HybridSN+2D SENet
1、在HybridSN模块中添加注意力机制:
class_num = 16
rate = 16 # SENet论文中建议rate=sqrt(256)=16
class HybridSN(nn.Module):
def __init__(self):
super(HybridSN, self).__init__()
self.conv1 = nn.Conv3d(1, 8, kernel_size=(7, 3, 3), stride=1, padding=0)
self.conv2 = nn.Conv3d(8, 16, kernel_size=(5, 3, 3), stride=1, padding=0)
self.conv3 = nn.Conv3d(16, 32, kernel_size=(3, 3, 3), stride=1, padding=0)
inputX = self.get2Dinput()
inputConv4 = inputX.shape[1] * inputX.shape[2]
self.conv4 = nn.Conv2d(inputConv4, 64, kernel_size=(3, 3), stride=1, padding=0)
#加入atention机制
self.fc_41 = nn.Conv2d(64, 64//rate, kernel_size=1)
self.fc_42 = nn.Conv2d(64//rate, 64, kernel_size=1)
num = inputX.shape[3]-2 #二维卷积后(64, 17, 17)-->num = 17
inputFc1 = 64 * num * num
self.fc1 = nn.Linear(inputFc1, 256) # 64 * 17 * 17 = 18496
self.fc2 = nn.Linear(256, 128)
self.fc3 = nn.Linear(128, class_num)
self.dropout = nn.Dropout(0.4)
def get2Dinput(self):
with torch.no_grad():
x = torch.zeros((1, 1, self.L, self.S, self.S))
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
return x
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.relu(self.conv2(x))
x = F.relu(self.conv3(x))
x = x.view(x.shape[0], -1, x.shape[3], x.shape[4])
x = F.relu(self.conv4(x))
# Squeeze 操作:global average pooling
w = F.avg_pool2d(x, x.size(2))
# Excitation 操作: fc(压缩到16分之一)--Relu--fc(激到之前维度)--Sigmoid(保证输出为 0 至 1 之间)
w = F.relu(self.fc_41(w))
w = F.sigmoid(self.fc_42(w))
x = x * w
x = x.view(-1, x.shape[1] * x.shape[2] * x.shape[3])
x = F.relu(self.fc1(x))
x = self.dropout(x)
x = F.relu(self.fc2(x))
x = self.dropout(x)
x = self.fc3(x)
return x
在HybridSN网络的基础上得到提高,比起之前的96.75%,得到最高98.51%的准确率
2、视频学习
-
很喜欢听报告的这种形式,李夏前辈对语义分割中的自注意力机制的系统介绍,给自己在该方向的入门指了一条道路——可以从这些优秀的论文开始学习。程明明教授的两篇报告清楚明晰,听了收获颇深。对于Res2net和strip pooling的结构设计,感觉很精巧,却又不容易想到。李夏前辈的报告内容很多,但自己的积淀太少,第一遍听睡着了而第二遍仍很懵,所以很大程度上听不懂,便决定把大佬所提的论文看一下整理一下,目前仅整理两篇,后续补充。
-
北京大学李夏前辈的报告《语义分割中的自注意力机制和低秩重重建》
-
A²-Nets Double Attention Networks
这是我看的第一篇论文,由于对语义分割中的注意力这块刚学习,很多不太懂,于是将这篇论文大概翻译了一下,整理到GitHub:https://sditch.github.io/2020/08/14/A%C2%B2-Nets-Double-Attention-Networks/
-
Github:https://sditch.github.io/2020/08/15/Non-local-Neural-Networks/
-
-
南开大学程明明教授的报告《图像语义分割前沿进展》
-
报告主要从卷积、池化角度降低计算量和参数量
-
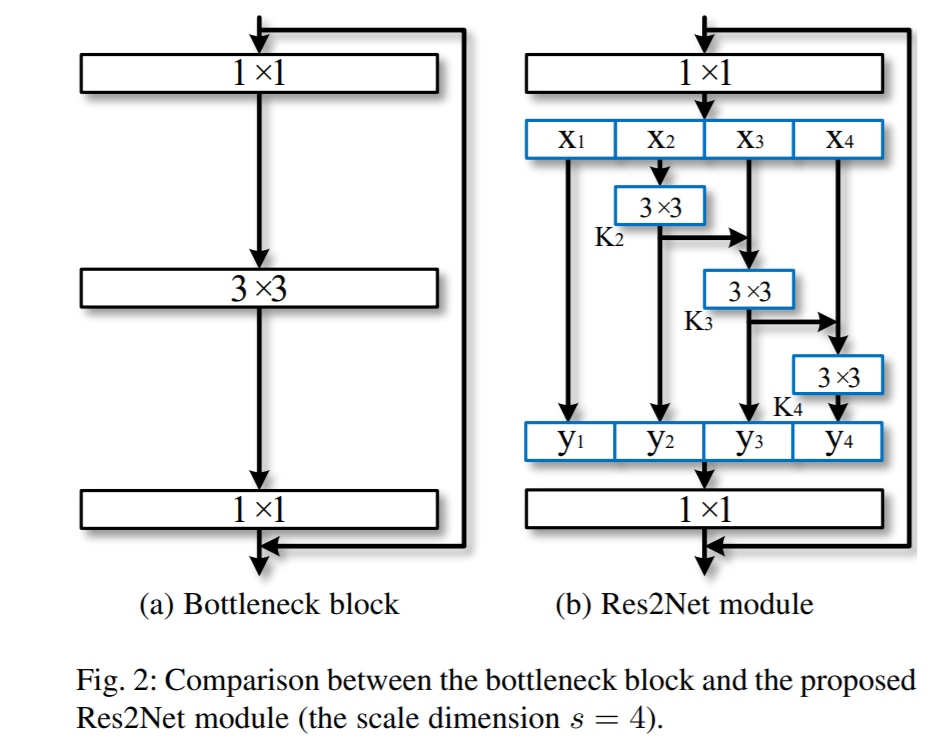
Res2Net:A New Multi-scale Backbone Architecture
res2net(层内和层间的多尺度):将原来resnet模块3×3的卷积换成多个小滤波器,每个小滤波器通道数为原来卷积的一部分(如图b的x1、x2、x3、x4),最终网络计算量降低得多。同时随着小滤波器的叠加,其深度加强,感受野也能得到增强。网络性能得到提升,而且res2net具有很好的复用性。
![image-20200812204033670]()
-
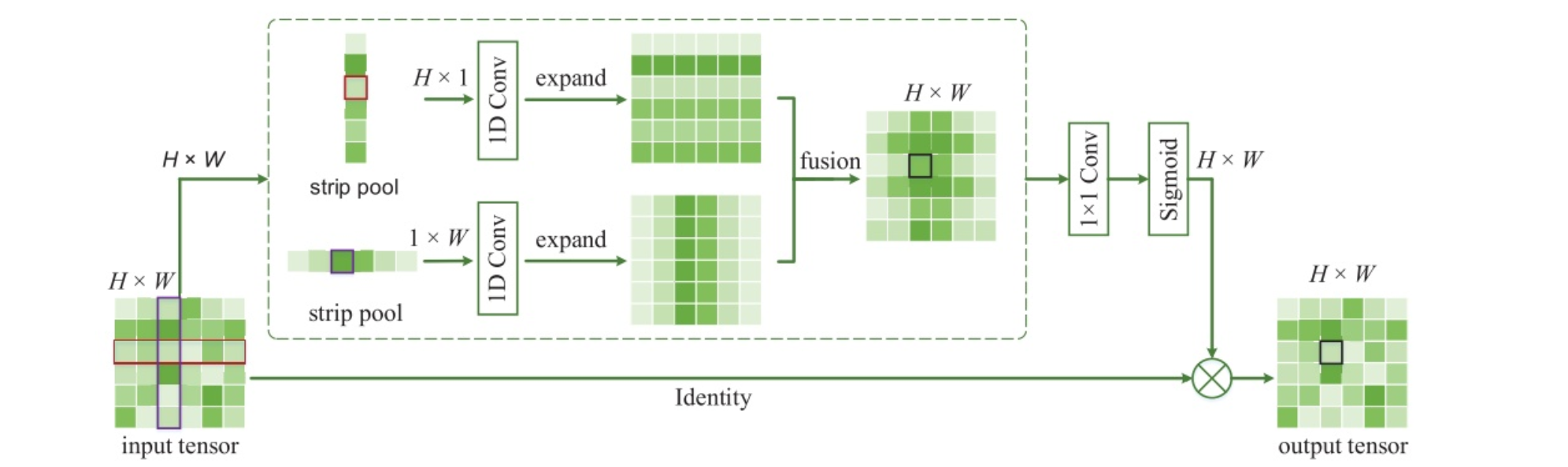
Strip Pooling:Rethinking Spatial Pooling for Scene Parsing
strip pooling:带状池化,沿着一个空间维度捕获孤立区域的远程关系,沿其他空间维度捕获本地上下文信息并防止无关区域干扰标签预测
![image-20200812202230921.png]()
-
陈昊:BlendMask: Top-Down Meets Bottom-Up for Instance Segmentation
COCO数据集不容易过拟合,但是数据集本身标注不太准
Top-Down:丢失细节性信息、背景计算浪费
语义分割 vs 实例分割
语义分割结果更精细,实例分割更完整

 浙公网安备 33010602011771号
浙公网安备 33010602011771号