海量大数据分布式数据库解决方案思路
前言
随着互联网的发展,分布式技术的逐渐成熟,动态水平扩展和自动容灾备份、一键部署等技术方案不断成熟,各大中小互联网企业都在尝试切换将产品的技术方案到分布式的方案,但是分布式的技术方案有一个业内比较难以解决的问题,就是分布式事务的处理,大部分都是将业务尽量限制在同库中,避免跨库事务,或者采用消息队列处理分布式事务,或者采用DTC来处理,但是性能都不是太理想。在阅读关于淘宝数据库OceanBase的一些文章时受到启发,想到一个不成熟的方案,也可以说是对OceanBase的一些思路的总结,在这里写出来给大家分享一下,也欢迎指出其中不合理或可改善的地方。
使用场景
1.海量数据;
2.读取压力大而更新操作的场景少;
3.保障高可用,最终一致性;
架构图
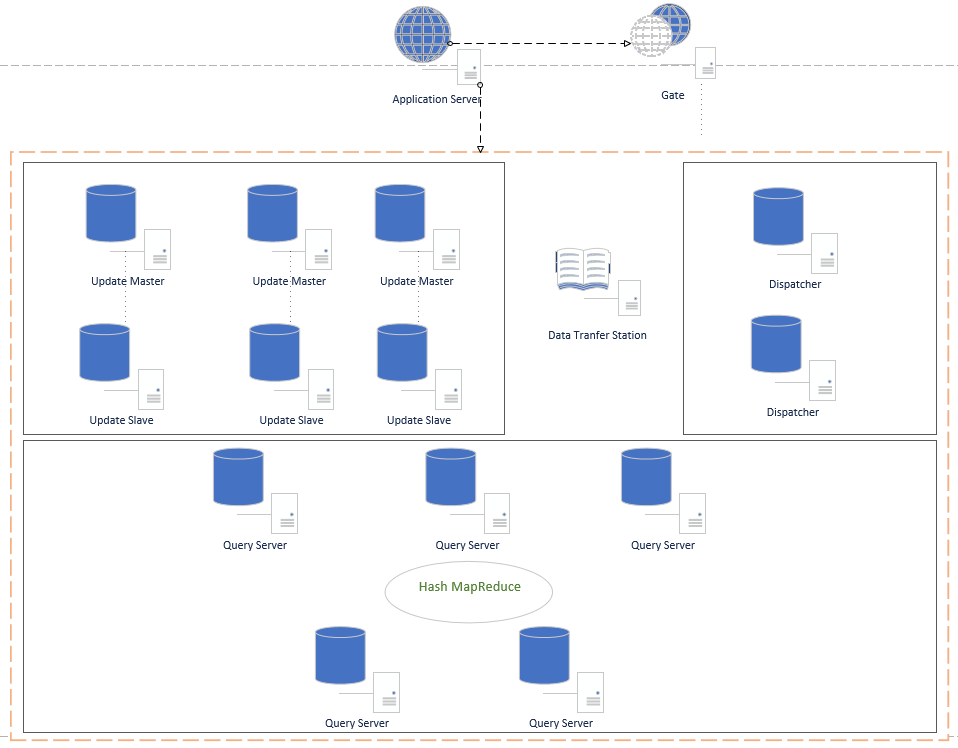
节点功能
1. Application Server 应用服务器,这里只画了一台,实际生产环境中可能是几百上千个Host的服务,主要是业务服务;
2.Gate Gate中保持着数据中心各个功能节点的状态信息,Application Server从Gate中获取到需要操作的主机地址,然后再与数据中心指定的节点进行通信;Gate中保留的节点信息会记录节点的路由ip和端口,节点的状态,另外记录节点的功能特点;Gate中会开一个守护进程负责与数据中心的各个节点进行通信(每个节点也有专门负责通信的守护进程),节点的可用状态通过心跳检测(节点是否拓机),节点是否处于busy状态由节点自己汇报到Gate守护进程,Gate守护进程再更新配置信息;
3.Update Master 负责数据库的更新操作,该节点并不保存所有数据,只是在需要更新时,将需要的数据从对应的查询库中获取到数据,然后在本机做事务更新,完成后,也是提交到本机。并通过某种机制(定时器或达到某个阈值),就备份本机数据,并提交到Data Transfer Station,提交成功后,清空本地数据库。这里的难点是如果知道需要获取哪些数据,我的初步思路是,由应用服务自己告诉该节点,这是最简单的方式;
4.Update Slave:备用的Update服务器,当Master拓机时自动成为Master代替UpdateMaster的工作。守护进程实时监控Master状态;
5.Data Transfer Station 数据中转中心,负责收集变更数据,并备份存储,以防需要跟踪或恢复数据等。在Update Master提交备份数据后,查找空闲的Dispatcher,再由Dispatcher拉去需要的数据,分发同步到Query Server中;
6.Dispatcher 数据分发器,分发器从Data Transfer Station获取到数据,并从Gate中获取空闲的、未同步过该数据的Query Server,并将该Query Server标记为同步数据中,然后同步数据,同步完成后,将同步日志记录,返回给Data Transfer Station,接着继续下一个Query Server进行同步,直到所有都同步完成。完成后,Data Transfer Station将该份数据标记为所有节点已同步(同步过程中Query Server还是可以提供查询服务);
7.Query Server 查询服务器,负责对外的数据查询。这里有一点还在考虑中,就是是否采用分片,因为数据量大,不分片肯定会导致单机的查询效率下降,分片的话,如采用Hash算法计算分片,会增加查询的复杂度,最主要是,数据下发时,需要考虑该更新的数据是在哪个分片上,相对会比较复杂;
查询数据请求流程图(未使用Hash MapReduce,如果使用,则需要在过程中添加Hash计算数据所在的节点)

更新数据请求流程图
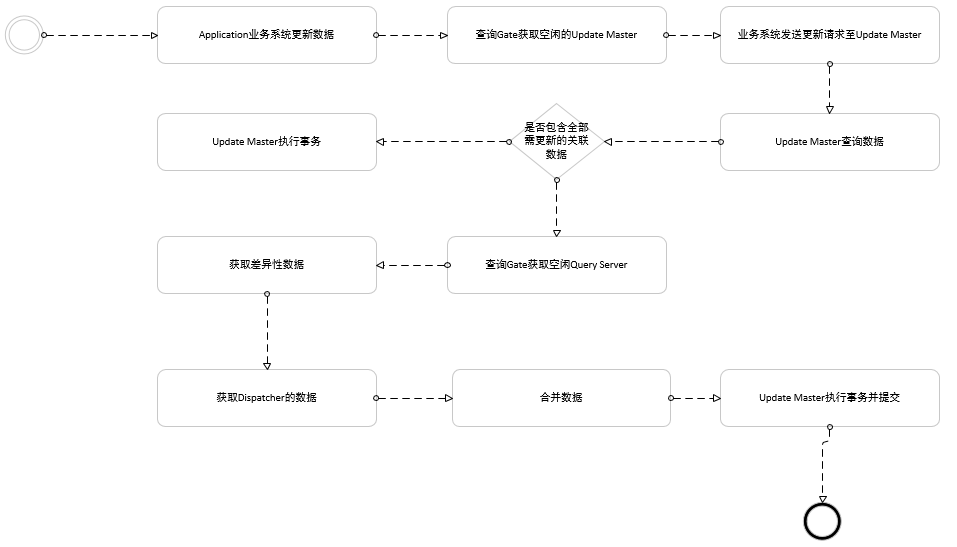
这里获取更新数据时,应该是全量的,即Update Master里的数据+Query Server的数据+Dispatcher未分发完成的数据;举例来说,假设查询到的某个账户余额100,000元,需要做一个转账业务,需要转出10000元,并且之前已经做过一次转账5000元,但是这笔5000元的转账还未同步到查询服务器中,那么该次转账应该是100,000元减去5,000元,然后再去做转出10,000元的操作。最终账户余额应该是85,000元。另外,如果查询要做到强一致性,也应该这样做一个差异性数据合并,再转发给业务服务,这样就能做到信息的一致性和实时性。
以上仅提供一种思路,实现可结合自己的业务,对该解决方案做一些更改,具体选取技术。具体细节也考虑不是很周全,如有思路上的错误,请多指教。
本文原创,如有转载,请注明出处。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号