


机器学习之决策树
决策树理论
参考:https://www.cnblogs.com/fm-yangon/p/14072896.html
决策树的sklearn实现
决策树模型(分类与回归参数方法属性一致):
from sklearn.tree import DecisionTreeClassifier from sklearn.tree import DecisionTreeRegressor DecisionTreeClassifier(criterion='gini' , splitter='best' , max_features=None , max_depth=None , max_leaf_nodes=None , min_samples_split=2 , min_impurity_split=1e-07 , min_samples_leaf=1 , class_weight=None)
参数:
criterion:特征选择的标准,可以选择gini或者entropy,前者代表基尼系数,后者代表信息增益。默认为基尼系数,cart,ID3或者C4.5改用entropy。
splitter:特征划分点选择标准。可以选择best或者random ,前者代表每次按照特征选择标准选择最优划分,后者表示在部分划分点中随机地找局部最优划分点。默认为best,当数据量较大时,为了加快训练速度,可以选择使用random。
max_features:划分时考虑的最大特征数。可以选择None 、log2 、sqrt 、auto,默认为None ,表示划分时选择所有特征。选择log2表示划分是最多考虑log2N个特征数,选择sqrt或者auto,表示划分时最多考虑sqrt(N)个特征。
max_depth:决策树最大深度,默认不输入,表示决策树在建立子树时不会限制子树的深度,常用取值在10-100之间。
max_leaf_nodes:最大叶子节点数,默认为None,不限制最大的叶子节点数量。特征数量较多时,限制叶子节点数防止过拟合。
min_samples_split:内部节点划分所需要的最小样本数,如果某节点的样本数小于设置的min_samples_split时,则不会继续分叉子树。默认是2,一般设置在30以上。
min_impurity_split:节点划分的最小不纯度。该值用来限制决策树的分叉,如果某节点的不纯度(信息增益,信息增益比,gini系数,标准差)小于这个阈值,则该节点不再分叉成子节点,直接作为叶子节点。
min_samples_leaf:叶子节点最少样本数。如果某样本中叶子节点的数目小于设置的min_samples_leaf的阈值,则会和兄弟节点一起被剪枝,默认为1。
class_weight:所属类型的权重。该参数仅存在分类树中,默认为None。当训练集数据类别分布非常不均衡时,建议使用该参数来防止模型过于偏向样本多的类别。
属性:
feature_importances_:给出各个特征的重要程度,值越大表示对应的特征越重要
tree_:底层的树对象
方法:
fit(X_train ,y_train):进行模型训练
score(X_test ,y_test):返回模型在测试集上的预测准确率
predict(X):用训练好的模型来预测待预测数据集X,返回数据为预测集对应的预测结果yˆ
predict_proba(X):返回一个数组,数组元素依次为预测集X属于各个类别的概率
predict_log_proba(X):返回一个数组,数组的元素依次是预测集X属于各个类别的对数概率,回归树没有该方法
决策树案例之鸢尾花:
from sklearn import datasets import numpy as np import matplotlib.pyplot as plt from matplotlib.colors import ListedColormap from sklearn.tree import DecisionTreeClassifier iris = datasets.load_iris() X = iris.data[:,:2] y = iris.target cmap_light = ListedColormap(['#FFAAAA' ,'#AAFFAA' ,'#AAAAFF']) cmap_bold = ListedColormap(['#FF0000' ,'#00FF00' ,'#0000FF']) dc_clf = DecisionTreeClassifier() dc_clf.fit(X ,y) x_min ,x_max = X[:,0].min() - 1 ,X[:,0].max() + 1 y_min ,y_max = X[:,1].min() - 1 ,X[:,1].max() + 1 xx ,yy = np.meshgrid(np.arange(x_min ,x_max , 0.02) ,np.arange(y_min ,y_max , 0.02)) z = dc_clf.predict(np.c_[xx.ravel() ,yy.ravel()]) z = z.reshape(xx.shape) plt.figure() plt.pcolormesh(xx ,yy ,z ,cmap = cmap_light) plt.scatter(X[:,0] ,X[:,1] ,c= y ,cmap = cmap_bold) plt.xlim(xx.min() ,xx.max()) plt.ylim(yy.min() ,yy.max()) plt.title("decision tree default parameter") plt.show()
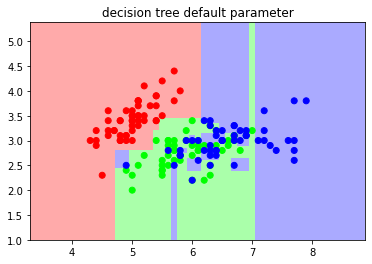
结果比较准确
from sklearn import datasets import numpy as np import matplotlib.pyplot as plt from matplotlib.colors import ListedColormap from sklearn.tree import DecisionTreeClassifier from sklearn.model_selection import train_test_split from sklearn.model_selection import cross_val_score from sklearn.metrics import classification_report ,confusion_matrix iris = datasets.load_iris() X = iris.data y = iris.target X_train ,X_test ,y_train ,y_test = train_test_split(X ,y ,train_size = 0.7) dc_clf = DecisionTreeClassifier() dc_clf.fit(X_train ,y_train) y_pred = dc_clf.predict(X_test) def cm_plot(y, yp): cm = confusion_matrix(y, yp) #混淆矩阵 plt.matshow(cm ,cmap=plt.cm.Greens) #画混淆矩阵图,配色风格使用cm.Greens,更多风格请参考官网。 plt.colorbar() #颜色标签 for x in range(len(cm)): #数据标签 for y in range(len(cm)): plt.annotate(cm[x,y], xy=(x, y), horizontalalignment='center', verticalalignment='center') plt.ylabel('True label') #坐标轴标签 plt.xlabel('Predicted label') #坐标轴标签 plt.title('confusion_matrix') return plt print('交叉验证结果:') print(cross_val_score(dc_clf ,X_test ,y_test ,cv = 5)) print("查准率、查全率、F1分值:") print(classification_report(y_test ,y_pred ,target_names=None)) print("混淆矩阵:") cm_plot(y_test,y_pred)
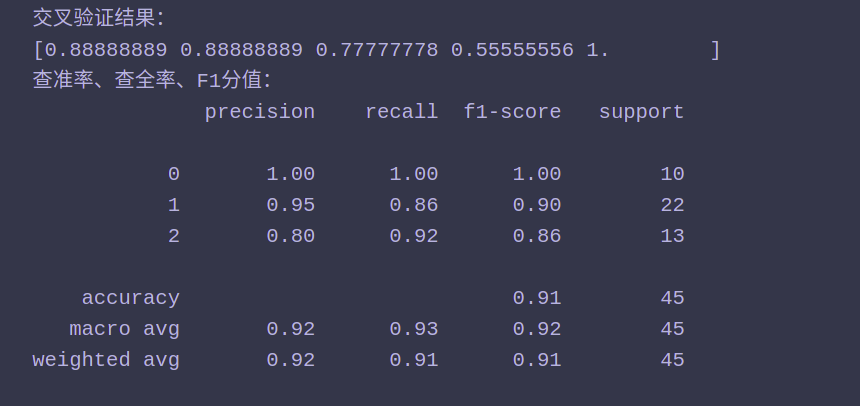
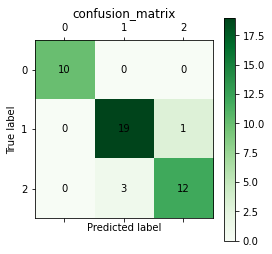
决策树小结:
1、优点:
1、简单且易于理解。对决策树模型进行可视化后可以很清楚地看到每一颗树分支的参数,而且很容易理解背后的逻辑。
2、可以同时处理类别型和数值型数据。
3、可以处理多分类和非线性分类问题。
4、模型训练好之后进行预测时运行速度很快。决策树模型一经训练之后,后面预测过程只是对各个待预测样本从树的根节点往下找到一条符合特征约束的路径,因此预测速度很快。
5、方便做集成。树模型的精度很高,虽然存在过拟合的风险,但是可以通过集成来改善,随机森林和GBDT等集成模型都是使用决策树作为基学习器。
2、缺点:
1、决策树模型对噪声比较敏感。在训练集噪声比较大时得到的模型容易过拟合(可以通过剪枝和集成来改善)。
2、在处理特征关联性较强的数据时表现的不好。

