Boost Mutex详细解说
博客参考:HappenLee
1. C++多线程编程的困扰
C++从11开始在标准库之中引入了线程库来进行多线程编程,在之前的版本需要依托操作系统本身提供的线程库来进行多线程的编程。(其实本身就是在标准库之上对底层的操作系统多线程API统一进行了封装,使用的pthread或<windows.h>来进行多线程编程的)
提供了统一的多线程固然是好事,但是标准库给的支持实在是有限,具体实践起来还是让人挺困扰的:
- C++本身的STL并不是线程安全的。所以缺少了类似与Java并发库所提供的一些高性能的线程安全的数据结构。(Doug Lea大神亲自操刀完成的并发编程库,让JDK5成为Java之中里程碑式的版本)
- 如果没有线程安全的数据结构,退而求其次,可以自己利用互斥量Mutex来实现。C++的标准库支持如下的互斥量的实现:
| 互斥量 | 版本 | 作用 |
|---|---|---|
| mutex | C++11 | 最基本的互斥量 |
| timed_mutex | C++11 | 有超时机制的互斥量 |
| timed_mutex | C++11 | 有超时机制的互斥量 |
| recursive_mutex | C++11 | 可重入的互斥量 |
| recursive_timed_mutex | C++11 | 结合 2,3 特点的互斥量 |
| shared_timed_mutex | C++14 | 具有超时机制的可共享互斥量 |
| shared_mutex | C++17 | 共享的互斥量 |
| 由上述表格可见,C++是从14之后的版本才正式支持共享互斥量,也就是实现读写锁的结构。如果当前仅支持C++11的版本,所就没有办法使用共享互斥量来实现读写锁了。所以只能使用boost的库,利用boost提供的读写锁来完成所需完成的工作。 |
2.标准库互斥量的剖析
mutex
mutex的中文翻译就是互斥量,很多人喜欢称之其为锁。其实不是太准确,因为多线程编程本质上应该通过互斥量之上加锁,解锁的操作,来实现多线程并发执行时对互斥资源线程安全的访问。 我们来看看mutex类的使用方法:
long num = 0;
std::mutex num_mutex;
void numplus() {
num_mutex.lock();
for (long i = 0; i < 1000000; ++i) {
num++;
}
num_mutex.unlock();
};
void numsub() {
num_mutex.lock();
for (long i = 0; i < 1000000; ++i) {
num--;
}
num_mutex.unlock();
}
int main() {
std::thread t1(numplus);
std::thread t2(numsub);
t1.join();
t2.join();
std::cout << num << std::endl;
}
调用线程从成功调用lock()或try_lock()开始,到unlock()为止占有mutex对象。当存在某线程占有mutex时,所有其他线程若调用lock则会阻塞,而调用try_lock会得到false返回值。由上述代码可以看到,通过mutex加锁的方式,来确保只有单一线程对临界区的资源进行操作。
time_mutex与recursive_mutex的使用也是大同小异,两者都是基于mutex来实现的。( 本质上是基于recursive_mutex实现的,mutex为recursive_mutex的特例)
time_mutex则是进行加锁时可以设置阻塞的时间,若超过对应时长,则返回false。
recursive_mutex则让单一线程可以多次对同一互斥量加锁,同样,解锁时也需要释放相同多次的锁。
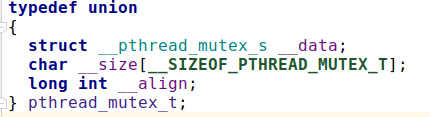
以上三种类型的互斥量都是包装了操作系统底层的pthread_mutex_t:
在C++之中并不提倡我们直接对锁进行操作,因为在lock之后忘记调用unlock很容易造成死锁。而对临界资源进行操作时,可能会抛出异常,程序也有可能break,return 甚至 goto,这些情况都极容易导致unlock没有被调用。所以C++之中通过RAII来解决这个问题,它提供了一系列的通用管理互斥量的类:
| 互斥量管理 | 版本 | 作用 |
|---|---|---|
| lock_graud | C++11 | 基于作用域的互斥量管理 |
| unique_lock | C++11 | 更加灵活的互斥量管理 |
| shared_lock | C++14 | 共享互斥量的管理 |
| scope_lock | C++17 | 多互斥量避免死锁的管理 |
创建互斥量管理对象时,它试图给给定mutex加锁。当程序离开互斥量管理对象的作用域时,互斥量管理对象会析构并且并释放mutex。所以我们则不需要担心程序跳出或产生异常引发的死锁了。
对于需要加锁的代码段,可以通过{}括起来形成一个作用域。比如上述代码的栗子,可以进行如下改写(推荐):
long num = 0;
std::mutex num_mutex;
void numplus() {
std::lock_guard<std::mutex> lock_guard(num_mutex);
for (long i = 0; i < 1000000; ++i) {
num++;
}
};
void numsub() {
std::lock_guard<std::mutex> lock_guard(num_mutex);
for (long i = 0; i < 1000000; ++i) {
num--;
}
}
int main() {
std::thread t1(numplus);
std::thread t2(numsub);
t1.join();
t2.join();
std::cout << num << std::endl;
}
由上述代码可以看到,代码结构变得更加明晰了,对于锁的管理也交给了程序本身来进行处理,减少了出错的可能。
shared_mutex
C++14的版本之后提供了共享互斥量,它的区别就在于提供更加细粒度的加锁操作:lock_shared。lock_shared是一个获取共享锁的操作,而lock是一个获取排他锁的操作,通过这种方式更加细粒度化锁的操作。shared_mutex也是基于操作系统底层的读写锁pthread_rwlock_t的封装:

这里有个事情挺奇怪的,C++14提供了shared_timed_mutex 而在C++17提供了shared_mutex。其实shared_timed_mutex涵盖了shard_mutex的功能。(不知道是不是因为名字被diss了,所以后续在C++17里将shared_mutex**加了回来)。共享互斥量适用与读多写少的场景,举个栗子:
long num = 0;
std::shared_mutex num_mutex;
// 仅有单个线程可以写num的值。
void numplus() {
std::unique_lock<std::shared_mutex> lock_guard(num_mutex);
for (long i = 0; i < 1000000; ++i) {
num++;
}
};
// 多个线程同时读num的值。
long numprint() {
std::shared_lock<std::shared_mutex> lock_guard(num_mutex);
return num;
}
简单来说:
- shared_lock是读锁。被锁后仍允许其他线程执行同样被shared_lock的代码
- unique_lock是写锁。被锁后不允许其他线程执行被shared_lock或unique_lock的代码。它可以同时限制unique_lock与share_lock
#include <iostream>
#include "boost/thread/mutex.hpp"
#include "boost/thread/thread.hpp"
typedef boost::shared_lock<boost::shared_mutex> readLock;
typedef boost::unique_lock<boost::shared_mutex> writeLock;
boost::shared_mutex rwmutex;
std::vector<int> shared_vec = { 1, 2, 3, 4, 5, 6 };
int pause = 0;
void wait(int milliseconds)
{
boost::this_thread::sleep(boost::posix_time::milliseconds(milliseconds));
}
void readThread1()
{
while (true)
{
wait(100);
if (pause)
{
continue;
}
readLock rdlock(rwmutex);
printf("rthread 1: vec[1]: %d\n", shared_vec[1]);
}
}
void readThread2()
{
while (true)
{
wait(100);
if (pause)
{
continue;
}
readLock rdlock(rwmutex);
printf("rthread 2: vec[2]: %d\n", shared_vec[2]);
}
}
void writeThread()
{
int count = 1;
while (true)
{
count++;
wait(500);
if (pause)
{
continue;
}
writeLock wdlock(rwmutex);
shared_vec[1] = count;
shared_vec[2] = count + 1;
printf("wthread 2: vec[1] and vec[2]: %d %d\n", shared_vec[1], shared_vec[2]);
if (count >= 100)
{
count = 0;
}
}
}
int main()
{
boost::thread t1(readThread1);
wait(20);
boost::thread t2(readThread2);
wait(20);
boost::thread t3(writeThread);
while (true)
{
char c = getchar();
if (c == 's')
{
pause = 1;
}
else if (c == 'r')
{
pause = 0;
}
else if (c == 'q')
{
break;
}
wait(500);
}
return 0;
}
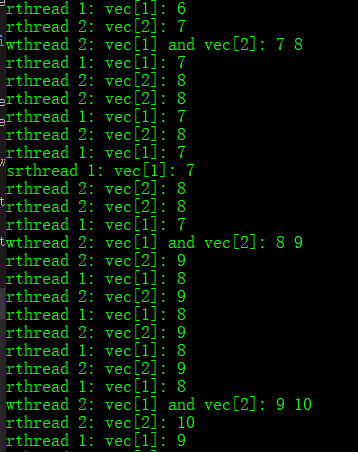
不得不说,C++11没有将共享互斥量集成进来,在很多读多写少的应用场合之中,标准库本身提供的锁机制显得很鸡肋,也从而导致了笔者最终只能求助与boost的解决方案。
多锁竞争
还剩下最后一个要写的内容:scope_lock ,当我们要进行多个锁管理时,很容易出现问题,由于加锁的先后顺序不同导致死锁。(其实本来不想写了,好累。这里就简单用例子做解释吧,偷个懒~~)
如下栗子,加锁顺序不当导致死锁:
std::mutex m1, m2;
// thread 1
{
std::lock_guard<std::mutex> lock1(m1);
std::lock_guard<std::mutex> lock2(m2);
}
// thread 2
{
std::lock_guard<std::mutex> lock2(m2);
std::lock_guard<std::mutex> lock1(m1);
}
而通过C++17提供的scope_lock就可以很简单解决这个问题了:
std::mutex m1, m2;
// thread 1
{
std::scope_lock lock(m1, m2);
}
// thread 2
{
std::scope_lock lock(m1, m2);
}
boost::timed_mutex
#include <iostream>
#include "boost/thread/mutex.hpp"
#include "boost/thread/thread.hpp"
#include "ComUtils/TimeStampAbs.h"
void wait(int seconds)
{
boost::this_thread::sleep(boost::posix_time::seconds(seconds));
}
boost::timed_mutex mutex;
void timed_mutex_func1()
{
for (int i = 0; i < 5; ++i)
{
double t1 = TimeStampAbs::getTimeStamp(TIME_STAMP_TYPE::ABS_TIME_STAMP);
boost::unique_lock<boost::timed_mutex> lock(mutex, boost::get_system_time() + boost::posix_time::milliseconds(100));
if (!lock.owns_lock())
{
printf("thread 1 owns_lock failed\n");
continue;
}
else
{
printf("thread 1 owns_lock success\n");
double t2 = TimeStampAbs::getTimeStamp(TIME_STAMP_TYPE::ABS_TIME_STAMP);
printf("thread 1 dt: %lf %lf %lf\n", t1, t2, t2 - t1);
}
wait(1);
std::cout << "Thread 1 " << boost::this_thread::get_id() << ": " << i <<std::endl;
}
}
void timed_mutex_func2()
{
for (int i = 0; i < 5; ++i)
{
double t1 = TimeStampAbs::getTimeStamp(TIME_STAMP_TYPE::ABS_TIME_STAMP);
boost::unique_lock<boost::timed_mutex> lock(mutex, boost::get_system_time() + boost::posix_time::milliseconds(1500));
if (!lock.owns_lock())
{
printf("thread 2 owns_lock failed\n");
continue;
}
else
{
printf("thread 2 owns_lock success\n");
double t2 = TimeStampAbs::getTimeStamp(TIME_STAMP_TYPE::ABS_TIME_STAMP);
printf("thread 2 dt: %lf %lf %lf\n", t1, t2, t2 - t1);
}
boost::thread::sleep(boost::get_system_time() + boost::posix_time::milliseconds(40));
std::cout << "Thread 2 " << boost::this_thread::get_id() << ": " << i << std::endl;
}
}
int main()
{
boost::thread t(timed_mutex_func1);
boost::thread t2(timed_mutex_func2);
getchar();
return 0;
}
简单来说boost::timed_mutex就是进行加锁时可以设置阻塞的时间,若超过对应时长,则返回false;如上述线程1最长等待时间 100ms, 线程2最长等待时间是 1500ms;
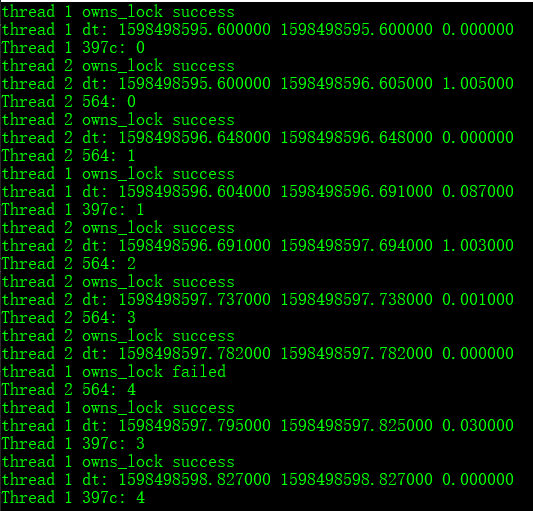
此案例细节可参考:How to correctly use boost::timed_mutex and scoped_lock

 浙公网安备 33010602011771号
浙公网安备 33010602011771号