Redis底层数据结构
-
Redis 是 key-value 存储系统,其中key类型一般为字符串,而 value 类型则为 redis 对象(RedisObject)。Redis 对象可以绑定各种类型的数据,譬如 string、list 和set。因此他能很好的将属性和数据分离开。
typedef struct redisObject {
// 对象的类型
unsigned type:4;
// 编码的方式
unsigned encoding:4;
/ 对象最后一次被访问的时间
unsigned lru:22;
// 引用计数
int refcount;
// 数据指针
void *ptr;
} robj;为什么要有一个RedisObject?而不直接使用五大类型对象?
-
通过不同类型的对象,Redis 可以在执行命令之前,根据对象的类型来判断一个对象是否可以执行给定的命令。
-
我们可以针对不同的使用场景,为对象设置不同的实现,从而优化内存或查询速度。
type 对象的类型
类型常量 对象的名称 REDIS_STRING 字符串对象 REDIS_LIST 列表对象 REDIS_HASH 哈希对象 REDIS_SET 集合对象 REDIS_ZSET 有序集合对象 ptr 指针
指向实际存储的对象的指针
encoding
encoding 表示 ptr 指向的具体数据结构,即这个对象使用了什么数据结构作为底层实现。
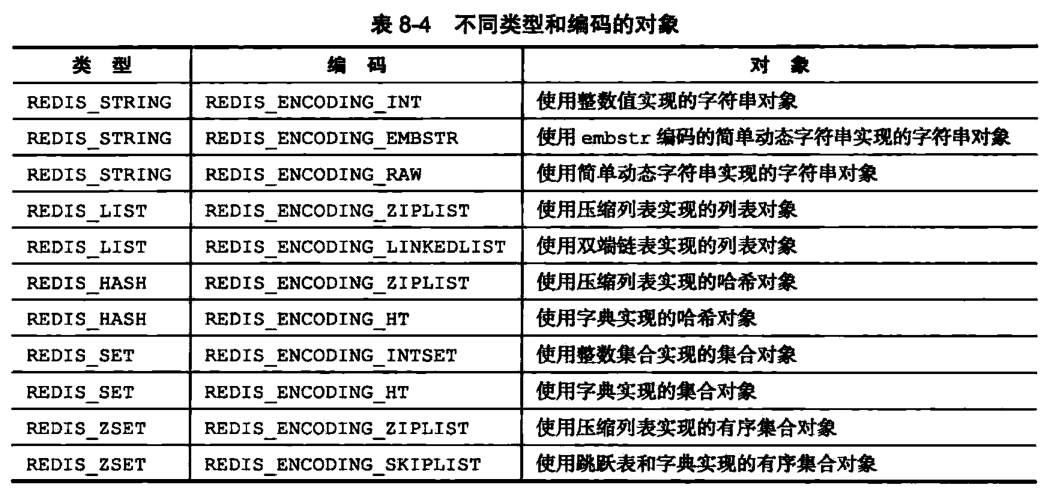
编码常量 编码所对应的底层数据结构 REDIS_ENCODING_INT long类型的整数 REDIS_ENCODING_EMBSTR enbstr编码的简单动态字符串 REDIS_ENCODING_RAW 简单动态字符串 REDIS_ENCODING_HT 字典 REDIS_ENCODING_LINKEDLIST 双向链表 REDIS_ENCODING_ZIPLIST 压缩列表 REDIS_ENCODING_INTLIST 整数集合 REDIS_ENCODING_SKIPLIST 跳表 每种类型的对象都至少使用了两种不同的编码,对象和编码的对应关系如下
![《Redis设计与实现第二版》63页]()
refcount
引用计数器,当该值为0时,表示该对象已经不再被引用了,可以释放进行内存回收。
lru
最近一次访问时间
-
-
String
String类型的encoding方式有三种,分别是int、raw、enbstr。
-
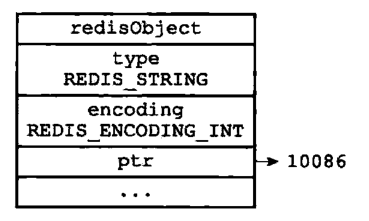
如果保存的数据是整数,且该整数是8个字节能表示的数据,那么该整数就可以直接保存在ptr中。这种方式节约内存,且可以快速读写索引。其内存结构如下:
![《Redis设计与实现第二版》64页]()
-
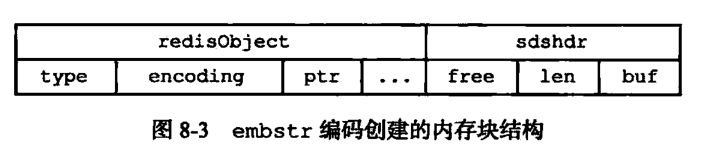
如果保存的数据是字符串,且该字符串长度小于等于32字节,那么字符串将使用enbstr的编码方式来保存数据。因为这种方式在申请内存空间时是一次申请的,所以需要分配内存空间一次,释放也只需要一次,并且所有数据保存在一块连续的内存空间内,可以减少内存碎片的产生。
![《Redis设计与实现第二版》65页]()
-
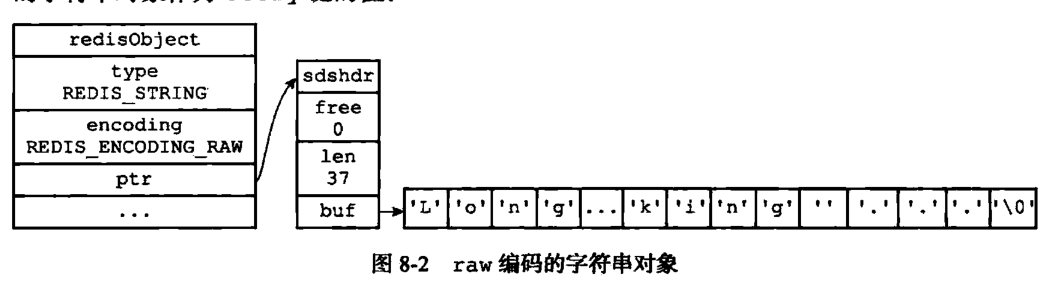
如果保存的数据是字符串,且该字符串的长度大于32字节,那么字符串将会使用raw的编码方式来保存数据。
![《Redis设计与实现第二版》65页]()
-
-
Hash
哈希类型的底层实现结构有俩种,压缩列表以及hash表;
列表对象保存的所有字符串元素的长度都小于64字节,列表对象保存的元素数量小于512个使用压缩列表,否则自动转成hash表;
-
List
列表对象保存的所有字符串元素的长度都小于64字节,列表对象保存的元素数量小于512个使用压缩列表,否则自动转成linklist表;
列表使用的是双向链表的实现形式实现的;
列表使用ziplist实现
![img]()
列表使用linkedlist实现
![img]()
3.2版本后引入了quicklist,快速列表,quicklist是使用ziplist和linkedlist结合实现的,它把linkedlist分成多段,每段使用ziplist实现保持数据的紧凑,多个ziplist使用双向指针连接成链表;
列表使用quicklist实现
![img]()
-
Set
集合分别使用整数数组和哈希表实现;
当集合长度小于512,且存储的元素都是整数时,使用整数数组,否则使用哈希表存储;
整数数组优点是节省空间,缺点是索引慢,所以在数据量较少时使用这种方式实现;
-
ZSet
有序集合分别使用压缩列表和zset实现;
当集合长度小于128时,且所有元素的长度小于64时使用压缩列表实现,否则使用跳表;
zset是使用跳表和字典实现的;其数据结构如下图:
![img]()
跳表是指通过维护多级索引,来优化查询时的速度。
跳表结构
![跳跃表]()
数据结构时间复杂度
名称 时间复杂度 哈希表 O(1) 查询时间稳定良好 跳表 O(logN) 数据量越大,时间复杂度逐渐降低 双向链表 O(N) 根据数据量线性增大 压缩列表 O(N)根据数据量线性增大 整数数组 O(N)根据数据量线性增大 各结构优点
名称 时间复杂度 哈希表 查询快 跳表 有序,数据量大时查询快 双向链表 头尾节点访问快,适合按序访问 压缩列表 节省空间内存,小数据量情况使用 整数数组 节省空间内存,小数据量情况使用,无序






 浙公网安备 33010602011771号
浙公网安备 33010602011771号