


Linux运维工程师面试题整理
1. Nginx 反向代理,负载均衡,动静分离,工作原理及优化
nginx配置反向代理。
vim Nginx.conf
Server模块中配置
Listen 80
Server_name ip;
在server段里面的location加上proxy_pass http://ip:端口;
Nginx配置完成后重启一下nginx。
配置代理多个网站及服务
配置多个反向代理实现方式,是通过不同的端口代理访问。这里复制一个server段,将两个server段nginx的端口更改,使用nginx的不同端口访问。
Server1配置:
listen *:端口;>>>>多个反向代理使用不同端口
Server_name ip;>>>>注释掉,使用端口访问
在location 里面的proxy_pass 配置Tomcat1,ip 加Tomcat端口
Server2配置:
listen *:端口;>>>>多个反向代理使用不同端口
Server_name ip;>>>>注释掉,使用端口访问
在location 里面的proxy_pass 配置Tomcat2,ip 加Tomcat端口
负载均衡:
使用两台服务器,分别安装nginx 和通Tomcat,端口号分别为8080 和8081,
通过在nginx的upstream参数中添加应用服务器IP后添加指定参数,在location块中配置动态组名称,在访问网页的时候就会通过upstream中的配置项将指令分发给服务器。
动静分离:
将静态资源部署在Nginx上,当一个请求来的时候,如果是静态资源的请求,就直接到nginx配置的静态资源目录下面获取资源,如果是动态资源的请求,nginx利用反向代理的原理,把请求转发给后台应用去处理,从而实现动静分离。
工作原理:Nginx由内核和模块组成,其中,内核的设计非常微小和简洁,完成的工作也非常简单,仅仅通过查找配置文件将客户端请求映射到一个location block(location是Nginx配置中的一个指令,用于URL匹配),而在这个location中所配置的每个指令将会启动不同的模块去完成相·应的工作。
优化:3.网络IO事件模型优化4.隐藏软件名称和版本号5.防盗链优化6.禁止恶意域名解析7.禁止通过IP地址访问网站10.严格设置web站点目录的权限 11.HTTP请求方法优化
2. Mysql 主从复制,主从复制的原理,读写分离,读写分离的原理,mysql优化
主从复制:
主服务器:
修改mysql配置,(#开启二进制日志,server-id)
重启mysql,创建用于同步的用户账号
查看master状态,记录二进制文件名(mysql-bin.000003)和位置(73):
从服务器:
1.修改mysql配置
同样找到my.cnf配置文件,添加server-id
2.重启mysql,打开mysql会话,执行同步SQL语句
3.启动slave同步进程:
读写分离:
首先在主mysql上面建一个授权用户稍后给amoeba使用,1.通过安装amoeba,修改dbserver.xml配置文件,修改26行左右,指定mysql账户名称和密码,指定mysql主从的IP。2.修改amoeba.xml配置文件,修改amoeba代理的账号和密码,修改120左右的调用配置,然后实现读写分离。
mysql的读写分离的基本原理是:让master(主数据库)来响应事务性操作,让slave(从数据库)来响应select非事务性操作,然后再采用主从复制来把master上的事务性操作同步到slave数据库中。
mysql优化:
1.选择合适的存储弓擎: InnoDB
2.保证从内存中读取数据。将数据保存在内存中
3.定期优化重建数据库
4.降低磁盘写入操作
5.提高磁盘读写速度
6.充分使用索引
7.分析查询日志和慢查询日志
Mysqldump备份
mysqldump -h主机名 -P端口 -u用户名 -p密码 --database 数据库名 > 文件名.sql
3. Tomcat 配置文件有哪些,优化
Tomcat目录:conf bin logs webapps work lib temp
配置文件一般都在conf文件夹里,主要有server.xml,context.xml,tomcat_user.xml,web.xml四个常用配置文件,server主要是服务器设置的,例如端口设置,路径设置。context里设置tomcat数据源,用来连接数据库。tomcat_user主要是用户名和密码的设置。web是默认首页等等之类的设置。
bin/catalina.bat/sh,配置内存
tomcat优化:
句柄连接数,最大并发数,线程数,请求超时时间,禁止tomcat manager管理入口
关闭shutdown端口
4. Redis 作用,应用场景
作用:
主要用Redis实现缓存数据的存储,可以设置过期时间.对于一些高频读写、临时存储的数据特别适合.
应用场景:
缓存 分布式会话 分布式锁 最新列表 消息系统
5. Zookeeper 配置文件叫什么,作用是什么
conf下zoo_sample.cfg修改为Zoo_cfg
作用:分布式协调通知 加强集群稳定性 加强集群持续性 保证集群有序性 保证集群高效
注册中心
服务提供方:针对所提供的服务到注册中心发布。
服务消费方:到服务中心订阅所需的服务。
对于任何一方,不论服务提供方或者服务消费方都有可能同时兼具两种角色,即需要提供服务也需要消费服务。
6. Lvs 工作原理是什么,有哪些工作模式
→1.LVS调度器收到目标地址为VIP的请求包后,将MAC地址改成RS(真正的服务器)的MAC地址。并通过交换机(链路层)发给RS。
2.RS的链路层收到请求包后,往上传给IP层。IP层需要验证请求的目标IP地址,所以RS需要配置一个VIP的 loopbak device(策略文件)。这样RS的IP层收到报文后,会往上递交给传输层,之所以配置成loopbak device,是因为loopbak device 对外不可见,不会跟LVS的VIP冲突。
3.RS处理完成后,将应答包直接返回给客户端。
工作模式:
LVS-DR,LVS-NAT,LVS-FULLNAT,LVS-TUN
7. Keepalived 作用,怎么实现负载均衡
检查web服务器的状态,如果有一台web服务器/mysql服务器宕机或故障,keepalived将故障节点从系统中剔除,当故障恢复的时候自动加入服务器集群中,非常智能化,只需要手动修复坏的节点即可。
负载均衡步骤:
1、安装master组件和依赖包(keepalive+lvs)
2、备份keepalived配置文件
3、编辑keepalived配置文件
4、开启路由转发
5、重启keepalived服务并设置开机自启
主从同样步骤,修改keepalived.conf时state主从分别修改为master和backup。
在web1和web2服务器上安装nginx,并修改内核参数,然后添加虚拟主机IP。
8. Rabbitmq 作用,为什么使用(应用场景)
消息队列,用在分布式系统存储转发消息
应用场景:异步处理,应用解耦,流量削峰
9. Haproxy 参数优化 作用
长连接超时时间
客户端超时时间
守护进程模式
最大连接数
/etc/haproxy/haproxy.cfg
作用:高可用,负载均衡和用于TCP和基于http的应用程序代理
优点:
HAProxy支持数以万计的 并发连接。
同时可以保护你的web服务器不被暴露到网络上。
10. MongoDB 是什么数据库,优化参数有哪些
MongoDB是一个基于分布式文件存储的数据库。由C++语言编写
MongoDB优化:
1.cachesizeGB(缓存大小) 按配额的60%左右配置即可
2.oplogsizeMB (固定集合) 设置为可用disk空间的5%
3.启用Log Rotation日志切换 防止MongoDB的log文件无限增大,占用太多磁盘空间,使用Log Rotation并及时清理历史日志文件
4.stack size (连接内存优化) Stack设置小一点,比如说1024
5.MongoDB打开文件数优化 设置文件打开描述数量
11. Zabbix 作用是什么 可以监控什么,优化有什么,工作原理
Zabbix作用:监控网路主机
监控:CPU负荷 内存使用,磁盘使用,日志监视,端口监视,网络状态,
zabbix优化:
1.轮询器实例数量 2.不可达主机 3.HTTP 轮询器子进程实例个数 4.缓存大小5.历史缓存数据大小 5.trappers进程实例数量
工作原理:
Agent安装在被监控的主机上,Agent负责定期收集客户端本地各项数据,并发送至Zabbix Server端,Zabbix Server收到数据,将数据存储到数据库中,用户基于Zabbix WEB可以看到数据在前端展现图像。当Zabbix监控某个具体的项目,项目会设置一个触发器阈值,当被监控的指标超过该触发器设定的阈值,会进行一些必要的动作,动作包括:发送信息(邮件、微信、短信)、发送命令(SHELL 命令、Reboot、Restart、Install等)。
12. VMware
13. Apache 配置文件叫什么,优化有哪些
配置文件:/etc/httpd/conf/httpd.conf
1. 移除不用的模块。2将缓存放在独立的磁盘3.使用持久连接4.不要设置KeepAliveTimeout太高 5.提高写入缓冲器( Write Buffer)大小6.提高最大打开文件7.频繁访问的数据设置缓存。
14. NFS 作用
网络文件系统是应用层的一种应用服务,它主要应用于Linux和Linux系统、Linux和Unix系统之间的文件或目录的共享。对于用户而言可以通过 NFS方便的访问远地的文件系统,使之成为本地文件系统的一部分。采用NFS之后省去了登录的过程,方便了用户访问系统资源。
mount -t nfs -o ro ip:/共享目录 /本地目录
挂载失败:
1.防火墙受阻 2.nfs配置有问题,3.客户端和服务端是否是同一个网段
15. Ansible 配置,优化有什么,怎么实现的自动化
配置:
/etc/hosts文件中添加被管理服务器ip
Ansible性能调优
1、 Ansible SSH 关闭秘钥检测
2、 OpenSSH连接优化
3、SSH pipelining(管道输送)加速Ansible (默认关闭)
4、 Ansible Facts缓存优化
自动化:在管理服务器上创建文件,通过命令行将指令传输到各个被管理服务器上
16.rsync的作用及优点?
Rsync可以再不同的主机 之间镜像同步整个目录树,支持增量备份,保持链接属性和权限,采用优化的同步算法,传输前执行压缩,适合异地备份,镜像服务等应用,是一种常用的文件备份工具及数据同步工具。
17.Linux系统优化有什么
⑴登录系统:不使用root登录,通过sudo授权管理,使用普通用户登录。
⑶时间同步:定时自动更新服务器时间。
⑷配置yum更新源,从国内更新下载安装rpm包。
⑸关闭selinux及iptables(iptables工作场景如有wan ip,一般要打开,高并发除外)
⑻精简开机启动服务(crond、sshd、network、rsyslog)
⑼Linux内核参数优化/etc/sysctl.conf,执行sysct -p生效。
⑾锁定关键系统文件(chattr +i /etc/passwd /etc/shadow /etc/group /etc/gshadow /etc/inittab 处理以上内容后,把chatter改名,就更安全了。)
18.常见的centos和redhat故障怎么处理?
1.忘记linux root密码
这个问题出现的几率是很高的,不过,在linux下解决这个问题也很简单,只需重启linux系统,然后引导进入linux的单用户模式(init 1),由于单用户模式是不需要输入登录密码的,因此,可以直接登录系统,修改root密码即可解决问题。
2.grub.conf丢失和解决办法
//删除/bootr/grub/gub.conf文件
//删除后重新启动查看出现的问题
可以看出系统是无法从硬盘启动了
(2)解决办法
一种是在无Live-CD光盘时解决,具体操作如下:
系统重启后,进入grub模式
首先查看/boot分区所在的位置,系统内核,第三行是临时系统镜像文件所在的位置,然后boot重启。
启动起来后进入/boot/grub目录下编辑grub.conf文件:
编辑grub.conf的内容如下:
配置启动菜单项,等待时间,菜单名称,root启动文件的位置,启动时的系统内核位置及名称,内核镜像的位置及名称
编辑完后这错误也就彻底的解决了。
19.redis主从复制模式下,主挂了怎么办?redis提供了哨兵模式(高可用)
何谓哨兵模式?就是通过哨兵节点进行自主监控主从节点以及其他哨兵节点,发现主节点故障时自主进行故障转移。
20.使用redis有哪些好处
1.速度快 2.支持丰富数据类型 (list set hash string)3.支持事务(原子性) 4.丰富的特性
21.MySQL里有2000w数据,Redis中只存20w的数据,如何保证Redis中的数据都是热点数据(redis有哪些数据淘汰策略???)
redis 内存数据集大小上升到一定大小的时候,就会施行数据淘汰策略(回收策略)。淘汰策略:
最近最少使用的数据淘汰 将要过期的数据淘汰 已过期的数据中任意选择数据淘汰 任意选择数据淘汰 禁止驱逐数据
22.看你简历上写了你项目里面用到了Redis,你们为啥用Redis?
因为传统的关系型数据库如Mysql已经不能适用所有的场景了,比如秒杀的库存扣减,APP首页的访问流量高峰等等,都很容易把数据库打崩,所以引入了缓存中间件,目前市面上比较常用的缓存中间件有Redis 和 Memcached 不过综合考虑了他们的优缺点,最后选择了Redis。
应用场景不一样:Redis出来作为NoSQL数据库使用外,还能用做消息队列、数据堆栈和数据缓存等;Memcached适合于缓存SQL语句、数据集、用户临时性数据、延迟查询数据和session等。
灾难恢复–memcache挂掉后,数据不可恢复; redis数据丢失后可以通过aof恢复
存储数据安全–memcache挂掉后,数据没了;redis可以定期保存到磁盘(持久化)
23.Redis有哪些数据结构呀?
字符串String、字典Hash、列表List、集合Set、有序集合SortedSet
24.那你使用过Redis分布式锁么,它是什么回事?
先拿setnx来争抢锁,抢到之后,再用expire(一颗四百额)给锁加一个过期时间防止锁忘记了释放。
25. 这时候对方会告诉你说你回答得不错,然后接着问如果在setnx之后执行expire之前进程意外crash或者要重启维护了,那会怎么样?
唉,是喔,这个锁就永远得不到释放了,我记得set指令有非常复杂的参数,这个应该是可以同时把setnx和expire合成一条指令来用的!
26.RDB的原理是什么?
你给出两个词汇就可以了,fork和cow。fork是指redis通过创建子进程来进行RDB操作,cow指的是copy on write,子进程创建后,父子进程共享数据段,父进程继续提供读写服务,写入的页面数据会逐渐和子进程分离开来。
27.mysql原理
关系型数据库使数据库的数据之间存在关联关系,可以通过一条数据关联出一些列数据,方便了数据的检索和查询,提高开发人员的查询效率,但是会拖累数据库,因此关系型数据库不支持太高的并发
28.Redis主从怎么配置?
1.编辑配置文件Redis.conf
redis默认只允许本机连接,所以需要找到“bind 127.0.0.1”并将这行注释掉:
redis在3.0版本以后增加了保护模式 ,如需保护,改成yes
将默认的“daemonize no”改为yes,设置redis以守护线程方式启动:
分别配置pid,log,db文件的保存地址
启动redis
设置开机启动
2.Redis主从配置
从节点配置
(1) 修改redis从配置文件,添加一行配置“slaveof 192.168.0.101 6379”映射到主节点
(2) 重启从节点的redis
3.查看并验证主从配置
(1)主节点与从节点均登录redis并执行info命令查看主从配置结果
找到“# Replication”模块,可以看到主节点提示存在一个从节点,并且会列出从节点的相关信息,同样,可以在从节点看到自己的主节点是哪个,列出主节点的相关信息
(2)验证主从
登录主节点redis,set age 24,到从节点直接get age,看到可以get到我们在主节点设置的值24,说明主从配置成功
29.mysql数据库用的是主从读写分离,主库写,从库读,假如从库无法读取了、或者从库读取特别慢,你会如何解决?
笔者回答:以解决问题为前提条件,先添加从库数量,临时把问题给解决,然后抓取slow log ,分析sql语句,该优化就优化处理。慢要不就是硬件跟不上,需要升级;要不就是软件需要调试优化,等问题解决在细化。
30.Mysql忘记密码该如何操作呢?
1、修改my.ini配置文件,添加跳过密码验证代码;
代码:skip-grant-tables,使用为跳过密码验证。代码添加位置,建议放在[mysqld]之后;
2、进入命令行,使用mysql -u root登录;
3、使用use mysql;选择数据库;
4、执行update代码;
update mysql.user set authentication_string=password('root_password') where user='root';
5.执行完成后,再输入以下代码:
flush privileges;
刷新MySQL的系统权限相关表,否则会出现拒绝访问等错误;
再记得删除my.ini中配置的skip-grant-tables(跳过密码验证)代码;
5、重启服务后,再使用新密码登录即可;
31.Nginx宕机怎么处理?
Nginx上传大文件150M以上上传不了。是因为带宽的问题,因为大家都在上传,小文件可以传是因为在优化的65秒可以上传内容这么大。把上传的优化断开时间修改到1800秒。过了几天服务器直接宕机了。后来发现后来服务器的进程满级了。因为上传的小的文件也是占用1800秒。所以很多人上传不了文件,因为进程都被占用了。解决。。要进行逻辑业务分离,上传的专门做上传服务器,不再走网站形式进行上传。
32.出现keepalived脑裂,是什么原因?
可能是端口受阻。网络线路抖动,导致通电信号受阻。。导致健康信号包发送不了也接收不了。所以双方都起了VIP,客户访问时出现两个VIP,所以出现这个问题。
33.怀疑一块网卡有问题的时候,如何检测?
将其安装在一台能正常上网的机器上,看其指示灯是否闪烁,正常接入状态下指示灯应为红色或者绿色,然后用ping命令检测是否能ping通网络上的主机,若通则正常,若网卡驱动安装无误而ping命令不通,则可以断定网卡坏掉。
34.遇到网络或病毒攻击,该怎么办,说说思路,然后是怎么找到病毒源头,怎么清除病毒?这是公司常遇到的网络问题
提前预防
装杀毒软件,下升级补丁,修补漏洞,定时更新杀毒软件,定时进行全盘扫描。
2.临阵磨枪0
万一中毒,第一件要干的事就是下网,防止病毒继续蔓延。然后立即从新启动机器,再开机时狂按F8,选择进入安全模式,进入后任何程序都不要打开,在任务管理器上把平时看不到的进程关闭,然后关闭任务管理器,打开杀毒软件,进行全盘扫描。查出的病毒先用杀毒软件删,删不了的话,用别的机器下一个unlocker(是个程序,需安装,极小,才191Kb),记下病毒路径,找到病毒文件,右键选择unlocker,手动删除!
35.数据库满了,怎么缩容,腾出更多的磁盘空间,也是公司常遇到的问题;
将30天以前的很少用到日志进行定期的清除。
36.nginx和Apache的区别在哪儿?
Nginx是轻量级的web服务比Apache占用更小的内存以及资源
Nginx并发量比Apache高三倍以上
可作为负载均衡,反向代理器
37.LVS的工作原理是什么?有哪些算法?
LVS群集,也叫LVS虚拟服务器,针对Linux内核开发的一个负载均衡项目。LVS是基于IP地址和内容请求分发的高效负载均衡解决方案,现在属于linux内核的一部分,默认编译为ip_vs模块。
38.Linux系统用户数
/etc/security/limits.conf
# 当前用户最大登录数
# max number of logins for this user
* soft maxlogins 100
* hard maxlogins 100
# 系统最大登录用户数
# max number of logins on the system
* soft maxsyslogins 100
* hard maxsyslogins 100
39.MySql将查询结果插入到另外一张表
Insert into 目标表 select * from 来源表 ;
40. Redis数据量很大,怎么做
一、增加内存
redis存储于内存中,数据太多,占用太多内存,那么增加内存就是最直接的方法,但是这个方法一般不采用,因为内存满了就加内存,满了就加,那代价也太大,相当于用钱解决问题,不首先考虑,一般所有方面都做到最优化,才考虑此方法
二、搭建Redis集群
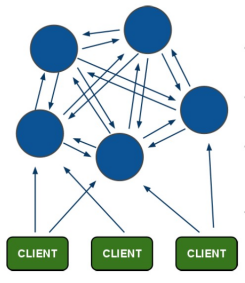
(1)所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽.
(2)节点的fail(失败)是通过集群中超过半数的节点检测失效时才生效.
(3)客户端与redis节点直连,不需要中间proxy层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可
(4)redis-cluster把所有的物理节点映射到[0-16383]slot上,cluster 负责维护node<->slot<->value
Redis集群中内置了 16384 个哈希槽,当需要在 Redis 集群中放置一个 key-value 时,redis 先对key 使用 crc16 算法算出一个结果,然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,redis 会根据节点数量大致均等的将哈希槽映射到不同的节点
41.磁盘RAID级别有几种,分别是哪几种?你了解或者使用过哪几种,请写出它们的大概描述和区别。
RAID级别有以下几种:NRAID,JBOD,RAID0,RAID1,RAID0+1,RAID3,RAID5等。目前经常使用的是RAID0,RAID1,RAID3,RAID5和RAID(0+1)。它们的区别大致如下:
RAID 0 存取速度最快 但没有容错 2块盘
RAID 1 完全容错但成本比较高,可用于数据备份,磁盘利用率为50% 2块盘
RAID 3 写入性能最好 但没有多任务功能 3块盘n+1,1为校验盘
RAID 5 具备多任务及容错功能,安全性高,随机和连续读写性能低 3块盘
RAID 0+1 读写速度快、完全容错但成本高,用的比较多 4块盘 利用率50%
42.192.168.1.0/23包含多少IP
43.工作中遇到的故障点
44.mysql主从复制不同步的原因及如何处理?
→两种方法:
方法一:该方法适用于主从库数据相差不大,或者要求数据可以不完全统一的情况,数据要求不严格的情况
首先进入master库,查看进程是否sleep太多,还有状态是否正常,然后在从slave上查看,IO线程和SQL线程是否正常。如果不正常,则停止slave,然后set globai sql_slave_skip_counter=1(跳过一个事物);再重新启动slave,再用show slave status \G;查看,如果IO线程和SQL线程均为yes,那么主从同步状态恢复正常。
方法二:该方法适用于主从库数据相差较大,或者要求数据完全统一的情况
1.先进入主库,进行锁表,防止数据写入 。使用命令: flush tables with read lock;
2..进行数据备份 。把数据备份到mysql.bak.sql文件 ,使用命令:mysqldump -uroot -p -hlocalhost > mysql.bak.sql
3.查看master 状态 。使用命令:show master status;
4.把mysql备份文件传到从库机器,进行数据恢复 。使用命令:scp mysql.bak.sql root@192.168.128.101:/tmp/
5.停止从库的状态 。使用命令:stop slave;
6.然后到从库执行mysql命令,导入数据备份。使用命令:source /tmp/mysql.bak.sql
7.设置从库同步,注意该处的同步点,就是主库show master status信息里的| File| Position两项
change master to master_host = '192.168.128.100', master_user = 'rsync', master_port=3306, master_password='', master_log_file = 'mysqld-bin.000001', master_log_pos=3260;
8.重新开启从同步 。使用命令:start slave;
9.查看同步状态 。使用命令:show slave status\G ;如果IO线程和SQL线程均为yes时,则主从可同步。
45.当文件系统受到破坏时,如何检查和修复系统?
参考答案:
成功修复文件系统的前提是要有两个以上的主文件系统,并保证在修复之前首先卸载将被修复的文件系统。
使用命令fsck对受到破坏的文件系统进行修复。fsck检查文件系统分为5步,每一步检查系统不同部分的连接特性并对上一步进行验证和修改。在执行 fsck命令时,检查首先从超级块开始,然后是分配的磁盘块、路径名、目录的连接性、链接数目以及空闲块链表、i-node。
46.访问网页时报错都是什么意思?
401:用户验证失败。402:密码认证失败。403:访问被拒绝。404:文件位置发生了转变或删除。500:用户权限的问题导致。501: 不具有请求功能。502:错误网关。503:正在维护或者暂停。504:网关超时的现象 505:http的版本是不受支持。
47.简述贵公司的PV、UV、IP,流量等资源大小?
日访问量100万,小时点击量4-5万,最高QPS 1000左右,UV量是20-30万,IP量为55万
48.zabbix常见报错问题处理
①报错:
centos6.5装上agent之后,却发现启动不了,日志里面报错如下:
zabbix_agentd [20529]: cannot create Semaphore: [28] No space left on device(设备上没有剩余空间)
zabbix_agentd [20529]: unable to create mutex for log file
修改/etc/sysctl.conf
添加如下行:
kernel.sem (信号量)= 500(信号集容纳最大量) 64000(所有信号量) 64(单个集) 256(信号集最大)
修改之后,执行sysctl -p使其生效。
重新启动zabbix-agent即可
49.mysql查看版本号?Liunx ,Ubuntu查看版本号?
登录时候可以查看或者使用命令select version() ; cat /etc/redhat-release cat /etc/issue
50.Linux中开放某个端口
开放某个端口
开放8080端口:firewall-cmd --zone(区)=public(公众)--add-port=8080/tcp --permanent(永久)
重启防火墙:firewall-cmd --reload
51.Linux操作系统启动顺序
开机自检,加载BIOS→Grub引导→加载内核Kernel→init系统初始化脚本(/etc/rc.d/rc.sysinit)→加载启动的服务
52.Linux中/var/log/下日志详解
系统日志一般都存在/var/log下
常用的系统日志如下:
核心启动日志:/var/log/dmesg
系统报错日志:/var/log/messages(几乎所有的开机系统发生的错误)
邮件系统日志:/var/log/maillog
FTP系统日志:/var/log/xferlog
53.mysql中一些重要的参数
最大连接数,响应的连接数,索引缓冲区的大小,等待行动的秒数,表高速缓存的大小,允许的同时客户的数量,为所有线程打开表的数量,服务器在关闭它之前在一个连接上等待行动的秒数
54.Linux怎么批量杀死进程
ps -ef | grep firefox | grep -v grep | cut -c 9-15 | xargs kill -s 9
说明:
grep firefox的输出结果是,所有含有关键字“firefox”的进程。
grep -v grep是在列出的进程中去除含有关键字“grep”的进程。
cut -c 9-15是截取输入行的第9个字符到第15个字符,而这正好是进程号PID。
xargs kill -s 9中的xargs命令是用来把前面命令的输出结果(PID)作为“kill -s 9”命令的参数,并执行该命令。“kill -s 9”会强行杀掉指定进程。
55.查看僵尸进程:ps aux | grep Z
杀死僵尸进程:kill -9 7811 还会产生新的进程,用以下命令进行杀死进程
解决办法:
ps -ef | grep defunct(查出不再使用的进程,死的)
$3 是这些僵尸进程的父进程 PID ( PPID ),杀之!
ps -ef | grep defunct | awk '{print $3}' | xargs -i kill {}
56.vim中有那三种模式
命令,输入,编辑模式
57.关系型数据库和非关系性数据库的区别?
数据存储方式不同,扩展方式不同,对事物的支持不同
关系型数据库最典型的数据结构是表,由二维表及其之间的联系所组成的一个数据组织。
非关系型数据库严格上不是一种数据库,应该是一种数据结构化存储方法的集合,可以是文档或者键值对等。
58.nginx里面添加虚拟主机
添加一个server{},每个server里面的配置对应一个虚拟主机vhost
在 location下的fastsgi_pass 后面跟 虚拟主机ip+端口。
59.查看资源有哪些?
iostat监控系统设备的IO负载 top系统实时情况 ifconfig查看网络 uptime查看系统负载 free内存情况
59.Linux系统用户数
/etc/security/limits.conf
# 当前用户最大登录数
# max number of logins for this user
* soft maxlogins 100
* hard maxlogins 100
# 系统最大登录用户数
# max number of logins on the system
* soft maxsyslogins 100
* hard maxsyslogins 100
60.MySQL5.6和mysql5.7的区别是什么?
mysql5.7是5.6的新版本,新增了新的优化器,原生JSON支持,多源复制,还优化了整体的性能、GIS空间扩展、innodb.
61.jdk1.7和1.8的区别?
并发工具增强 Networking增强 Security 增强
62.有没有遇到过ddos 攻击,攻击的原理是什么,当前最容易消耗的是什么资源?
即分布式拒绝服务攻击,是指攻击者通过网络远程控制大量僵尸主机向一个或多个目标发送大量攻击请求,耗尽攻击目标服务器的系统资源,导致其无法响应正常的服务请求,利用的是TCP/IP三次握手 sync实现攻击... 最容易消耗目标服务器的网络带宽
63.服务器怎么做的安全加固?
1.禁用或删除无用账号2.检查特殊账号 3.限制用户su 4.禁止root用户直接登录
5.关闭不必要的服务 6.记录所有用户的登录和操作日志 7.设置登录超时 8.ssh服务安全
64.现在给你三百台服务器,你怎么对他们进行管理?
管理3百台服务器的方式:
1)设定跳板机,使用统一账号登录,便于安全与登录的考量。
2)使用salt、ansiable、puppet进行系统的统一调度与配置的统一管理。
3)建立简单的服务器的系统、配置、应用的cmdb信息管理。便于查阅每台服务器上的各种信息记录。
65.LVS、Nginx、HAproxy有什么区别?工作中你怎么选择?
LVS: 是基于四层的转发
HAproxy: 是基于四层和七层的转发,是专业的代理服务器
Nginx: 是WEB服务器,缓存服务器,又是反向代理服务器,可以做七层的转发
区别: LVS由于是基于四层的转发所以只能做端口的转发
而基于URL的、基于目录的这种转发LVS就做不了
工作选择:
HAproxy和Nginx由于可以做七层的转发,所以URL和目录的转发都可以做
在很大并发量的时候我们就要选择LVS,像中小型公司的话并发量没那么大
选择HAproxy或者Nginx足已,由于HAproxy由是专业的代理服务器
配置简单,所以中小型企业推荐使用HAproxy
66.讲一下Keepalived的工作原理?
在一个虚拟路由器中,只有作为MASTER的VRRP路由器会一直发送VRRP通告信息,
BACKUP不会抢占MASTER,除非它的优先级更高。当MASTER不可用时(BACKUP收不到通告信息)
多台BACKUP中优先级最高的这台会被抢占为MASTER。这种抢占是非常快速的(<1s),以保证服务的连续性
由于安全性考虑,VRRP包使用了加密协议进行加密。BACKUP不会发送通告信息,只会接收通告信息
67.讲述一下Tomcat8005、8009、8080三个端口的含义?
8005==》监听的关闭端口
8080==》正常的http协议
8009==》接受其他服务器转发过来的请求.
68.什么叫CDN?
- 即内容分发网络
- 其目的是通过在现有的Internet中增加一层新的网络架构,将网站的内容发布到
最接近用户的网络边缘,使用户可就近取得所需的内容,提高用户访问网站的速度
69.什么叫网站灰度发布?
灰度发布是指在黑与白之间,能够平滑过渡的一种发布方式
AB test就是一种灰度发布方式,让一部用户继续用A,一部分用户开始用B
如果用户对B没有什么反对意见,那么逐步扩大范围,把所有用户都迁移到B上面 来
灰度发布可以保证整体系统的稳定,在初始灰度的时候就可以发现、调整问题,以保证其影响度
70.简述DNS进行域名解析的过程?
用户要访问www.baidu.com,会先找本机的host文件,再找本地设置的DNS服务器,如果也没有的话,就去网络中找根服务器,根服务器反馈结果,说只能提供一级域名服务器.cn,就去找一级域名服务器,一级域名服务器说只能提供二级域名服务器.com.cn,就去找二级域名服务器,二级域服务器只能提供三级域名服务器.baidu.com.cn,就去找三级域名服务器,三级域名服务器正好有这个网站www.baidu.com,然后发给请求的服务器,保存一份之后,再发给客户端
71.RabbitMQ是什么东西?
RabbitMQ也就是消息队列中间件,消息中间件是在消息的传息过程中保存消息的容器
消息中间件再将消息从它的源中到它的目标中标时充当中间人的作用
队列的主要目的是提供路由并保证消息的传递;如果发送消息时接收者不可用
消息队列不会保留消息,直到可以成功地传递为止,当然,消息队列保存消息也是有期限地
72.简述TCP三次握手的过程?
答案:
在TCP/IP协议中,TCP协议提供可靠的连接服务,采用三次握手建立一个连接。
第一次握手:建立连接时,客户端发送syn包(syn=j)到服务器,并进入SYN_SEND(发送)状态,等待服务器确认。
第二次握手:服务器收到syn包,必须确认客户的SYN(ack=j+1),同时自己也发送一个SYN包(syn=k),即SYN+ACK包,此时服务器进入SYN_RECV(接收)状态。
第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=k+1),此包发送完毕,客户端和服务器进入ESTABLISHED(已建立连接)状态,完成三次握手。
完成三次握手,客户端与服务器开始传送数据
简版:首先A向B发SYN(同步请求),然后B回复SYN+ACK(同步请求应答),最后A回复ACK确认,这样TCP的一次连接(三次握手)的过程就建立了
73.常见的Linux版本有哪些?你最擅长哪一种?说明你擅长哪一块?
常见的Linux发行版有,Debian, Gentoo, Ubuntu, RedHat, CentOS, Fedora, Kali Linux, Suse等,最擅长CentOS,擅长部分命令使用,脚本编程,环境服务搭建与配置。
74.Linux的标准分区是什么?(内存32G,硬盘1T)
/boot 分200M,/分50G,swap 分16G,其余分到 /data 下。
75. 突然发现一台Linux系统只读,应该怎么处理,请写出详细步骤。
文件系统只读,可能是误操作,比如挂载的时候加了ro的挂载选项。也可能是文件系统损坏,这时候可以使用fsck -y 分区 来尝试修复一下,但在修复之前最好是把重要数据做一个备份以防万一。如果修复失败,那说明是磁盘损坏,这就需要更换磁盘了。
76.请用iptables写一条规则(同时允许443,80,1723,22,3306,11211,25,110,dns,ntp协议,并写出默认允许或者拒绝端口的作用)
iptables -I INPUT -p tcp -m multiport --dport 443,80,1723,22,3306,11211,25,110,53,123 -j ACCEPT
iptables默认是允许所有端口开放的,如果想只放行指定某些端口,那就需要配置一下默认规则了。比如本例中,我们写完放行的端口规则后还需要写一条默认拒绝的规则iptables -P INPUT DROP 这样除了上面那规则中提到的端口可以访问外,其他端口都是拒绝的。
77.网站HTTPS证书认证需要那几个文件?分别是什么?什么作用?
HTTPS证书需要有两个文件,一个是crt,一个是key。crt文件就是公钥文件,用来加密的。而key文件是私钥文件,是用来解密的。
78. 构建简单网站架构模型
设备:13台服务器,要求:有负载均衡和数据库主从
答案:
架构:Keepavlied + lvs + nginx/php + NFS + mysql + redis
keepalived+lvs 使用2台
Nginx+php-fpm使用5台
NFS 使用1台
Mysql双主,并使用keepalived构建高可用 使用2台
Redis 使用1台,用来存session
备份机器使用1台
监控机器使用1台
79.Apache有几种工作模式,分别介绍下其特点,并说明什么情况下采用不同的工作模式?
Web服务器Apache目前一共有三种稳定的MPM(Multi-Processing Module,多进程处理模块)模式。它们分别是prefork,worker和event,它们同时也代表这Apache的演变和发展。
1、Prefork MPM
Prefork MPM实现了一个非线程的、预派生的web服务器。
2、Worker MPM
和prefork模式相比,worker使用了多进程和多线程的混合模式,worker模式也同样会先预派生一些子进程,然后每个子进程创建一些线程,同时包括一个监听线程,每个请求过来会被分配到一个线程来服务。
3、Event MPM
这是Apache最新的工作模式,它和worker模式很像,不同的是在于它解决了keep-alive长连接的时候占用线程资源被浪费的问题
80.写一条192.168.10.0网段从网关192.168.9.1出去的路由
答:route add -net 192.168.10.0/24 gw 192.168.9.1
81.写一条放行80端口的防火墙规则。
答:iptables -I INPUT -p tcp --dport 80 -j ACCEPT
82. 你公司监控(如zabbix)系统监控了哪些项目。
答:监控了CPU使用率、内存剩余、磁盘使用空间、网卡流量、web服务、mysql主从、访问日志等
83. linux引导加载的先后顺序是BIOS kernel GRUB MBR RAID?
答案:BIOS -> RAID -> MBR -> GRUB -> kernel
84.进程间通信方式主要有哪几种方式?
答案:1管道 2命名管道 3信号 4消息队列 5共享内存 6信号量 7套接字
85.简要说明你对内核空间和用户空间的理解?
答案:这个问题有点偏开发,大家不明白没有关系,了解一下即可。操作系统和驱动程序运行在内核空间,应用程序运行在用户空间。大家可以看看这个文章http://www.go-gddq.com/html/QianRuShiXiTong-JiShu/2012-07/1031748.htm
86.你用过或测试过哪些 linux/unix文件系统?
答案:centos5默认是ext3,centos6为ext4,centos7为xfs
87. 怎样用命令查看3天前的CPU分核的负载数据?
答案:sar -f /var/log/sa/(三天前日期)
88. 某命令CPU负载显示以下各段,分别是什么? 10.6%us,6.6%sy, 0.0%ni 74.4%id 0.0%wa
答案:us 用户cpu百分比 sy内核cpu百分比 ni进程占用百分比 id 空闲百分比 wa io等待占用的百分比
89.. 列举你知道的linux下的压力测试程序
答案:测试web的工具:http_load,ab
专业的测试工具loadrunner
90. 描述linux系统下创建软RAID5的命令和步骤
答案:假如有四块硬盘 /dev/sda,/dev/sdb,/dev/sdc,/dev/sdd,分别给他们分一个主分区sda1,sdb1,sdc1和sdd1,然后创建RAID设备名为md0, 级别为RAID5,使用3个设备建立RAID,空余一个做备用.
命令如下:
mdadm --create /dev/md0 --level=5 --raid-devices=3 --spare-devices=1 /dev/sd[a-d]1
使用下面命令查看raid详细信息
mdadm --detail /dev/md0
91 如何查找某一文件被哪个进程打开?
答案:lsof|grep file
92. 新增一块存储设备,lvm操作的命令如何写
答案:
将物理硬盘格式化成pv pvcreate /dev/sdb
创建卷组(VG)并将pv加到VG中 vgcreate vg1 /dev/sdb
基于VG创建逻辑卷(LV) lvcreate -n mylvm -L 20G vg1
93. 给主机host:172.16.0.2 增加gateway10.0.0.1
答案: route add 172.16.0.2 gw 10.0.0.1或者网卡配置文件更改
94.简述linux的优化
【硬件方面】
1. cpu
2. 内存 (增加内存)
3. 存储 (使用raid,使用ssd)
4. 网卡 (使用千兆网卡,或者双网卡绑定)
【系统方面 】
1. 内核参数优化(网络相关、内存相关、缓冲缓存相关)
2. 文件系统方面(分区调优,格式化时根据存储文件特性,指定合适的块大小,noatime,日志隔离,软raid,有效使用/dev/shm,关闭不必要的服务)
3. cpu优化 (进程绑定,中断绑定)
numa架构cpu: http://blog.csdn.net/jollyjumper/article/details/17168175
taskset 把进程和cpu绑定 http://blog.csdn.net/ttyttytty12/article/details/11726569
【应用程序方面】
1. nginx、apache、php-fpm、mysql、tomcat、squid等应用,是可以通过调节各个参数获得性能优化的。
2. web优化,比如可以把用户请求合并(js、css合并),使用cdn加速静态页访问速度,把图片文档压缩减少带宽传输,
3. 优化网站程序
【架构方面】
1. 使用简单并且稳定的架构方案
2. 多使用缓存
10. iptables表和链
filter INPUT FORWARD OUTPUT
nat PREROUTING POSTROUTING OUTPUT
mangle PREROUTING INPUT FORWARD OUTPUT POSTROUTING
95.在不umount的情况下,如何重新设置mount的参数。
答案:mount -o remount,rw /
96. 说一下公司多少台服务器,是什么架构
答案:有7台服务器,lnmp+nginx负载+keepalived,其中2台keepalived+2台nginx/php-fpm+2台mysql(一主一从)+NFS(上面兼着跑监控、备份)
97.提高性能和并发数,需要优化哪些内核参数
答案:
net.ipv4.tcp_max_tw_buckets = 6000 //timewait的数量,默认是180000。
net.ipv4.ip_local_port_range = 1024 65000 //允许系统打开的端口范围。
net.ipv4.tcp_tw_reuse = 1 //允许将TIME-WAIT sockets 重新用于新的TCP 连接。
net.ipv4.tcp_syncookies = 1 //开启SYN Cookies,当出现SYN 等待队列溢出时,启用cookies 来处理。
net.ipv4.tcp_max_orphans = 262144 //系统中最多有多少个TCP套接字不被关联到任何一个用户文件句柄上。如果超过这个数字,孤儿连接将即刻被复位并打印出警告信息。这个限制仅仅是为了防止简单的DoS攻击,不能过分依靠它或者人为地减小这个值,更应该增加这个值(如果增加了内存之后)。
net.ipv4.tcp_max_syn_backlog = 262144 //记录的那些尚未收到客户端确认信息的连接请求的最大值。对于有128M内存的系统而言,缺省值是1024,小内存的系统则是128。
net.ipv4.tcp_synack_retries = 1 //为了打开对端的连接,内核需要发送一个SYN 并附带一个回应前面一个SYN的ACK。也就是所谓三次握手中的第二次握手。这个设置决定了内核放弃连接之前发送SYN+ACK 包的数量。
net.ipv4.tcp_syn_retries = 1 //在内核放弃建立连接之前发送SYN 包的数量。
net.ipv4.tcp_keepalive_time = 30 //当keepalive 起用的时候,TCP 发送keepalive 消息的频度。缺省是2 小时。
98.如何查看当前linux系统的状态如cpu使用,内存使用,负载情况,看到swap使用量大时,是不是意味着物理内存已不够用?
答案:top命令就可以看cpu使用、内存使用以及负载情况,当swap使用率大时,不一定是内存不够,如果swap容量固定不变,那内存就不是瓶颈。用vmstat 1命令看,si so两列的数值在不断变化时,内存就不够了。
99. 如何修改ip主机名DNS?
修改ip和DNS在配置文件/etc/sysconfig/network-scripts/ifcfg-eth0中修改,修改主机名,在/etc/sysconfig/network中修改。
100.如何查看PID为29394的进程的环境变量?
cat /proc/29394/environ
101.当io出现瓶颈时,应该查看哪个参数,为什么?
vmstat 1 查看wa列,wa列表示处于等待状态的cpu百分比,当IO比较慢时,CPU会有大量的wait。
102. 在 bash 里 $0 $? $* $@各表示什么意思?
$0 Shell本身的文件名
$?最后运行的命令的返回值
$*所有参数列表。如"$*"用「"」括起来的情况、以"$1 $2 … $n"的形式输出所有参数
$@ 所有参数列表。如"$@"用「"」括起来的情况、以"$1" "$2" … "$n" 的形式输出所有参数。
103. 描述linux系统下创建软RAID5的命令和步骤
答案:假如有四块硬盘 /dev/sda,/dev/sdb,/dev/sdc,/dev/sdd,分别给他们分一个主分区sda1,sdb1,sdc1和sdd1,
然后创建RAID设备名为md0, 级别为RAID5,使用3个设备建立RAID,空余一个做备用.
使用命令:mdadm
技术无界限,希望能给更多有用的人看到
转自西瓜君 https://www.cnblogs.com/yangzp/p/13052544.html
