-
论文阅读:
1、变循环发动机智能控制器设计------胡雪兰
该文章中将强化学习中的确定性策略梯度(DPG)算法融合进AC(演员-评论家)框架中,用来对变循环发动机(VCE)进行控制研究。算法结构图如下所示:
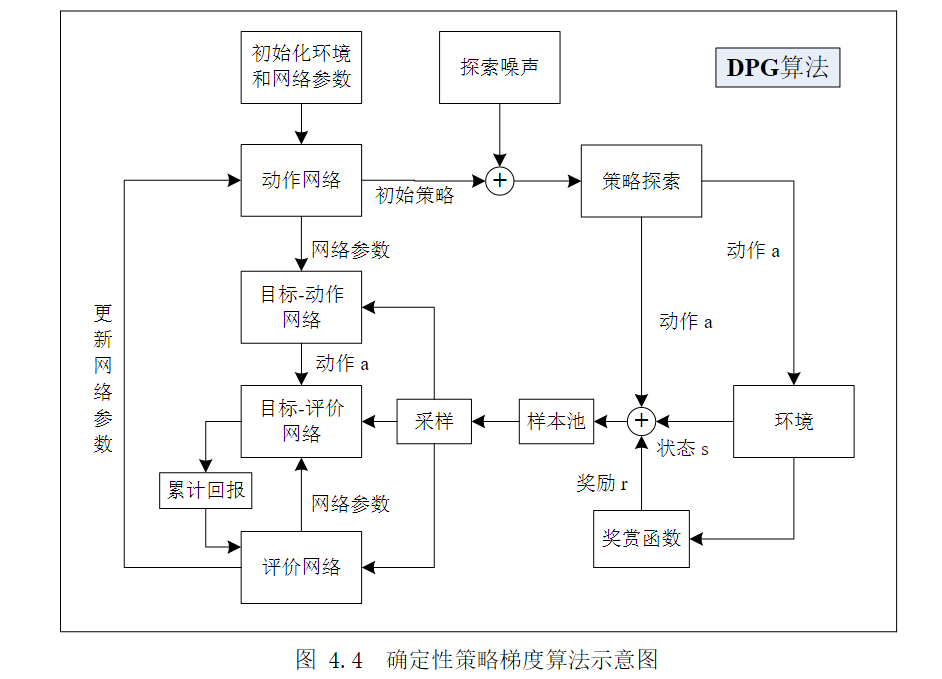
在文章中详细介绍了经典的确定性策略梯度算法和基于优先回放机制的确定性策略梯度算法。给出了两个算法的不同和算法更新步骤。
随后论文中提出了基于改进的DPG算法的变循环发动机多变量控制。实验大致思路:首先在simulink中搭建起某型变循环发动机的模型,该模型是八个输入、两个输出的控制系统用m语言进行DPG算法的编写,经过训练后保存相应网络的参数。
该文章所谓的多变量控制是对系统的八个控制变量进行控制,分别为主燃油流量Wf和高压压气机导流叶片角度,风扇导流叶片角度,尾喷管膨胀面积,风扇导流叶片角度,低压涡轮导向器控制角度,核心机风扇混合器面积和第一外涵道混合器面积。
实验细节包括:奖励函数的设计、动作的选取(八个控制变量的可调量视为动作的选取)、环境状态的选取(选取高压压气机相对转速和发动机落压比稳态误差作为环境状态)、策略网络和评价网络的参数设置。
在simulik中的方针结构图如下:
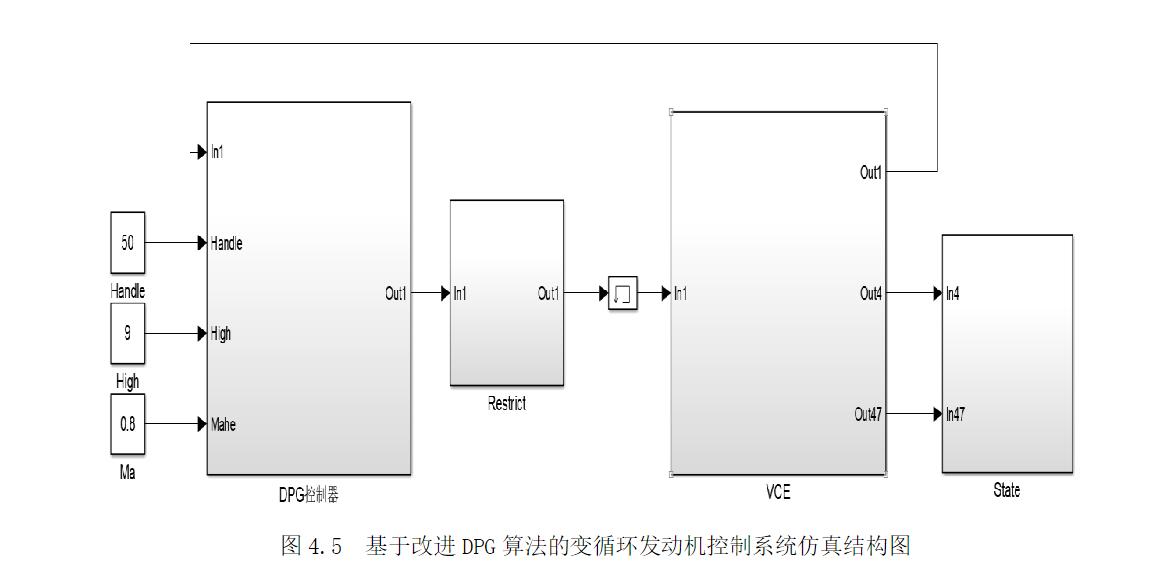
仿真结果分析:采用DPG的多变量控制方法在响应时间和输出结果上均优于参考曲线。
2、变循环涡扇发动机智能控制方针平台研究————姜渭宇
该文章建立了三涵道变循环发动机方针用数学模型。重要贡献在于提出了基于变循环控制性能、动态控制性能、安全性三个方面的评价函数设计方法。详见该文章中的表格3。
3、基于强化学习方法的变循环航空发动机推力控制————齐义文
文章中认为变循环发动机变工况下单PID控制器性能不足。于是基于强化学习方法提出了两种推力控制器设计方法。
(1)、基于深度Q网络方法
状态选择:推力误差、高低压转子转速、上一时刻主燃油流量
动作选取:主燃油流量的增量
奖励函数设计:文章中采用了分段奖励函数的方法。其中Fn_e是推力误差绝对值、r是奖励值。

控制策略设计:方法与算法Q_Learning中的贪婪机制相同。训练初期贪婪度选择0.7 后期贪婪度选择0.9以保证安全性。完成训练之后,将贪婪度置零,使其完全按照已具备的大量经验Q网络输出燃油增量动作。
更新Q_table(Q网络):[s, a, s_, r, is_done] is_done是判断状态S_是否为终止状态。
评价:我认为该方法与常规的Q_Learning算法结构相同,只是应用背景是发动机,重要的是发动机的模型。
(2)基于DDPG的推力控制
DDPG原理图如下:

控制器设计分为四步:
actor估计网络设计:网络输出对应参数是主燃油增量awf
......
设计步骤复杂,详情见论文。
仿真结果分析:针对两种工况下,DQN和DDPG 控制效果都良好。正确性和可靠性都良好。
二者比较:DDPG控制下超调量明显小于DQN,控制精度和响应时间二者相差不大。总结:DQN本质上还是实现离散的输出,在结果上还是存在微小震荡,而DDPG可以实现连续的输出。

-
算法原理学习
1、学会通过Pycharm调动Matlab中的simulink模型。方法细节:安装在anaconda中建立虚拟环境安装MATLAB库,通过python语句调用matlab.engone。
2、应用DDPG算法控制matlab中的水箱液面。训练结果如下,每次训练次数200-500不等,完成训练后,控制性能稳定。

3、学习强化学习算法:Q_Learning、Sarsa 二者算法更新细节不一样。Q网络随机性更强,训练效果好,但是不具有安全性,Sarsa算法偏保守,训练时间长,但是安全性偏高。
q学习和sarsa算法的大致思路相同,都是基于Q表格学习,但是q学习是基于对下一步状态的Q值的想象,而sarsa算法是直接考虑下一步状态的Q值。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号