聚类模型的算法性能评价
一、概述
作为机器学习领域的重要内容之一,聚类模型在许多方面能够发挥举足轻重的作用。所谓聚类,就是通过一定的技术方法将一堆数据样本依照其特性划分为不同的簇类,使得同一个簇内的样本有着更相近的属性。依不同的实现策略,聚类算法有很多种,如基于距离的k-means、基于密度的DBSCAN等。在聚类完成之后,其性能的评估是一个不可规避的问题,常见的评估方法依有无事先的标记性信息分为外部评估法和内部评估法。
二、评价指标
1.外部评估法
一种常用的评估方式是外部评估,利用测试样本事先已有的标记信息来衡量模型的性能。常见的外部评估指标有纯度(Purity)、兰德指数(Rand Index, RI)、调整兰德指数(Adjusted Rand Index, ARI)、F值(F-score)、杰卡德系数(Jaccard, JC)、标准化互信息(NMI)等。
(1)纯度
纯度是一种较直接的性能表征方式,计算的是正确聚类的样本数与总样本数的比值。在聚类完成之后,对每个簇内的样本,假设知晓其事先的标记性属性信息,每个簇中类别数量最多的样本即作为该簇的属性类别,给类别下的样本即纯性样本,各个簇的纯性样本数之和对总样本数的占比即纯度(Purity)。表达式为
其中,N为总的样本数,\(\Omega=\left\{ w_1,w_2,...,w_K \right\}\)表示聚类簇的划分,\(C=\left\{ c_1,c_2,...,c_J \right\}\) 表示样本真实类别的划分。纯度的取值范围是[0,1],值越大,性能越好。
【示例】
现对一堆样本进行聚类操作,划分了三个簇,如下所示
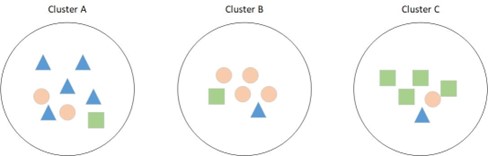
在Cluster A中,三角形最多,因此该簇归属为三角形的簇,有效样本数为5;
在Cluster B中,圆形最多,因此该簇归属为圆形的簇,有效样本数为4;
在Cluster C中,正方形最多,因此该簇归属为正方形的簇,有效样本数为4。
纯度为有效样本数对总样本的占比
(2)兰德指数
对于已有了预先标记信息的情形,可以以与分类模型中相类似的方式进行衡定,明确下列几个概念
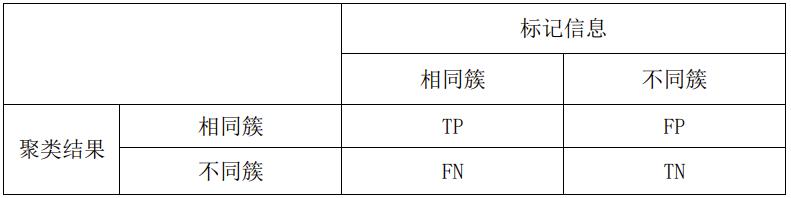
TP(True Positive):同类样本点被划分在同一个簇中的可能情形数;
FP(False Positive):非同类样本点被划分在同一个簇中的可能情形数;
TN(True Negative):非同类样本点分布在不同簇中的可能情形数;
FN(False Negative):同类样本点分布在不同簇中的可能情形数。
兰德指数就是指准确率,聚类后样本分布的整体准确率,定义为
(3)调整兰德指数
对于随机结果,兰德指数并不能保证值接近于零,这与直观上的意义不甚符合,为能够改善这种情况,调整的兰德指数(ARI)被提出。它的表达式为
ARI取值范围为[-1,1],值越接近于1,性能越好;接近于0,相当于随机聚类;接近于-1,性能不如随机聚类。
(4)F值
这里同样首先借鉴了分类模型中精准度和召回率的概念,然后以F度量进行综合衡定。精准度(Precision)和召回率(Recall)定义为
F度量综合衡量精确度(查准率)和召回率(查全率),\(F_\beta\)是F1的一般形式,能让我们表达出对查准率/查全率的不同偏好,如F1分数认为召回率和精确度同等重要,F2分数认为召回率的重要程度是精确度的两倍,而F0.5分数认为召回率的重要程度是精确度的一半。
F度量的取值范围为[0,1],值越大性能越好。
(5)杰卡德系数
杰卡德系数(Jaccard, JC)定义为聚类结果正确的样本数与聚簇结果或实际结果一致的比例,取值范围为0到1。表达式为
杰卡德系数值越大,性能越好。
(6)标准化互信息
这里首先介绍一下互信息(Mutual Information)的概念,它反映了两个事件相互影响所产生的信息量。设两个随机变量(X,Y)的联合分布为p(x,y),边缘分布分别为p(x),p(y),互信息I(X; Y)是联合分布p(x,y)与边缘分布p(x)p(y)的相对熵,即
标准化互信息(Normalized Mutual Information, NMI)计算表达式为
其中F(x,y)可以为min/max函数、几何平均或算术平均,几何平均即\(F\left( x_1,x_2 \right)=\sqrt{x_1\cdot x_2}\) ,算术平均即\(F\left( x_1,x_2 \right)=\frac{x_1+x_2}{2}\),采用算术平均是比较常见的一种计算方式,此时NMI表达式可化为
其中,I(X,Y)为互信息,\(H\left( X \right)=-\sum_{i}{p(x_i)logp(x_i)}\),\(H\left( Y \right)=-\sum_{j}{p(y_j)logp(y_j)}\)为信息熵。
2.内部评估法
另一种常用的评估方式是内部评估,利用测试样本本身的信息衡量模型性能。常见的内部评估指标有紧密度(Compactness, CP)、间隔度(Separation, SP)、轮廓系数(Silhouette Coefficient, SC)、戴维森堡丁指数(Davies-Bouldin Index, DBI)、邓恩指数(Dunn Validity Index, DVI)等。
(1)紧密度
紧密度(Compactness, CP)是指簇内各点到聚类中心的平均距离,值越小说明簇内紧密度越高
(2)间隔度
间隔度(Separation, SP)指各个聚类中心之间的平均距离,值越高表明类间距离越大
(3)轮廓系数
对单个样本,设a是其与同簇中其他样本的平均距离,b是与它距离最近的不同簇类中样本的平均距离,轮廓系数为
样本集合的轮廓系数是各样本轮廓系数的平均值
轮廓系数的取值范围是[-1,1],取值越接近1聚类性能越好,反之越差。
(4)戴维森堡丁指数
对于两个簇的样本而言,各自簇内平均距离之和除以两簇中心的距离,称为簇间相似度,簇间相似度越小说明簇内距离越小、簇间距离越大,效果越好。对所有的簇,分别找到与之聚类效果最差那个簇的簇间相似度,然后求平均值,即为戴维森堡丁指数(DBI)的定义。表达式为
其中,\(\sigma_i=\frac{1}{n_i}\sum_{k=1}^{n_i}{x_k-\mu_i}\),\(\sigma_j=\frac{1}{n_j}\sum_{k=1}^{n_j}{x_k-\mu_j}\),\(d\left( c_i,c_j \right)=\left| \left| \mu_i-\mu_j \right| \right|_2\)。
易知,DBI值越小,表明聚类效果越好,反之越差。
(5)邓恩指数
邓恩指数定义为两簇之间最小的那个簇间距离与各簇中最大的那个簇内距离的比值。表达式为
其中,簇间距离指两个簇的质心之间的距离,对于维度为D的样本集有
簇内距离是簇内各样本到质心的平均距离,对于一个簇S,若质心为c,则它的簇内距离表达式为
因簇间距离越大、簇内距离越小时聚类效果越好,所以邓恩指数越大,性能越好。
End.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号