falsec主节点配置为true的节点一直都有选举的资格当节点node.master设置为false或者node.client设置为true的时候,它们将自动排除成为主节点的可能性。
discovery.zen.minimum master nodes设置需要加入一个新当选的主节点的最小节点数B,或者接收它作为主节点的最小节点数::如果不满足这一要求,主节点会下台,重新开始新的选举。
shard负载均衡
“Shard” 这个词英文的意思是”碎片”,而作为数据库相关的技术用语,称之为”分片”,是水平扩展(Scale Out,亦或横向扩展、向外扩展)的解决方案,其主要目的是为突破单节点数据库服务器的 I/O 能力限制,解决数据库扩展性问题。
shard副本
- index包含多个shard
- 每个shard都是一个最小工作单元,承载部分数据,lucene实例,完整的建立索引和处理请求的能力
- 增减节点时,shard会自动在nodes中负载均衡
- primary shard和replica shard,每个document肯定只存在于某一个primary shard以及其对应的replica shard中,不可能存在于多个primary shard
- replica shard是primary shard的副本,负责容错,以及承担读请求负载
- primary shard的数量在创建索引的时候就固定了,replica shard的数量可以随时修改
- primary shard的默认数量是5,replica默认是1,默认有10个shard,5个primary shard,5个replica shard primary shard不能和自己的replica shard放在同一个节点上(否则节点宕机,primary shard和副本都丢失,起不到容错的作用),但是可以和其他primary shard的replica shard放在同一个节点上
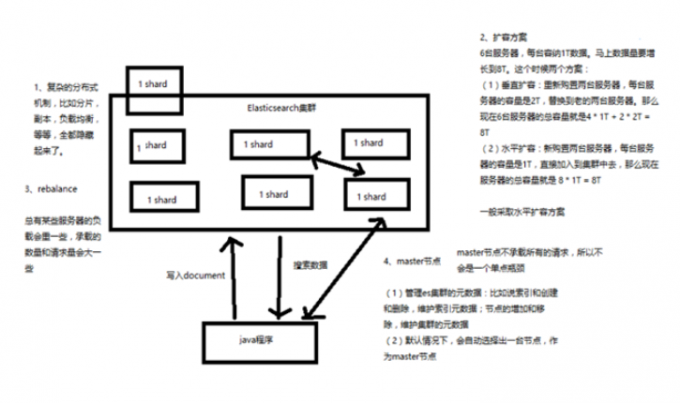
集群扩容