win10//ubuntu安装tensorflow-gpu与kears,并用minist测试
WIn10
安装cuda
先安装VS,然后根据自己的版本安装CUDA、
安装完后,打开cmd命令行输入nvcc -V,检测是否安装成功
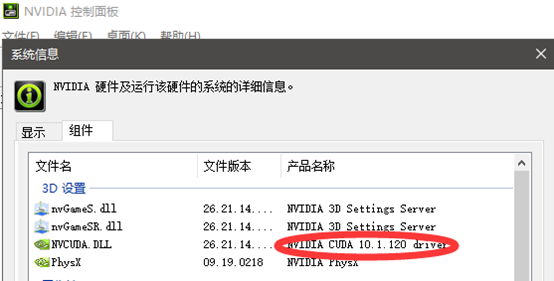
安装cuDDN
安装对应版本,解压后覆盖到CUDA的地址,默认为C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.1
使用anaconda安装tensorflow-gpu
创建一个新的环境
conda create -n env_name python=version
激活并进入环境中
conda activate tensorflow
更换清华源(https://mirrors.tuna.tsinghua.edu.cn/help/anaconda/)(也可使用其他源)
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --set show_channel_urls yes
安装
conda install tensorflow-gpu (或者是pip,注意版本,这里是1.x,需要安装keras,后续keras已经自带,不需要单独安装)
测试
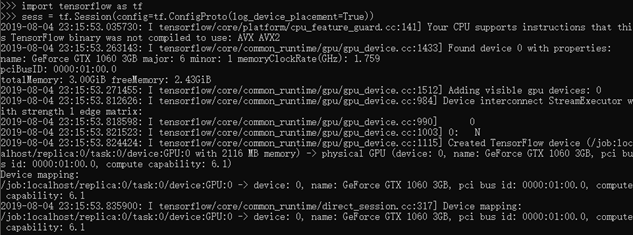
安装keras
conda install keras
使用jupyter
Jupyter Notebook
添加其他conda虚拟环境
https://blog.csdn.net/u011606714/article/details/77741324
Ubunt/18.04
1、安装驱动
2、nvidia-smi,查看自己的驱动和CUDA版本,没有cuda也可以在conda里装
3、安装anaconda
4、新建一个虚拟环境
5、激活虚拟环境,以下操作在虚拟环境中进行conda create -n env_name python=version
pip 和 conda 更新清华源 https://mirrors.tuna.tsinghua.edu.cn/help/pypi/
6、conda list 看有没有cuda,cudnn,没有的话再装(conda install cudatoolkit conda install cudnn)
7、conda install python==3.7 ,安装python是为了后面使用虚拟环境的python,不会和本机环境打架(如果已经装了,就不用再装了)
8、pip install tensorflow-gpu
(安装的是tf2,里面自带keras。如果需要其他版本自行设定。 注意!!! tf2-gpu 需要cuda10.0,10.1会报错,至少截止目前(2019.11.20)是这样)
updata 2020.1.8
conda search tensorflow-gpu
conda install tensorflow-gpu=2.0.0
遇到的问题(重点):
记录遇到的一些环境问题
目前已知tf2-gpu无法在cuda10.1上运行,错误提示:缺少动态链接库
退回到cuda10.0,cudnn7,6,遇到Could not create cudnn handle: CUDNN_STATUS_INTERNAL_ERROR
在 https://github.com/tensorflow/tensorflow/issues/24496 找到解决办法
```
import tensorflow as tf
config = tf.compat.v1.ConfigProto()
config.gpu_options.allow_growth = True
session = tf.compat.v1.Session(config=config)
```
或者是
```
physical_devices = tf.config.experimental.list_physical_devices('GPU')
tf.config.experimental.set_memory_growth(physical_devices[0], True)
```
这个的意思大概是tf会默认占用所有闲置现存,然后加上这个后,就动态分配现存
看评论说,这个问题多出现在RTX显卡上。而且这种解决方法会影响速度,暂时没有其他方法
下面用搭建CNN测试环境


import tensorflow as tf from tensorflow.keras import datasets, layers, models, losses ''' 第一步:选择模型 ''' model = models.Sequential() ''' 第二步:构建网络层 ''' # 第1层卷积,卷积核大小为3*3,32个,28*28为待训练图片的大小 model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1))) model.add(layers.MaxPooling2D((2, 2))) # 第2层卷积,卷积核大小为3*3,64个 model.add(layers.Conv2D(64, (3, 3), activation='relu')) model.add(layers.MaxPooling2D((2, 2))) # 第3层卷积,卷积核大小为3*3,64个 model.add(layers.Conv2D(64, (3, 3), activation='relu')) model.add(layers.Flatten()) model.add(layers.Dense(64, activation='relu')) model.add(layers.Dense(10, activation='softmax')) model.summary() ''' 第三步:编译 ''' # sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True) # 优化函数,设定学习率(lr)等参数 # 使用交叉熵作为loss函数 # compile()方法只有三个参数: 优化器optimizer,损失函数loss和指标列表metrics model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy']) ''' 第四步:训练 .fit的一些参数 batch_size:对总的样本数进行分组,每组包含的样本数量 epochs :训练次数 shuffle:是否把数据随机打乱之后再进行训练 validation_split:拿出百分之多少用来做交叉验证 verbose:屏显模式 0:不输出 1:输出进度 2:输出每次的训练结果 validation_data:指定验证集, 此参数将覆盖validation_spilt。 ''' (X_train, Y_train), (X_test, Y_test) = datasets.mnist.load_data() # 使用Keras自带的mnist工具读取数据(第一次需要联网) # 由于mist的输入数据维度是(num, 28, 28),这里需要把后面的维度直接拼起来变成784维 X_train = X_train.reshape(X_train.shape[0], 28, 28, 1).astype('float32') / 255 X_test = X_test.reshape(X_test.shape[0], 28, 28, 1).astype('float32') / 355 model.fit(X_train, Y_train, batch_size=200, epochs=20, validation_split=0.2, verbose=1) ''' 第五步:输出结果 ''' scores = model.evaluate(X_test, Y_test, batch_size=200) print('Test loss:', scores[0]) print('Test accuracy:', scores[1])
从本地读取npz格式数据minist
1 from __future__ import absolute_import, division, print_function, unicode_literals 2 3 import numpy as np 4 import tensorflow as tf 5 import tensorflow_datasets as tfds 6 7 FILE_PATH = '/xxx/mnist.npz' 8 9 with np.load(FILE_PATH) as data: 10 train_examples = data['x_train'] / 255.0 11 train_labels = data['y_train'] 12 test_examples = data['x_test'] / 255.0 13 test_labels = data['y_test'] 14 15 train_dataset = tf.data.Dataset.from_tensor_slices((train_examples, train_labels)) 16 test_dataset = tf.data.Dataset.from_tensor_slices((test_examples, test_labels)) 17 18 BATCH_SIZE = 64 19 SHUFFLE_BUFFER_SIZE = 100 20 21 train_dataset = train_dataset.shuffle(SHUFFLE_BUFFER_SIZE).batch(BATCH_SIZE) 22 test_dataset = test_dataset.batch(BATCH_SIZE) 23 24 model = tf.keras.Sequential([ 25 tf.keras.layers.Flatten(input_shape=(28, 28)), 26 tf.keras.layers.Dense(128, activation='relu'), 27 tf.keras.layers.Dropout(0.2), 28 tf.keras.layers.Dense(10, activation='softmax') 29 ]) 30 31 model.compile(optimizer=tf.keras.optimizers.RMSprop(), 32 loss=tf.keras.losses.SparseCategoricalCrossentropy(), 33 metrics=[tf.keras.metrics.SparseCategoricalAccuracy()]) 34 35 model.fit(train_dataset, epochs=10) 36 37 model.evaluate(test_dataset)
ubuntu解决终端不走vpn
export http_proxy="http://localhost:port" export https_proxy="http://localhost:port"
再推荐一个好用的下载软件
axel
安装:
sudo apt-get install axel
- 一般使用:axel url(下载文件地址)
- 限速使用:加上 -s 参数,如 -s 10240,即每秒下载的字节数,这里是 10 Kb
- 限制连接数:加上 -n 参数,如 -n 5,即打开 5 个连接
View Code
 浙公网安备 33010602011771号
浙公网安备 33010602011771号