CenterNet和Pose和Transformer
Transformer综述:
CenterNet
https://blog.csdn.net/weixin_44791964/article/details/107748542
CenterNet与YOLOv3对比实验:
CenterNet相较于YoloV3原版提升比较明显,但是针对改进YoloV3-spp 提升不明显,也低于U版 YoloV3-spp。但是资源占用有优势
https://mp.weixin.qq.com/s?__biz=MzI2OTg2NTI4Mw==&mid=2247483801&idx=1&sn=b8397d4d1935d993180f38be5a5beabc&chksm=ead899b5ddaf10a3354344ff3b79925f76aa83bc5cfb0c7e0b854f00905dffc029093da7201a&mpshare=1&scene=23&srcid=0202H5PhVLQFNysTkUTvGBUS&sharer_sharetime=1612267832500&sharer_shareid=1c20b220b96b7bb98298f8f63e40b424#rd
CenterNetPose:
通过对中心点的偏移来参数化每个关键点。
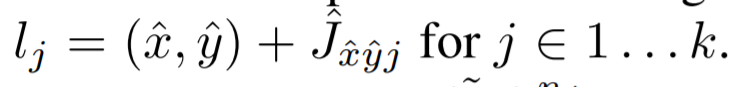

使用focal loss

We ignore the invisible keypoints by masking the loss.
通过掩盖损失来忽略不可见的关键点。
使用自底向上方法。(associate embedding分组)
将我们的初始预测捕捉到这个热图上最接近的检测关键点。在这里,我们的中心偏移作为一个分组线索,将单个的关键点检测分配给它们最接近的人实例。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号