
Linux下图示安装Hadoop-2.8.5(单机版)
Linux下图示安装Hadoop-2.8.5(单机版)
前言:Hadoop2.x的四个模块.Hadoop Common,Hadoop HDFS,Hadoop MapReduce,Hadoop YARN.Centos7的版本。
一:Hadoop的的的下载。
1. 官网。
2.版本。
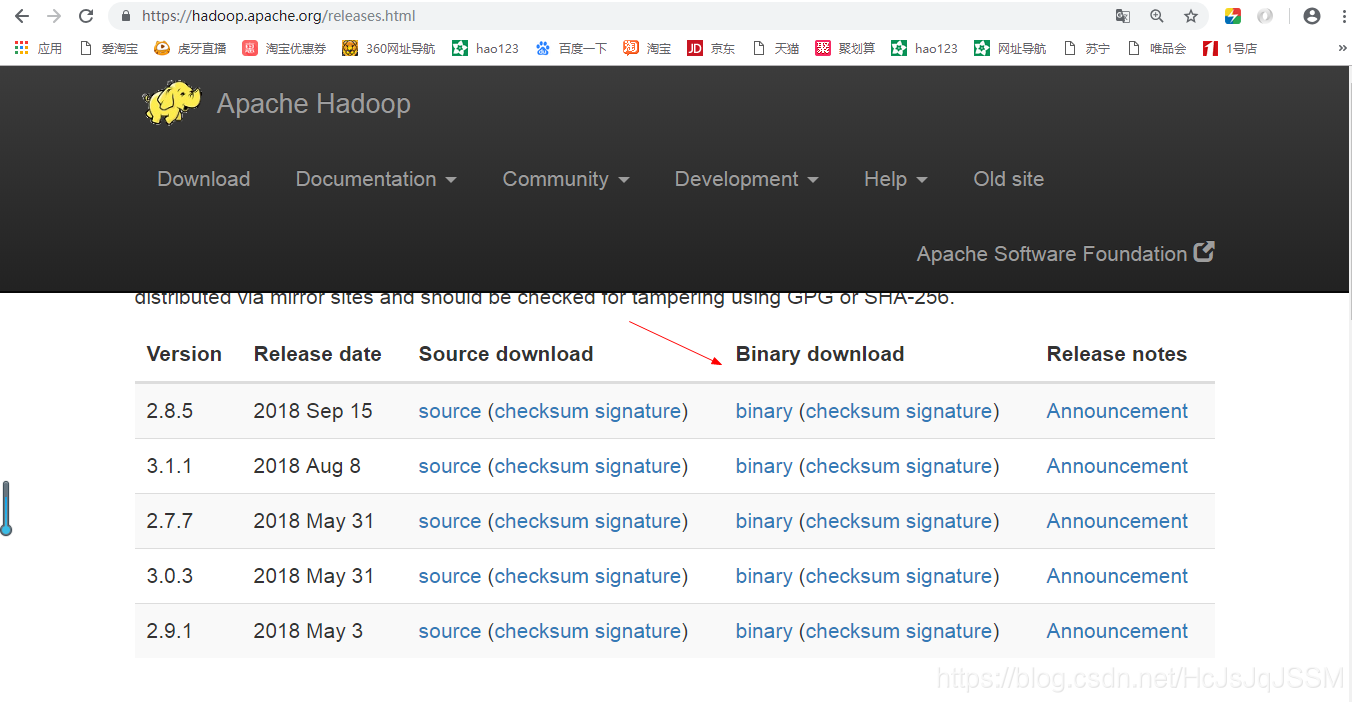
分为源码和二进制的。这里下载二进制的。这里是简单学习使用的是阿帕奇的版本。

3.下载的Hadoop。
wget XXX.tar.gz
 4.加压到指定的目录下。
4.加压到指定的目录下。
tar -zxvf XXX.tar.gz -C / usr / local
5. Hadoop目录结构。
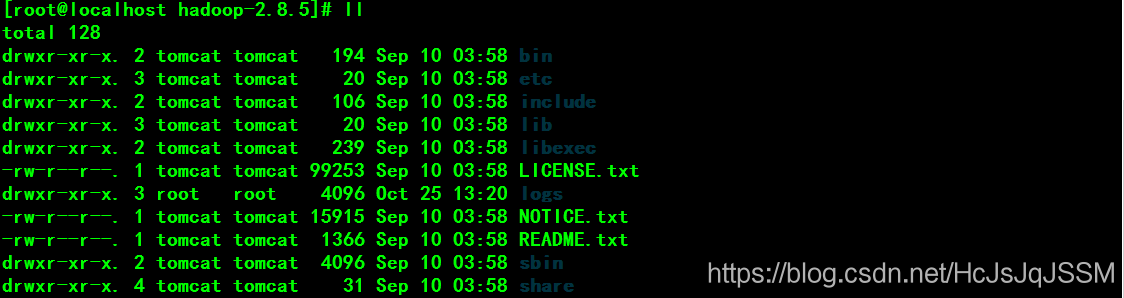
6.查看的Hadoop的版本。(记得配置环境的Hadoop的环境变量)。
cd bin
Hadoop的版本

二.Hadoop环境配置。
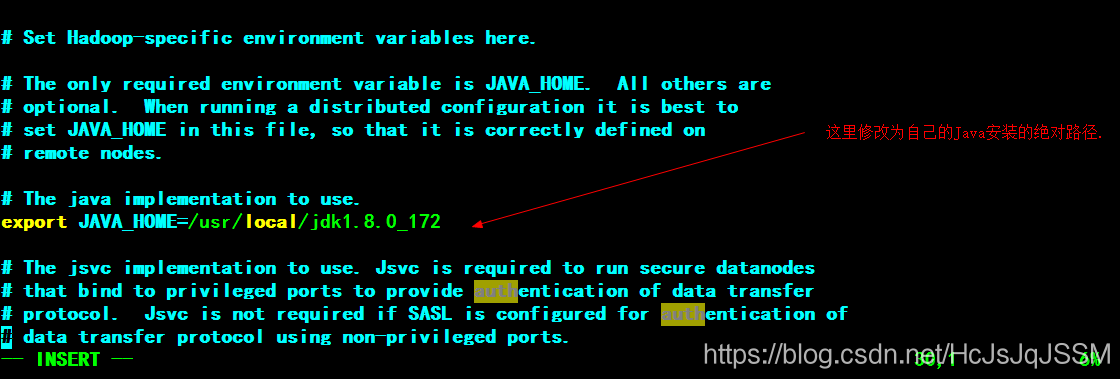
1. Java环境配置。(使用Java8的版本)
Hadoop的的是Java的的开发的大数据框架,因此首先要准备好Java的的的环境。这个就不介绍了。注意一下配置文件。
cat / etc / profile
 2.配置的Hadoop的环境变量。
2.配置的Hadoop的环境变量。
vim / etc / profile
export HAOOP_HOME = / usr / local / hadoop-2.8.5
export PATH = $ PATH:$ HADOOP_HOME / bin

vim httpfs-env.sh
查看Hadoop HDFS支持的所有命令。

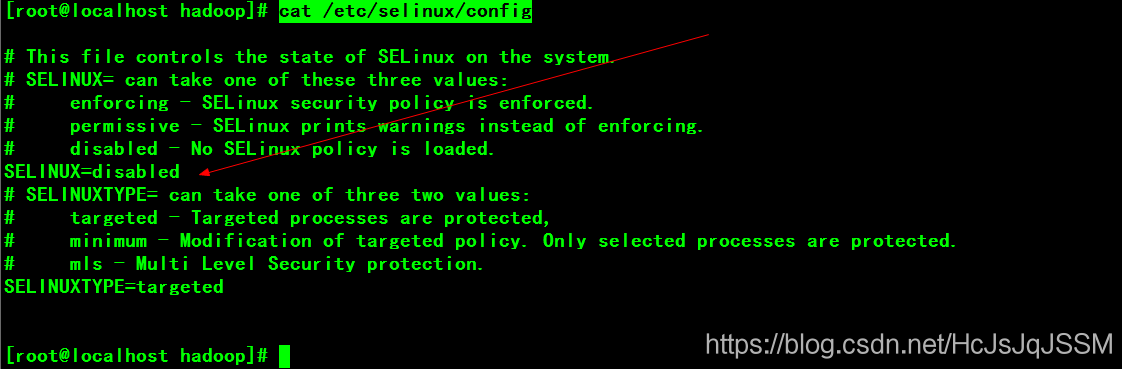
3.查看防火墙和关闭SELinux的。
firewall-cmd --state 
cat / etc / selinux / config
4.修改配置文件。(这里就直接使用自己Linux的IP了,就不配置域名了).etc / hosts
在修改配置文件前,先创建一下几个目录。
mkdir / root / hadoop
mkdir / root / hadoop / tmp
mkdir / root / hadoop / var
mkdir / root / hadoop / dfs
mkdir / root / hadoop / dfs / name
mkdir / root / hadoop / dfs / data
然后是依次修改下面一个XML文件。
cd /usr/local/hadoop-2.8.5/etc/hadoop
vim core-site.xml
-
<configuration>
-
<property>
-
<name>hadoop.tmp.dir</name>
-
<value>/root/hadoop/tmp</value>
-
<description>Abase for other temporary directories.</description>
-
</property>
-
<property>
-
<name>fs.default.name</name>
-
<value>hdfs://192.168.217.134:9000</value>
-
</property>
-
</configuration>
接下来就是vim hdfs-site.xml
-
<configuration>
-
<property>
-
<name>dfs.name.dir</name>
-
<value>/root/hadoop/dfs/name</value>
-
<description>Path on the local filesystem where theNameNode stores the namespace and transactions logs persistently.</description>
-
</property>
-
<property>
-
<name>dfs.data.dir</name>
-
<value>/root/hadoop/dfs/data</value>
-
<description>Comma separated list of paths on the localfilesystem of a DataNode where it should store its blocks.</description>
-
</property>
-
<property>
-
<name>dfs.http.address</name>
-
<value>192.168.217.134:50070</value>
-
</property>
-
<property>
-
<name>dfs.replication</name>
-
<value>1</value>
-
</property>
-
<property>
-
<name>dfs.namenode.secondary.http-address</name>
-
<value>192.168.217.134:50090</value>
-
</property>
-
<property>
-
<name>dfs.permissions</name>
-
<value>true</value>
-
<description>need not permissions</description>
-
</property>
-
</configuration>
dfs.permissions配置为假后,可以允许不要检查权限就生成DFS上的文件,方便倒是方便了,但是你需要防止误删除,请将它设置为真,或者直接将该属性节点删除,因为默认就是真正。
接下来是:
vim mapred-site.xml(没有那个mapred-site.xml文件就触摸mapred-site.xml)。
-
<configuration>
-
<property>
-
<name>mapred.job.tracker</name>
-
<value>192.168.217.134:9001</value>
-
</property>
-
<property>
-
<name>mapred.local.dir</name>
-
<value>/root/hadoop/var</value>
-
</property>
-
<property>
-
<name>mapreduce.framework.name</name>
-
<value>yarn</value>
-
</property>
-
</configuration>
三.Hadoop启动。
1.第一次启动时要初始化,格式化的NameNode。
cd bin
./hdfs namenode -format
2.切换sbin目录目录下。
cd ..
cd sbin
sh start-dfs.sh(需要输入用户名,分别是启动namenode)。
sh start-yarn.sh
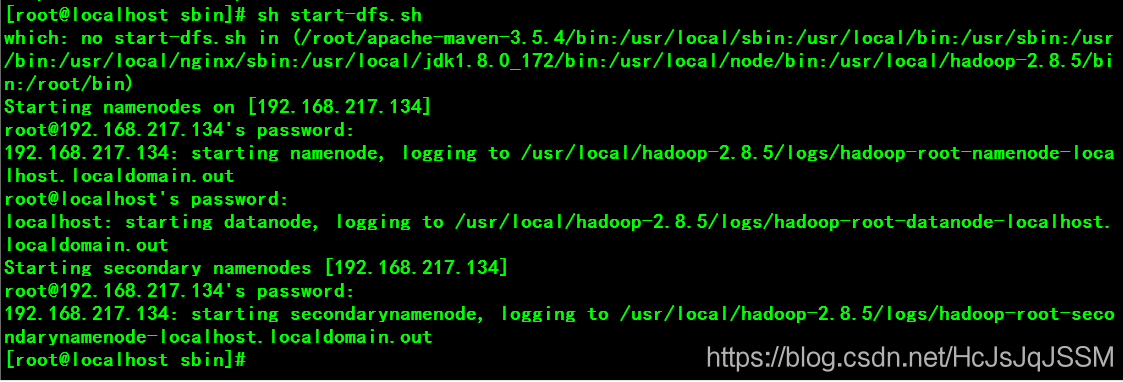
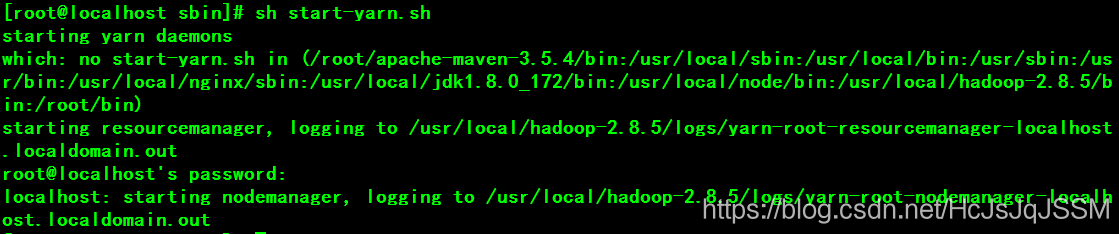 JPS
JPS

浏览器访问如下:
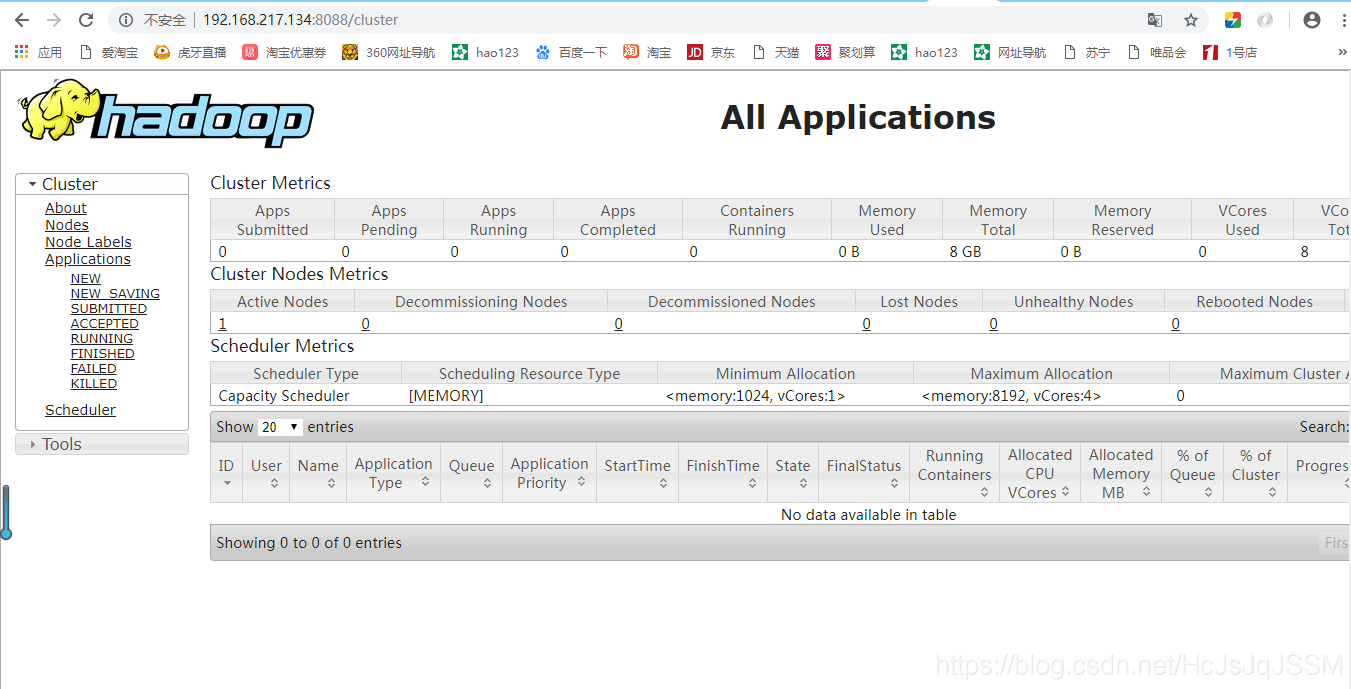
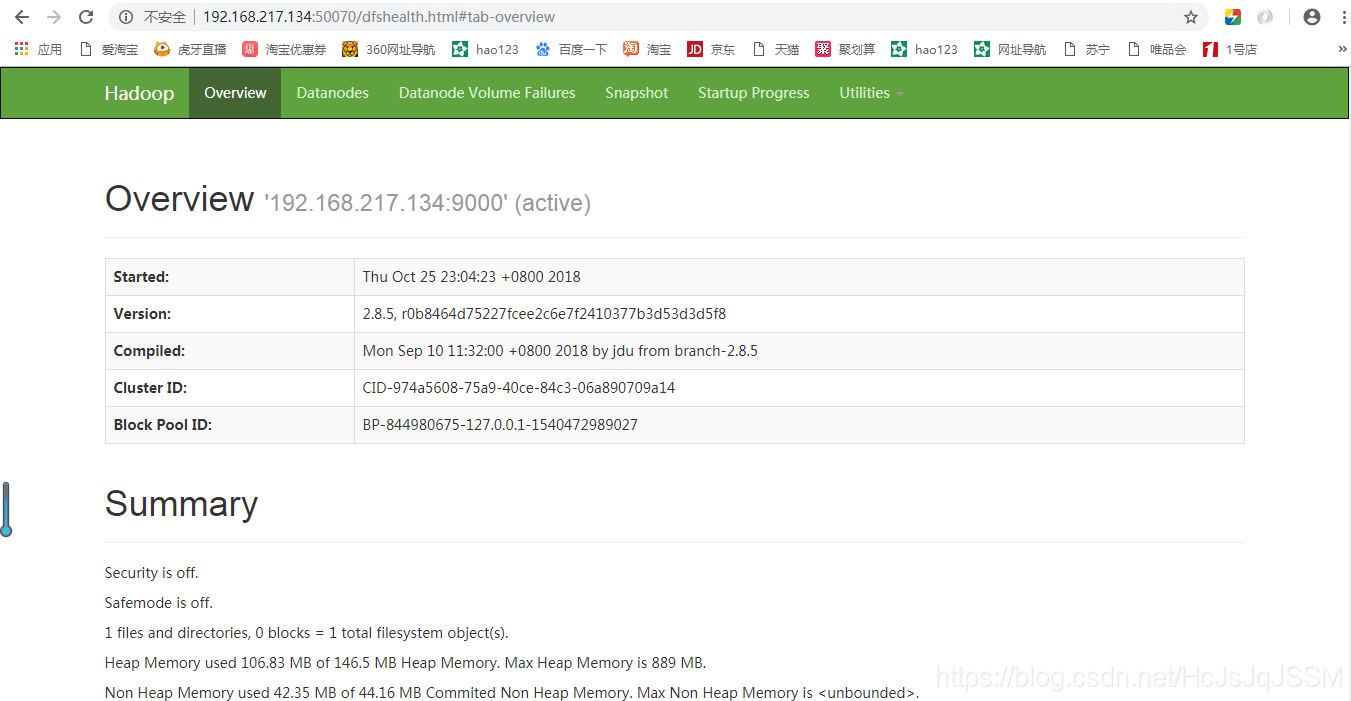
关闭HDFS和纱线:
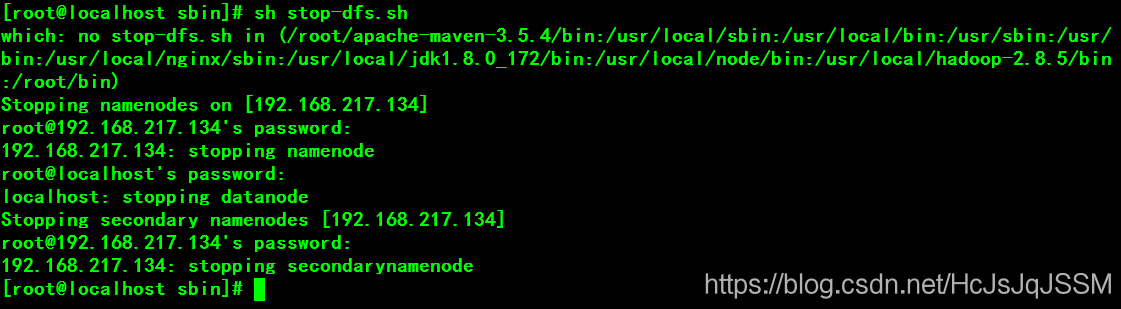
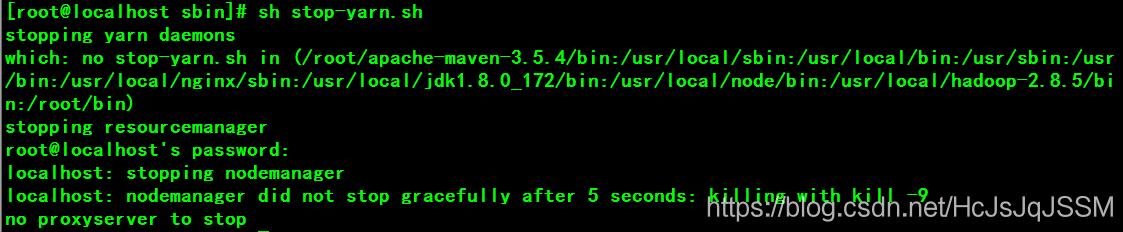
遇到启动问题可以看一看启动日志吧。
重新格式化名称节点之前需要清空DFS下的名称和数据文件夹以解决数据节点无法启动的问题。
cat hadoop-root-datanode-localhost.localdomain.out.1
cat hadoop-root-namenode-localhost.localdomain.log
至此完成的的Linux下的的Hadoop的安装。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号