


模型之信息熵
信息熵的公式
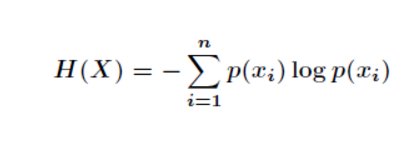
其中代表随机事件X为
的概率。
演示:
| 性别(x) | 考试成绩(y) |
|---|---|
| 男 | 优 |
| 女 | 优 |
| 男 | 差 |
| 女 | 优 |
| 男 | 优 |
X的信息熵计算为:
p(男) = 3/5 = 0.6
p(女) = 2/5 = 0.4
根据上面的计算公式可得:
列X的信息熵 为: H(x)= - ( 0.6 * log2(0.6) + 0.4 * log2(0.4)) = 0.97.......
Y的信息熵计算为:
p(优) = 4/5 = 0.8
p(差) = 1/5 = 0.2
列X的信息熵 为: H(x)= - ( 0.8 * log2(0.8) + 0.2 * log2(0.2)) = 0.72.......
由信息熵引出的条件熵:

条件熵的概念类似于条件概率,就是再给定X的情况的条件下,y的信息熵。
给定性别为男,成绩为优的条件熵:
H(y | x = 男)= 3/5 * -(2/3 * log2(2/3) + 1/3 * log2(1/3)) = 0.55...
H(y | x = 女)= 2/5 * -( 1 * log2(1) + 1 * log2(1)) = 0.0...
H(y | x)= H(y | x = 男)+ H(y | x = 女) = 0.55... + 0.0... = 0.55
信息量
信息量是对信息的度量,就跟时间的度量是秒一样,当我们考虑一个离散的随机变量x的时候,当我们观察到的这个变量的一个具体值的时候,我们接收到了多少信息呢?
多少信息用信息量来衡量,我们接受到的信息量跟具体发生的事件有关。
信息的大小跟随机事件的概率有关。越小概率的事情发生了产生的信息量越大,如湖南产生的地震了;越大概率的事情发生了产生的信息量越小,如太阳从东边升起来了(肯定发生的事情,没什么信息量)。
对信息熵的理解
信息熵还可以作为一个系统复杂程度的度量,如果系统越复杂,出现不同情况的种类越多,那么他的信息熵是比较大的。
如果一个系统越简单,出现情况种类很少(极端情况为1种情况,那么对应概率为1,那么对应的信息熵为0),此时的信息熵较小。
信息增益( ID3算法 )
定义: 以某特征划分数据集前后的熵的差值
在熵的理解那部分提到了,熵可以表示样本集合的不确定性,熵越大,样本的不确定性就越大。因此可以使用划分前后集合熵的差值来衡量使用当前特征对于样本集合D划分效果的好坏。
信息增益比( C4.5算法 )
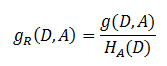
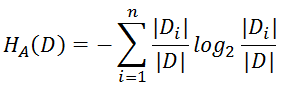
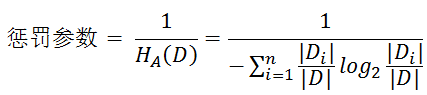
基尼指数( CART算法 ---分类树)
定义:基尼指数(基尼不纯度):表示在样本集合中一个随机选中的样本被分错的概率。
注意: Gini指数越小表示集合中被选中的样本被分错的概率越小,也就是说集合的纯度越高,反之,集合越不纯。即 基尼指数(基尼不纯度)= 样本被选中的概率 * 样本被分错的概率
书中公式: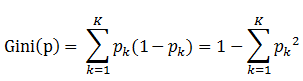
说明:
1. pk表示选中的样本属于k类别的概率,则这个样本被分错的概率是(1-pk)
2. 样本集合中有K个类别,一个随机选中的样本可以属于这k个类别中的任意一个,因而对类别就加和
3. 当为二分类是,Gini(P) = 2p(1-p)
样本集合D的Gini指数 : 假设集合中有K个类别,则:
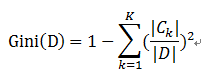
基于特征A划分样本集合D之后的基尼指数:
需要说明的是CART是个二叉树,也就是当使用某个特征划分样本集合只有两个集合:1. 等于给定的特征值 的样本集合D1 , 2 不等于给定的特征值 的样本集合D2
实际上是对拥有多个取值的特征的二值处理。
举个例子:
假设现在有特征 “学历”,此特征有三个特征取值: “本科”,“硕士”, “博士”,
当使用“学历”这个特征对样本集合D进行划分时,划分值分别有三个,因而有三种划分的可能集合,划分后的子集如下
- 划分点: “本科”,划分后的子集合 : {本科},{硕士,博士}
- 划分点: “硕士”,划分后的子集合 : {硕士},{本科,博士}
- 划分点: “硕士”,划分后的子集合 : {博士},{本科,硕士}
对于上述的每一种划分,都可以计算出基于 划分特征= 某个特征值 将样本集合D划分为两个子集的纯度:
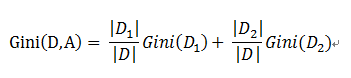
因而对于一个具有多个取值(超过2个)的特征,需要计算以每一个取值作为划分点,对样本D划分之后子集的纯度Gini(D,Ai),(其中Ai 表示特征A的可能取值)
然后从所有的可能划分的Gini(D,Ai)中找出Gini指数最小的划分,这个划分的划分点,便是使用特征A对样本集合D进行划分的最佳划分点。
转载自:https://www.cnblogs.com/muzixi/p/6566803.html

