【mysql】一、mysql的学习---索引
mysql的学习
资料来源 https://www.bilibili.com/video/BV1CZ4y1M7MQ?from=search&seid=3518646188262100291
三、存储过程和函数:【mysql】三、mysql的学习---存储过程和函数
四、触发器:【mysql】四、mysql的学习---触发器
五、存储引擎:【mysql】五、mysql的学习---存储引擎
六、SQL优化:【mysql】六、mysql的学习---SQL优化
七、应用优化:【mysql】七、mysql的学习---应用优化
八、查询缓存:【mysql】八、mysql的学习---查询缓存
九、内存优化:【mysql】九、mysql的学习---内存优化
十、Mysql并发参数调整和锁: 【mysql】十、mysql的学习---Mysql并发参数调整和锁
十一、常用的SQL技巧:【mysql】十一、mysql的学习---常用的sql技巧
本篇文章主要介绍 索引 的相关知识
1. 索引的基本定义
mysql官方对索引的定义为:
索引是帮助mysql高效获取数据的数据结构(有序)。在数据之外,数据库还维护着满足特定查找算法的数据结构,这些数据结构以某种方式指向数据,这样就可以在这些数据结构上实现高级查找算法,这种数据结构就是索引。
一般来说,索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储在磁盘上。索引是数据库中用来提高性能的最常用的工具。
下图中左面是数据表,共2列7条数据,最左边是数据记录的物理地址(注意逻辑上相邻的记录在磁盘上也并不是一定物理相邻的)。为了加快col2的查找,可以维护一个右边所示的二叉查找树,每个节点包含索引键值和一个指向对应数据记录物理地址的指针,这样就可以运用二叉查找快速获取到相应数据。
如下图所示:
现在想要从数据库中查到值为3的结果,对比加索引和不加索引两种情况下的区别:
(1)没有建立索引:
按照34、77、5、91、22、59、3的顺序,最后经过了7次的对比查到了。
(2)建立索引:
这建立索引采用的是二叉树的形式,比父节点大的放在右面,小的放在左面。即首先定义一个父节点为34,之后存储77,因为77 > 34,所以放在右侧,之后放5,因为5 < 34 ,所以放在了左侧,之后放91,首先是91 > 34 所以应该放在右面,因为是二叉树,即每个节点只有两个子节点,所以只能放在77节点下的右侧,依次类推,形成了下图的二叉树。
使用了索引查找值为3的数据,步骤如下,首先判断3 < 34,所以3应该在34的左侧,那么左侧是5,再去对比3 < 5,所以3应该在5的左侧,发现正好是3,所以找到了,共需要对比三次,效率有了提升。

2. 索引的优劣势
优势
(1)类似于书籍的目录索引,提高数据检索的效率,降低数据库的IO成本。
(2)通过索引列对数据进行排序,降低数据排序的成本,降低CPU的消耗。
劣势
(1)索引实际上也是一张表,该表中保存了主键与索引字段,并指向实体类的记录,所以索引列也是要占用空间的。
(2)虽然索引大大提高了查询效率,同时却也降低了更新表的速度,如对表进行增、删、改操作。因为更新表时,Mysql不仅要保存数据,还要保存一下索引文件每次更新添加了索引列的字段,都会调整因为更新所带来的键值变化后的索引信息。
3. 索引的数据结构
索引是在MySQL的存储引擎层中实现的,而不是在服务层实现的。所以每种存储引擎的索引都不一定完全相同,也不是所有的索引引擎都支持所有的索引类型的。MySQL目前提供了以下4种索引:
(1)Btree索引:最常见的索引类型,大部分索引都支持B树索引。
(2)Hash索引:只有Memory引擎支持,使用场景简单。
(3)R-tree索引:也叫空间索引,是MyISAM引擎的一个特殊索引类型,主要用于地理空间数据类型,通常使用较少。
(4)Full-text:也叫全文索引,是MyISAM的一个特殊索引类型,主要用于全文索引,InnoDB从Mysql5.6版本开始支持全文索引。
我们平常所说的索引,如果没有特别指明,都是指B+树(多路搜索树,并不一定是二叉的)结构组织的索引。其中聚集索引、符合索引、前缀索引、唯一索引默认都是使用B+tree索引,统称为索引。
| 索引 | InnoDB引擎 | MyISAM引擎 | Memory引擎 |
| BTREE索引 | 支持 | 支持 | 支持 |
| HASH索引 | 不支持 | 不支持 | 支持 |
| R-tree索引 | 不支持 | 支持 | 不支持 |
| Full-text | 5.6版本之后支持 | 支持 | 不支持 |
3.1 BTree索引介绍
BTree又叫多路平衡搜索树,一颗m叉的BTree特性如下:
(1)树中的每个节点最多包含m个孩子。
(2)除根节点与叶子节点外,每个节点至少有[ceil(m/2)]个孩子。【ceil:向上取整】
(3)若根节点不是叶子节点,则至少有两个孩子。
(4)所有的叶子节点都在同一层。
(5)每个非叶子节点由n个key与n+1个指针组成,其中[ceil(m/2)-1] <= n <= m-1
以5叉BTree为例,key的数量:公式推导[ceil(m/2)-1] <= n <= m-1。所以2 <= n <=4。当n>4时,中间节点分裂到父节点,两边节点分裂。插入C N G A G E K Q M F W L T Z D P R X Y S 数据为例。演变过程如下:
# 步骤一 # 插入前四个字母C N G A

# 步骤二 # 插入H,n>4,中间元素G字母向上分裂到新的节点
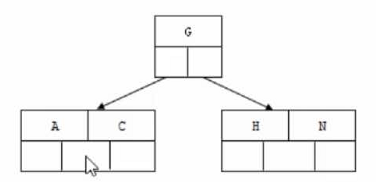
# 步骤三 # 插入E K Q 不需要分裂
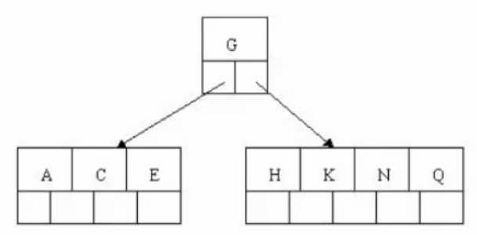
# 步骤四 # 插入M,中间元素M字母向上分裂到父节点G
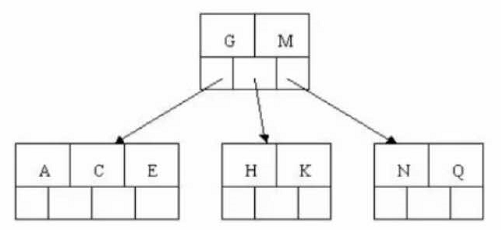
# 步骤五 # 插入F W L T ,不需要分裂
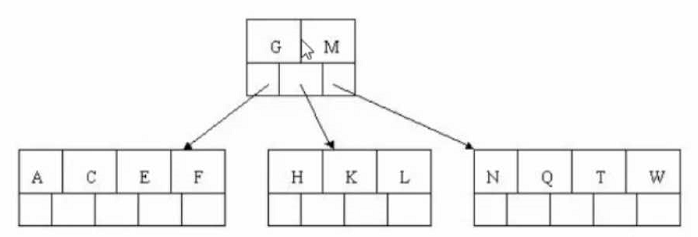
# 步骤六
# 插入Z,中间元素T向上分裂到父节点中
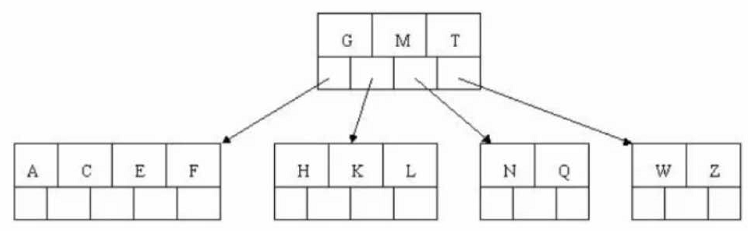
# 步骤七 # 插入D,中间元素向上分裂到父节点中。然后插入P R X Y 不需要分裂

# 步骤八 # 最后插入S,NPQR节点n>5,中间节点向上分裂,当分裂后父节点DGMT的n>5,中间节点M向上分裂。
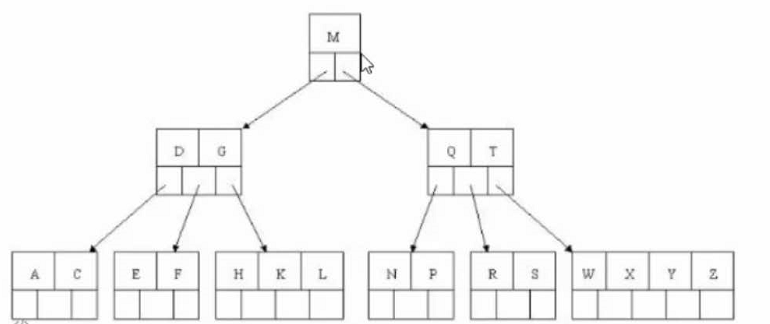
# 到此,该BTREE树就已经构建完成了,BTREE树喝二叉树相比,查询数据的效率更高,因为对于相同的数据量来说,BTREE的层级结构比二叉树小,因此搜索速度快。
3.2 B+Tree索引介绍
B+Tree为BTree的变种,B+Tree与BTree的区别为:
(1)n叉B+Tree最多含有n个key,而BTree最多含有n-1个key
(2)B+Tree的叶子节点保存所有的key信息,依key大小顺序排列。
(3)所有的非叶子节点都可以看作是key的索引部分
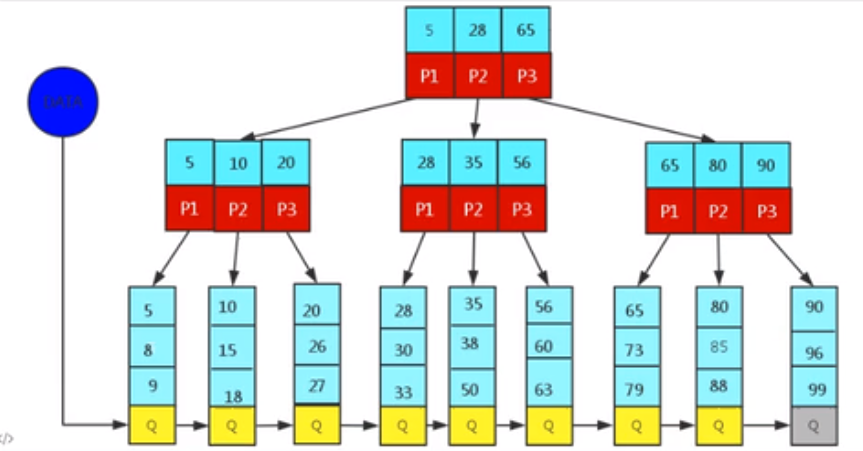
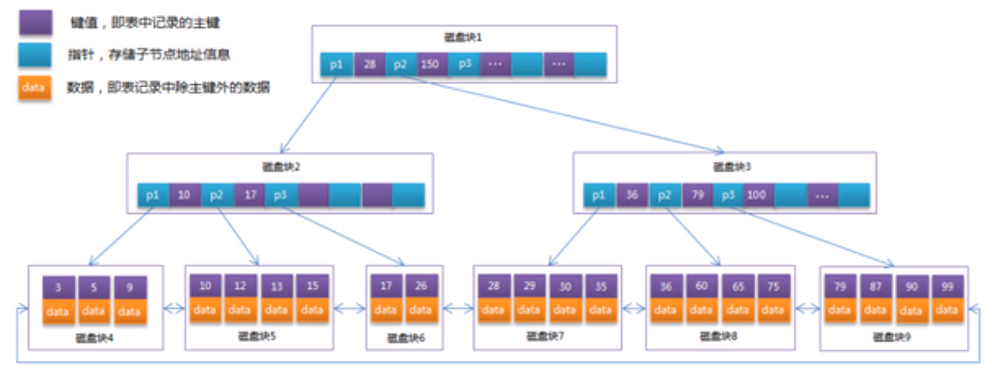
4. 索引的分类
(1)单值索引:即一个索引只包含单个列,一个表可以有多个单列索引。
(2)唯一索引:索引列的值必须唯一,但允许有空值。
(3)复合索引:即一个索引包含多个列。
5. 索引的语法
环境准备:


DROP TABLE IF EXISTS `city`; CREATE TABLE `city` ( `city_id` int(11) NOT NULL AUTO_INCREMENT, `city_name` varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, `country_id` int(11) NOT NULL, PRIMARY KEY (`city_id`) USING BTREE, UNIQUE INDEX `idx_city_name`(`city_name`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 5 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic; DROP TABLE IF EXISTS `country`; CREATE TABLE `country` ( `country_id` int(11) NOT NULL AUTO_INCREMENT, `country_name` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL, PRIMARY KEY (`country_id`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 5 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic; INSERT INTO `city` VALUES (1, '西安市', 1); INSERT INTO `city` VALUES (2, 'NewYork', 2); INSERT INTO `city` VALUES (3, '北京', 1); INSERT INTO `city` VALUES (4, '上海', 1); INSERT INTO `country` VALUES (1, 'China'); INSERT INTO `country` VALUES (2, 'America'); INSERT INTO `country` VALUES (3, 'Japan'); INSERT INTO `country` VALUES (4, 'UK');
5.1 创建索引
-- 创建普通索引 (默认Btree) create index idx_city_name on city (city_name) -- 创建普通索引 (默认Btree) alter table city add index idx_city_name(city_name) -- 创建主键索引 (该语句添加一个主键,这意味着索引值必须是唯一的,且不能是null) alter table city add primary key(id) -- 创建唯一索引 (这条语句创建索引的值必须是唯一的,除了null,null可以出现多次) alter table city add unique idx_city_name(city_name) -- 创建全文索引 alter table city add fulltext idx_city_name(city_name) -- 创建复合索引 -- 相当于对name创建了索引,对name、email创建了索引,对name、email、status创建了索引 create index idx_name_email_status on tb_seller(name,email,status)
5.2 查看索引
show index from city

5.3 删除索引
drop index idx_city_name on city
6. 索引的设计原则
索引的设计可以遵循一些已有的原则,创建索引的时候请尽量考虑符合这些原则,便于提升索引的使用效率,更高效的使用索引。
(1)对查询频次较高,且数据量比较大的表建立索引。
(2)索引字段的选择,最佳候选列应当从where子句的条件中提取,如果where子句中的组合比较多,那么应当挑选最常用、过滤效果最好的列的组合。
(3)使用唯一索引,区分度越高,使用索引的效率越高。
(4)索引可以有效地提升查询数据的效率,但索引数量不是多多益善,对于增删改等DML操作比较频繁的表来说,索引过多,维护代价的越大,降低DML操作的效率。
(5)使用短索引,索引创建之后也是使用硬盘来存储的,因此提高索引访问的I/O效率,也可以提升总体的访问效率。假如构成索引的字段总长度比较短,那么在给定大小的存储块内可以存储更多的索引值,相应的可以有效的提升MySQL访问索引的I/O效率。
(6)利用最左前缀,N个列组合而成的组合索引,那么相当于是创建了N个索引,如果查询where子句中使用了组成该索引的前几个字段,那么这条查询SQL可以利用组合索引来提升查询效率。
7. 索引的使用*
7.1 验证索引提升查询效率
这里我创建了一张表user,里面存储了一百多万条数据。下面演示有索引和没有索引对于查询效率的提升:
-- 根据主键id查 select * from user where id = '2' -- 速度很快 0.00s -- 根据name字段查 select * from user where name = '李四' -- 速度较慢 1.248s -- 为name字段创建索引并再次执行查询sql create index idx_user_name on user(name) select * from user where name = '李四' -- 速度很快 0.005s
7.2 环境准备
-- 创建表 create table tb_seller( sellerid varchar(100), name varchar(100), nickname varchar(50), password varchar(60), status varchar(1), address varchar(100), createtime datetime, primary key(sellerid) )engine=innodb default charset=utf8mb4; -- 创建复合索引 create index idx_seller_name_sta_addr on tb_seller(name,status,address); -- 添加数据 insert into tb_seller(sellerid,name,nickname,password,status,address,createtime) values ('huawei1',"华为技术有限公司1","华为小店1","c86cbf6cee7c11ea8be9f875a471a574",'0','北京朝阳1号院','2088-01-01 12:00:00'), ('huawei2',"华为技术有限公司2","华为小店2","c86cbf6cee7c11ea8be9f875a471a574",'1','北京朝阳2号院','2088-01-01 12:00:00'), ('huawei3',"华为技术有限公司3","华为小店3","c86cbf6cee7c11ea8be9f875a471a574",'2','北京朝阳3号院','2088-01-01 12:00:00'), ('huawei4',"华为技术有限公司4","华为小店4","c86cbf6cee7c11ea8be9f875a471a574",'0','北京朝阳1号院','2088-01-01 12:00:00'), ('huawei5',"华为技术有限公司5","华为小店5","c86cbf6cee7c11ea8be9f875a471a574",'1','北京朝阳1号院','2088-01-01 12:00:00'), ('huawei6',"华为技术有限公司6","华为小店6","c86cbf6cee7c11ea8be9f875a471a574",'1','北京朝阳1号院','2088-01-01 12:00:00'), ('huawei7',"华为技术有限公司7","华为小店7","c86cbf6cee7c11ea8be9f875a471a574",'2','北京朝阳1号院','2088-01-01 12:00:00'), ('huawei8',"华为技术有限公司8","华为小店8","c86cbf6cee7c11ea8be9f875a471a574",'2','北京朝阳1号院','2088-01-01 12:00:00'), ('huawei9',"华为技术有限公司9","华为小店9","c86cbf6cee7c11ea8be9f875a471a574",'0','北京朝阳1号院','2088-01-01 12:00:00'), ('huawei10',"华为技术有限公司10","华为小店10","c86cbf6cee7c11ea8be9f875a471a574",'0','北京朝阳1号院','2088-01-01 12:00:00'), ('huawei11',"华为技术有限公司11","华为小店11","c86cbf6cee7c11ea8be9f875a471a574",'0','北京朝阳1号院','2088-01-01 12:00:00'), ('huawei12',"华为技术有限公司12","华为小店12","c86cbf6cee7c11ea8be9f875a471a574",'0','北京朝阳1号院','2088-01-01 12:00:00')
7.3 避免索引失效
7.3.1 全值匹配
对索引中所有列都指定具体值
-- 走索引 explain select * from tb_seller where name='华为技术有限公司1' and status='0' and address='北京朝阳1号院'; -- 和顺序无关 explain select * from tb_seller where name='华为技术有限公司1' and address='北京朝阳1号院' and status='0' ;

7.3.2 最左前缀法则
create index idx_seller_name_sta_addr on tb_seller(name,status,address);
-- 不走索引 explain select * from tb_seller where status='0' and address='北京朝阳1号院'; -- 不走索引 explain select * from tb_seller where address='北京朝阳1号院'; -- 走索引 两个字段的索引 explain select * from tb_seller where name='华为技术有限公司1' and status='0'; -- 走索引 只走一个字段name字段的索引 explain select * from tb_seller where name='华为技术有限公司1' and address='北京朝阳1号院';




7.3.3 范围查询
范围查询,右边的列不使用索引
-- 下面两个语句 修改status = '0' --> status > '0' -- 可以看到虽然也是走了索引,但是索引的长度有了变化,即后面的address没有走索引 explain select * from tb_seller where name='华为技术有限公司1' and status = '0' and address='北京朝阳1号院'; explain select * from tb_seller where name='华为技术有限公司1' and status > '0' and address='北京朝阳1号院';
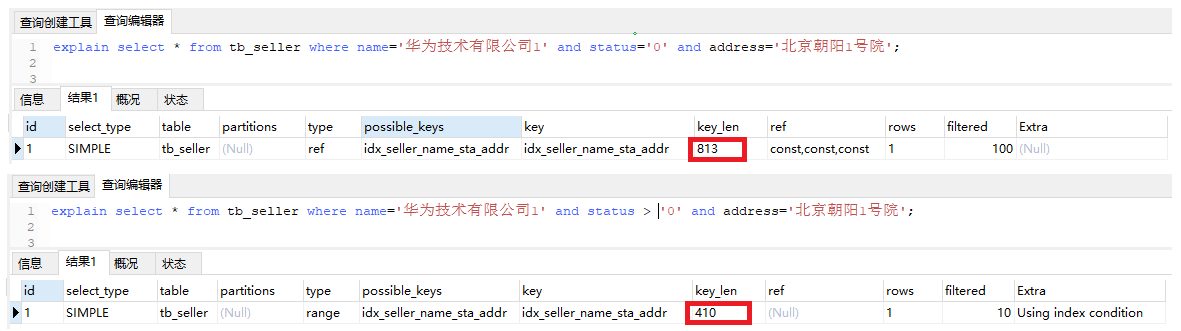
7.3.4 索引上运算操作
索引上运算操作,索引将失效
-- 走索引 最左前缀法则 explain select * from tb_seller where name='华为技术有限公司1' -- 不走索引 因为索引字段上进行了运算操作 explain select * from tb_seller where substring(name,3,2) = '技术'
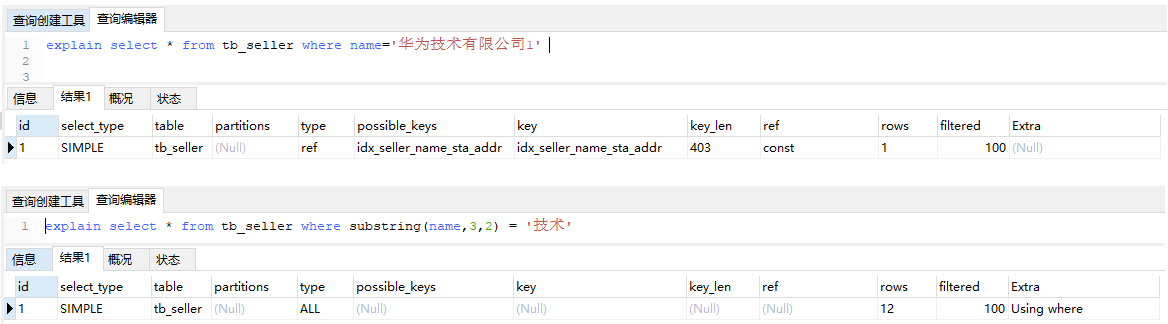
7.3.5 字符串不加单引号
字符串不加单引号,索引失效
-- name、status都走索引 explain select * from tb_seller where name = '华为技术有限公司1' and status = '0' -- name走索引 explain select * from tb_seller where name = '华为技术有限公司1' and status = 0

7.3.6 select *
尽量使用覆盖索引,即只访问索引的查询(索引列完全包括查询列),减少select *
这里先介绍一下Extra:
(1)using index:使用覆盖索引的时候就会出现
(2)using where:在查找使用索引的情况下,需要回表去查询所需的数据
(3)using index condition:查找使用了索引,但是需要回表查询数据
(4)using index;using where:查找使用了索引,但是需要的数据都在索引列中能找到,所以不需要回表查询
-- Using index condition explain select * from tb_seller where name = '华为技术有限公司1' and status = 0 -- Using where; Using index explain select name,status,address from tb_seller where name = '华为技术有限公司1' and status = 0 -- Using where; Using index explain select name,status from tb_seller where name = '华为技术有限公司1' and status = 0 -- Using index condition explain select name,password from tb_seller where name = '华为技术有限公司1' and status = 0

7.3.7 or
explain select * from tb_seller where name = '华为技术有限公司1' or nickname = '华为小店10'

7.3.8 like
-- 索引失效 explain select * from tb_seller where name like '%华为技术有限公司1' -- 索引失效 explain select * from tb_seller where name like '%华为技术有限公司1%' -- 索引不失效 explain select * from tb_seller where name like '华为技术有限公司1%' -- 索引不失效 因为查询的三个字段都是索引字段 explain select name,status,address from tb_seller where name like '华为技术有限公司1%' -- 索引不失效 虽然password不是索引字段,但是因为%在后面 explain select name,status,password from tb_seller where name like '华为技术有限公司1%' -- 索引失效 explain select name,status,password from tb_seller where name like '%华为技术有限公司1%'
7.3.9 索引速度<全表
如果mysql评估使用索引比全表更慢,则不使用索引
-- 不走索引 因为不符合复合索引的最左前缀法则 explain select * from tb_seller where address = '北京朝阳1号院' -- 为address再单独创建一个索引 create index idx_address on tb_seller(address) -- 仍然不走索引 是因为数据库中12条数据中有10条数据结果是 北京朝阳1号院 mysql认为使用索引没有全表快 explain select * from tb_seller where address = '北京朝阳1号院' -- 走索引 因为数据库中12条数据中只有1条数据结果是 北京朝阳2号院 explain select * from tb_seller where address = '北京朝阳2号院'
7.3.10 is null / is not null
is null ,is not null 有时索引失效
(1)is null:null值比较少,走索引
(2)is not null:null值比较多,走索引
-- 走索引 因为表中数据address字段大部分(全部)都是非空的 explain select * from tb_seller where address is null -- 不走索引 因为表中数据address字段大部分(全部)都是非空的,走索引没有全表扫描快 explain select * from tb_seller where address is not null
7.3.11 in / not in
尽量使用复合索引,少使用单列索引
(1)拿上面的seller表来说,创建的复合索引相当于创建了三个索引
(2)如果对上面三个字段分别创建索引,那么在搜索值得时候,数据库只会选择其中一个最优得作为索引,并不会使用全部索引。这里得最优可以理解成此字段值大部分都不同,即辨识度最高
7.4 查看索引使用情况
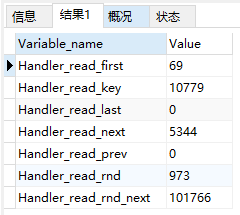
(1)Handler_read_first:索引中第一条被读的次数。如果较高,表示服务器正执行大量全索引扫描(值越低越好)
(2)Handler_read_key:如果索引正在工作,这个值代表一个行被索引值读的次数,如果值越低,表示索引得到的性能改善不高,因为索引不经常使用(值越高越好)
(3)Handler_read_last:
(4)Handler_read_next:按照键顺序读下一行的请求数。如果你用范围约束或如果执行索引扫描来查询索引列,该值增加。
(5)Handler_read_prev:按照键顺序读前一行的请求数。该读方法主要用于优化order by ... desc。
(6)Handler_read_rnd:根据固定位置读一行的请求数,如果你正执行大量查询并需要对结果进行排序该值较高。你可能使用了大量需要mysql扫描整个表的查询或你的连接没有正确使用键。这个值较高,意味着运行效率低,应该建立索引来补救。
(7)Handler_read_rnd_next:在数据文件中读下一行的请求数。如果你正进行大量的表扫描,该值较高。通常说明你的表索引不正确或写入的查询没有利用索引。
-- 查看当前会话的索引使用情况 show status like 'Handler_read%' -- 查看全局的索引使用情况 全局的如下图: show global status like 'Handler_read%'
持续更新!!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号