dataframe列联表等操作
pd.melt参数:
rame : DataFrame id_vars:tuple, list,或ndarray,可选。用作标识符变量的列。 value_vars:tuple, list, 或 ndarray,可选。要unpivot的列。如果未指定,则使用未设置为id_vars的所有列。 var_name:标量用于‘variable’列的名称。如果为None,则使用 frame.columns.name或‘variable’。 value_name:标量,默认为'value',用于‘value’列的名称。 col_level:int 或 string,可选,如果列是MultiIndex,则使用此级别进行融合。
pd.melt(df ,in_vars = [] ,value_vars = [] ,value_name = '')
pd.crosstab参数:
pd.crosstab(index, # 分组依据 columns, # 列 values=None, # 聚合计算的值 rownames=None, # 列名称 colnames=None, # 行名称 aggfunc=None, # 聚合函数 margins=False, # 总计行/列 dropna=True, # 是否删除缺失值 normalize=False # )
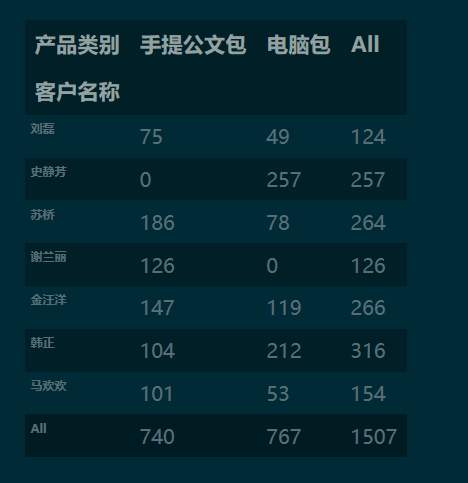
pd.crosstab(index=df['客户名称'], columns=df['产品类别'], values=df['销量'], aggfunc='sum', margins=True ).round(0).fillna(0).astype('int') #分类汇总 df.groupby(['客户名称', '产品类别']).apply(sum)
效果:
pd.pivot_table参数:
pivot_table(data, values=None, index=None, columns=None,aggfunc='mean', fill_value=None, margins=False, dropna=True, margins_name='All')
# aggfunc也可以使用dict类型,如果dict中的内容与values不匹配时,以dict中为准。
pd.pivot_table(df,index=[u'对手',u'胜负'],columns=[u'主客场'],values=[u'得分',u'助攻',u'篮板'],aggfunc={u'得分':np.mean, u'助攻':[min, max, np.mean]},fill_value=0)
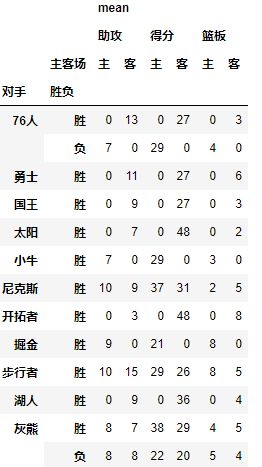
table=pd.pivot_table(df,index=[u'对手',u'胜负'],columns=[u'主客场'],values=[u'得分',u'助攻',u'篮板'],aggfunc=[np.mean],fill_value=0)
效果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号