Redis 基础知识
数据类型
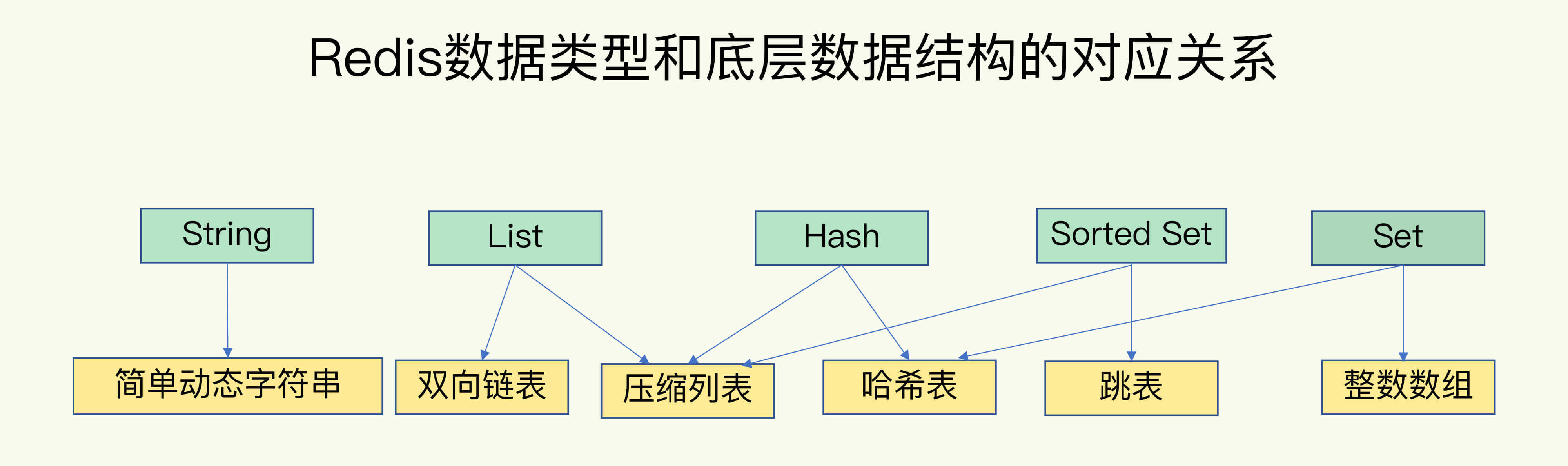
常用的包括**String、List、Hash、Set、Sorted Set**,不常用的包含GEO、Bitmap、HyperLogLog;底层数据结构包括简单字符串,双向链表,数组,压缩数组,哈希表,跳表;数据类型跟数据结构的对应关系为下图所示;
hash算法
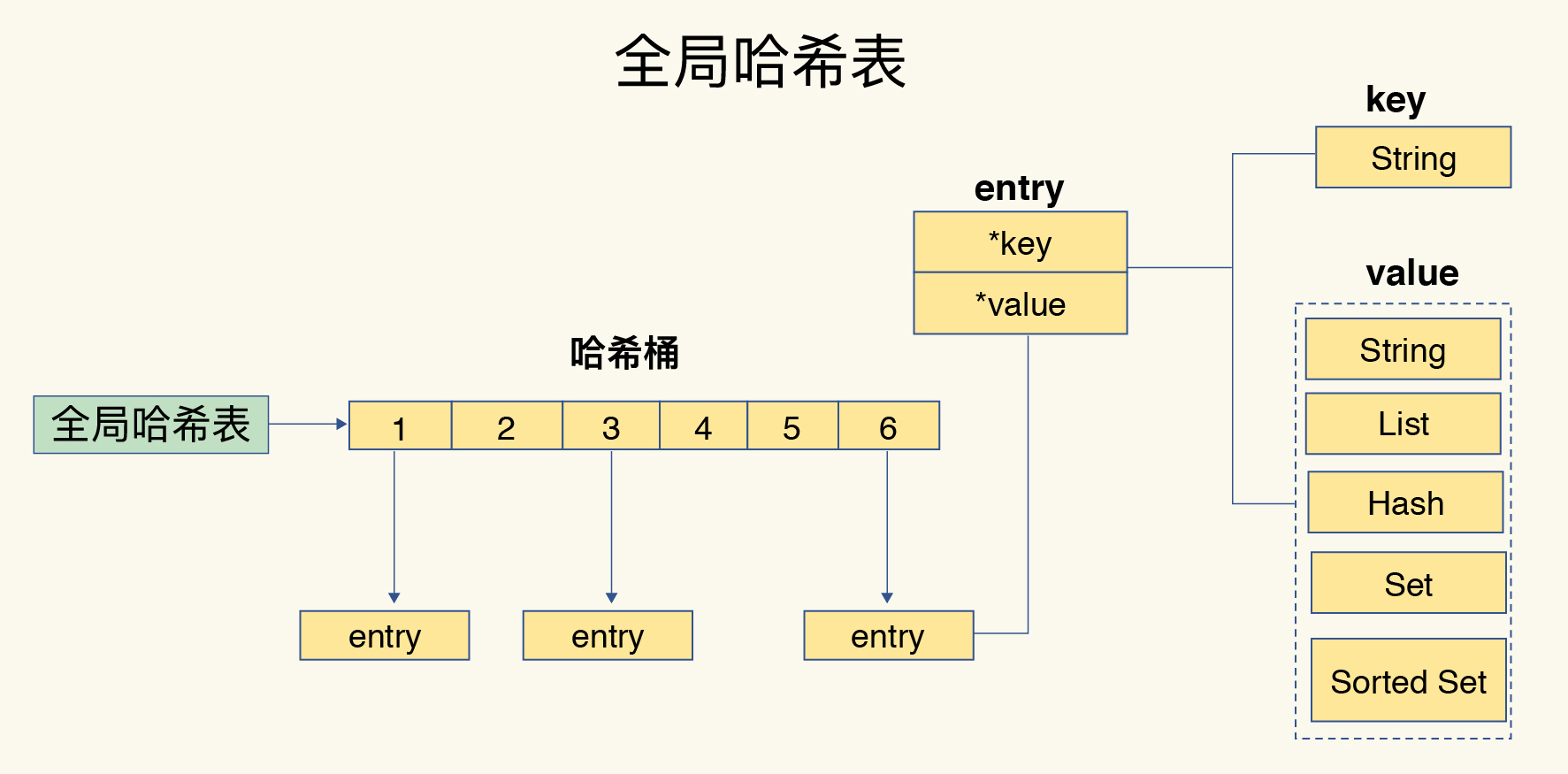
- 一个哈希表就是一个数组,数组中的每个元素称为一个哈希桶(Bucket);
- 采用hash算法进行键值对的存储;
- 一个键值对对应一个entry,entry里包含键和 值的指针,并不存储实际的值;如下图所示:
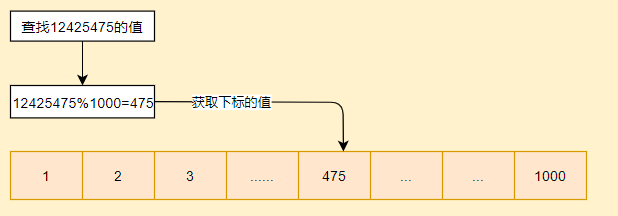
- 查找值时,先通过键的值计算出hash值,再通过hash值以哈希表数组的长度取模,就能得到查找的键的entry对应的下标;例如,假设hash表数组的长度是1000,那么在查找键key所在的位置时,只需要计算key值的hash值,假设为12425475,那么,key值所在的位置的下表即为12425475%1000=475,可直接通过下表获取到key对应的entry。
hash冲突与渐进式rehash
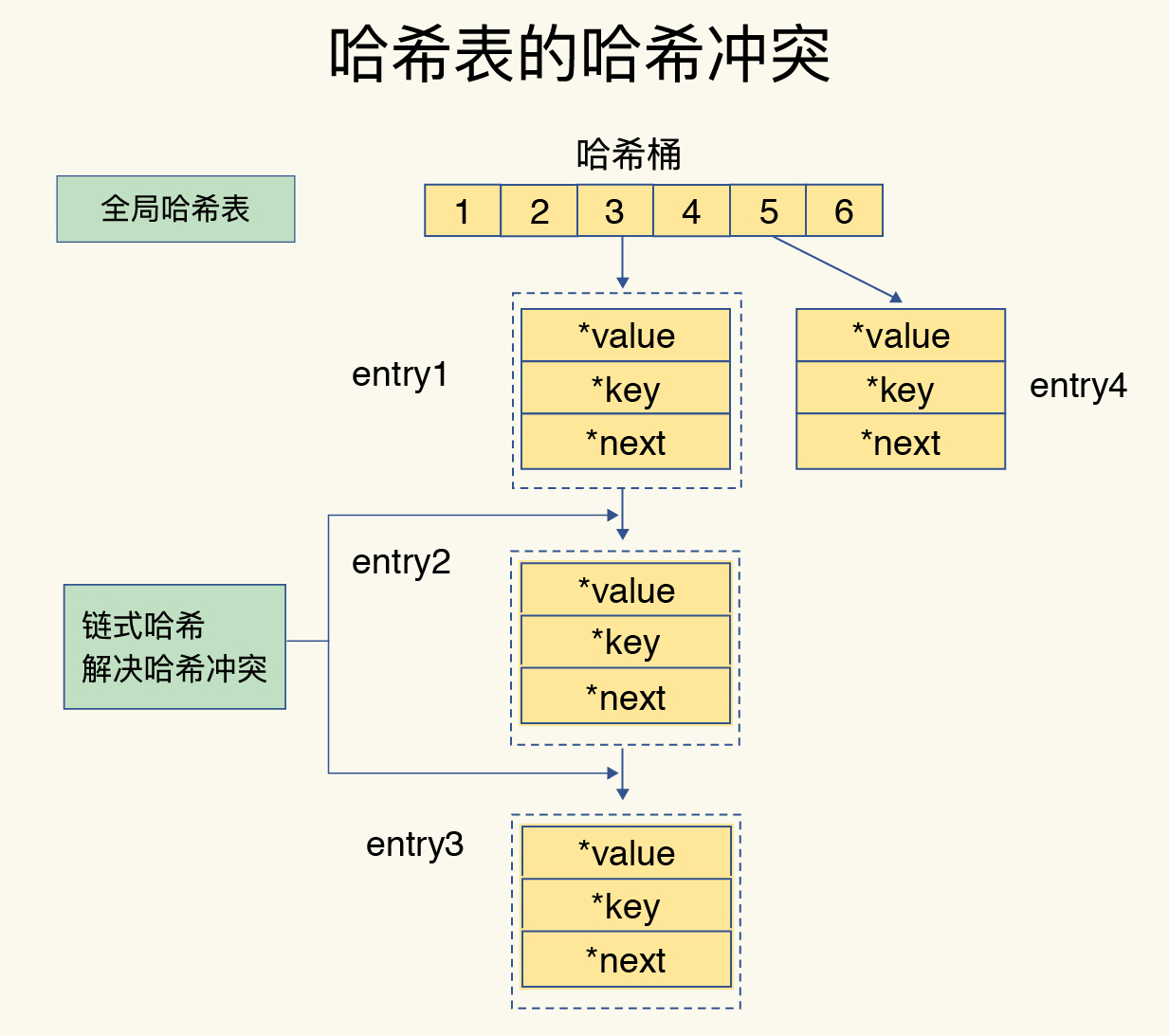
- 什么是hash冲突?
hash表数组长度是固定的,当使用hash算法当存储的数据量远远大于hash表的数组长度时,就必定会有键计算出来的数组下标相同。假设hash表数组长度为10,key1的hash值为15,key2的hash值为25,那么他们与10取模后都是5,即key1和key2都要存储在下标为5的地方,这就是hash冲突。
- 如何解决hash冲突?
当发生hash冲突时,redis采用单向链表的方式存储hash值,即在entry中增加next指针,指向下一个元素,比如上面的情况,key1已经存储在了5的位置,那么key2存储时,会更新key1的next指针,指向key2。同样是以上情况,如果key1和key2已经存储了,需要查找key2的值,则通过hash取模后得到的位置是5,再进行对比key1的值,如果不等于key2,那么就通过key1的next指针,继续对比下一个,直到找到为止。具体的数据结构图下图所示。
- 以上解决办法带来的问题?
从上面的情况我们可以得知,当hash冲突时,需要通过链表一个个对比才能查找到我们想要的key。如果是比较极端的情况,在某个hash桶位置的冲突键太多,就容易导致查找效率低下,这就是hash冲突带来的问题。
- 如何解决?
redis通过渐进式rehash来解决以上带来的问题的。rehash操作就是增加现有桶的数量,让逐渐增多的entry元素在更多的桶之间分散保存,从而减少单个桶的冲突。我们可以先看一下redis存储的一些源码:
typedef struct dictEntry { void *key; //键 union { void *val; //值 uint64_t u64; int64_t s64; double d; } v; struct dictEntry *next; //指向下一个节点,形成链表 } dictEntry; typedef struct dictht { dictEntry **table; //哈希表数组,数组的每个项是dictEntry链表的头结点指针 unsigned long size; //哈希表大小;在redis的实现中,size也是触发扩容的阈值 unsigned long sizemask;//哈希表大小掩码,用于计算索引值;总是等于 size-1 unsigned long used;//哈希表中保存的节点的数量 } dictht; typedef struct dict { dictType *type; void *privdata; dictht ht[2];//在字典内部,维护了两张哈希表。 一般情况下, 字典只使用 ht[0] 哈希表, ht[1] 哈希表只会在对 ht[0] 哈希表进行 rehash 时使用 long rehashidx; /* rehashing not in progress if rehashidx == -1 */ unsigned long iterators; /* number of iterators currently running */ } dict;
触发条件
1. 存储元素与hash表长度的比例大于某个值(负载因子);
2. 单个桶存储的元素大于某个值;
如何扩容
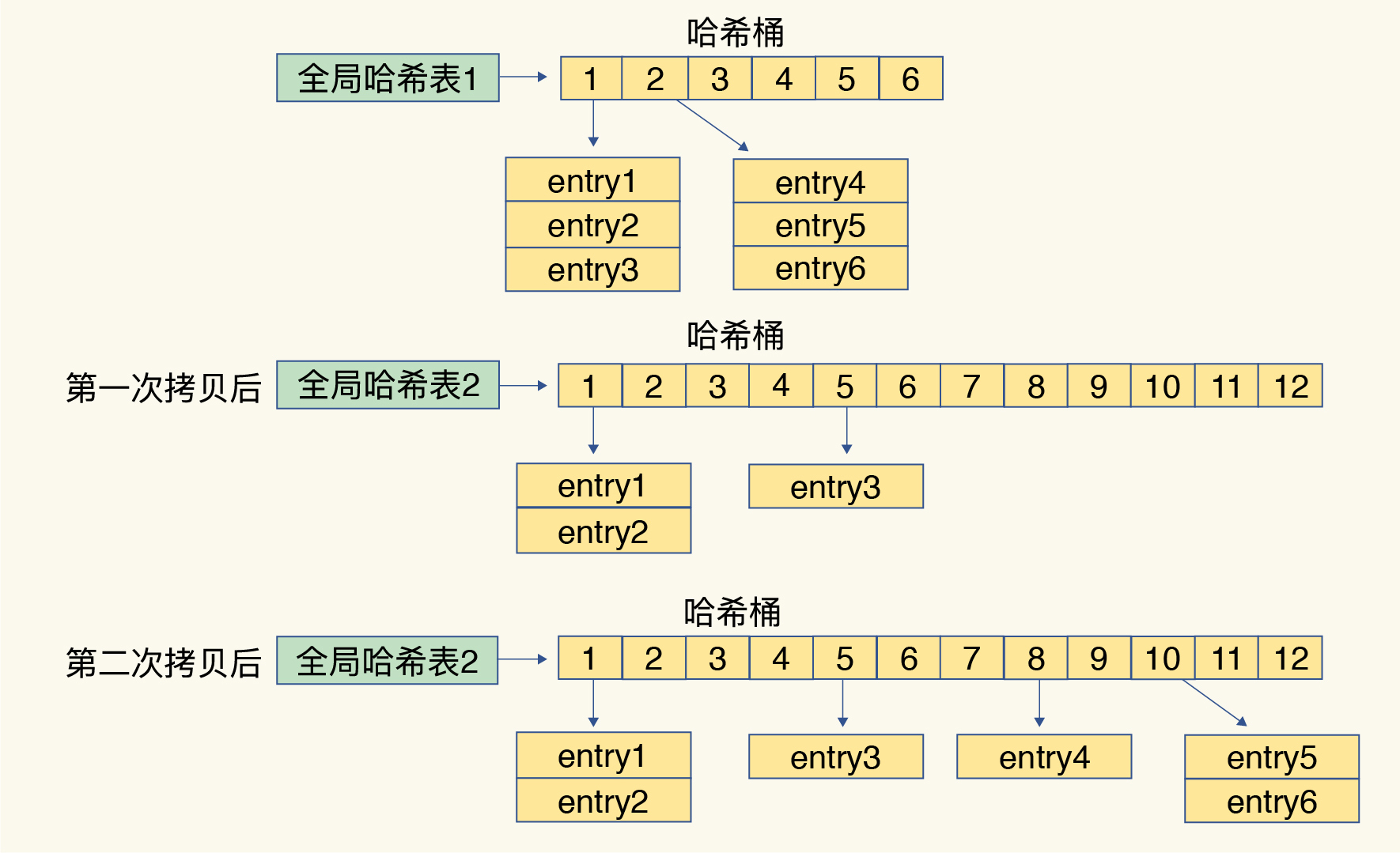
Redis 默认使用了两个全局哈希表:哈希表 1 和哈希表 2。一开始,当你刚插入数据时,默认使用哈希表 1,此时的哈希表 2 并没有被分配空间。随着数据逐步增多,Redis 开始执行 rehash,这个过程分为三步:
1. 给哈希表 2 分配更大的空间,例如是当前哈希表 1 大小的两倍;
2. 把哈希表 1 中的数据重新映射并拷贝到哈希表 2 中;
3. 释放哈希表 1 的空间。
渐进式rehash
以上扩容过程会带来一个问题,当数据量较多时,这个过程比较耗时,那么就必定会阻塞redis处理请求,所以redis采用渐进式rehash来解决这个问题,简单来说,Redis 仍然正常处理客户端请求,每处理一个请求时,从哈希表 1 中的第一个索引位置开始,顺带着将这个索引位置上的所有 entries 拷贝到哈希表 2 中;等处理下一个请求时,再顺带拷贝哈希表 1 中的下一个索引位置的 entries。如下图所示:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号