JVM内存模型
GC优化:https://tech.meituan.com/2017/12/29/jvm-optimize.html
jvm内存模型

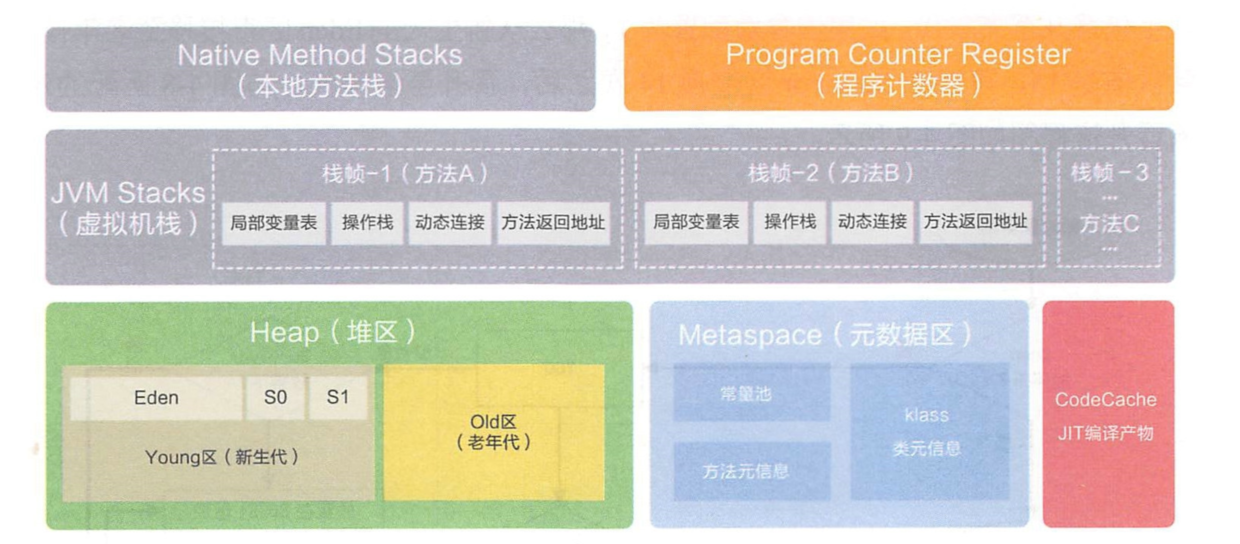
程序计数器
是当前线程所执行的字节码的行号指示器,每条线程都要有一个独立的 程序计数器,这类内存也称为“线程私有”的内存。
虚拟机栈
是描述java方法执行的内存模型,每个方法在执行的同时都会创建一个栈帧(Stack Frame)用于存储局部变量表、操作数栈、动态链接、方法出口等信息。
每一个方法从调用直至执行完成 的过程,就对应着一个栈帧在虚拟机栈中入栈到出栈的过程。
本地方法栈
本地方法栈为Native方法服务
堆
创建的对象和数组都保存在Java堆内存中,也是垃圾收集器进行垃圾收集的最重要的内存区域。
由于现代JVM采用分代收集算法, 因此Java堆从GC的角度还可以 细分为: 新生代( Eden From Survivor 和 To Survivor)和老年代。
方法区
存放已经被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据
运行时常量池和元空间是方法区的一部分
java垃圾回收
https://yq.aliyun.com/articles/708634?utm_content=g_1000067014
判断对象是否为垃圾的算法
1)引用计数算法(一般不用)
优点 执行效率高,程序执行受影响小
缺点 无法检测出循环引用的情况,导致内存泄漏
2)可达性分析法:通过判断对象的引用链是否可达来决定对象是否可以被回收
垃圾回收算法
1)标记-清除算法
2)复制算法
解决了碎片化问题
顺序分配内存,简单高效
适用于对象存活率低的场景
3)标记-整理
4)分代收集算法(常用)
按照对象生命周期的不同划分区域以采用不同的垃圾回收算法
新生代:采用复制算法
老年代:采用用"标记-清除"或者"标记-整理"算法
永久代(方法区):同老年区 (1.8以后已经没有)
四种引用类型
| 引用类型 | 被垃圾回收时间 | 用途 | 生存时间 |
|---|---|---|---|
| 强引用 | 从来不会 | 对象的一般状态 | JVM停止时终止 |
| 软引用 | 在内存不足时 | 对象缓存 | 内存不足时终止 |
| 弱引用 | 垃圾回收时 | 对象缓存 | Gc运行后终止 |
| 虚引用 | 不确定 | 标记、哨兵 | 不确定 |
进阶
可达性分析法:
可达性算法的原理是以 GC Root 为起点出发,引出它们指向的下一个节点,再以下个节点为起点,引出此节点指向的下一个结点。直到所有的结点都遍历完毕,如果相关对象不在任意一个以 GC Root 为起点的引用链中,则这些对象会被判断为「垃圾 回收。
当对象不可达(可回收)时,会先判断对象是否执行了 finalize 方法,如果未执行,则会先执行 finalize 方法,我们可以在此方法里将当前对象与 GC Roots 关联,这样执行 finalize 方法之后,GC 会再次判断对象是否可达,如果不可达,则会被回收,如果可达,则不回收!
注意: finalize 方法只会被执行一次
Stop一the一World
如果老年代满了,会触发 Full GC, Full GC 会同时回收新生代和老年代(即对整个堆进行GC),它会导致 STW,造成大的性能开销。
即在 GC(minor GC 或 Full GC)期间,只有垃圾回收器线程在工作,其他工作线程则被挂起。
G1特点:
G1的设计原则是"首先收集尽可能多的垃圾(Garbage - First)"。因此,G1并不会等内存耗尽(串行、并行)或者快耗尽(CMS)的时候开始垃圾收集,而是在内部- 采用了启发式算法,在老年代找出具有高收集收益的分区进行收集。同时G1可以根据用户设置的暂停时间目标自动调整年轻代和总堆大小,暂停目标越短年轻代空间越小、总空间就越大;
G1采用内存分区(Region)的思路,将内存划分为一个个相等大小的内存分区,回收时则以分区为单位进行回收,存活的对象复制到另一个空闲分区中。由于都是以相等大小的分区为单位进行操作,因此G1天然就是一种压缩方案(局部压缩);
G1虽然也是分代收集器,但整个内存分区不存在物理上的年轻代与老年代的区别,也不需要完全独立的- survivor(to space)堆做复制准备。G1只有逻辑上的分代概念,或者说每个分区都可能随G1的运行在不同代之间前后切换;
G1的收集都是STW的,但年轻代和老年代的收集界限比较模糊,采用了混合(mixed)收集的方式。即每次- 收集既可能只收集年轻代分区(年轻代收集),也可能在收集年轻代的同时,包含部分老年代分区(混合收集),这样即使堆内存很大时,也可以限制收集范围,从而降低停顿
http://javainterview.gitee.io/luffy/2021/08/20/04-Java虚拟机/06. G1垃圾收集器/
G1(Garbage First) 收集器
G1 收集器是面向服务端的垃圾收集器,被称为驾驭一切的垃圾回收器,主要有以下几个特点
像CMS收集器一样,能与应用程序线程并发执行。
整理空闲空间更快。
需要GC停顿时间更好预测。
不会像 CMS 那样牺牲大量的吞吐性能。
不需要更大的Java Heap 与 CMS 相比,它在以下两个方面表现更出现
运作期间不会产生内存碎片,G1从整体上看采用的是标记-整理法,局部(两个Region)上看是基于复制算法实现的,两个算法都不会产生内存碎片,收集后提供规整的可用内存,这样有利于程序的长时间运行。
在 STW 上建立了可预测的停顿时间模型,用户可以指定期望停顿时间,G1会将停顿时间控制在用户设定的停顿时间以内。
为什么G1能建立可预测的停顿模型呢,
主要原因在于 G1 对堆空间的分配与传统的垃圾收集器不一器,传统的内存分配就像我们前文所述,是连续的,分成新生代,老年代,新生代又分 Eden,S0,S1,
而 G1 各代的存储地址不是连续的,每一代都使用了n个不连续的大小相同的Region,每个Region占有一块连续的虚拟内存地址
除了和传统的新老生代,幸存区的空间区别,Region还多了一个H,它代表Humongous,这表示这些Region存储的是巨大对象(humongous object,H-obj),即大小大于等于region一半的对象,这样超大对象就直接分配到了老年代,防止了反复拷贝移动。那么 G1 分配成这样有啥好处呢?
传统的收集器如果发生 Full GC 是对整个堆进行全区域的垃圾收集,而分配成各个 Region 的话,方便 G1 跟踪各个 Region 里垃圾堆积的价值大小(回收所获得的空间大小及回收所需经验值),这样根据价值大小维护一个优先列表,根据允许的收集时间,优先收集回收价值最大的 Region,也就避免了整个老年代的回收,也就减少了 STW 造成的停顿时间。同时由于只收集部分 Region,可就做到了 STW 时间的可控。
G1 收集器的工作步骤如下
初始标记
并发标记
最终标记
筛选回收
可以看到整体过程与 CMS 收集器非常类似,筛选阶段会根据各个 Region 的回收价值和成本进行排序,根据用户期望的 GC 停顿时间来制定回收计划。
JDK17 垃圾回收器
java -XX:+PrintCommandLineFlags -version
-XX:ConcGCThreads=3 -XX:G1ConcRefinementThreads=10 -XX:GCDrainStackTargetSize=64 -XX:InitialHeapSize=267784512 -XX:MarkStackSize=4194304 -XX:MaxHeapSize=4284552192 -XX:MinHeapSize=6815736 -XX:+PrintCommandLineFlags -XX:ReservedCodeCacheSize=251658240 -XX:+SegmentedCodeCache -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseG1GC -XX:-UseLargePagesIndividualAllocation
openjdk version "17.0.1"
OpenJDK Runtime Environment Temurin-17.0.1+12 (build 17.0.1+12)
OpenJDK 64-Bit Server VM Temurin-17.0.1+12 (build 17.0.1+12, mixed mode, sharing)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号