kubernetes-sample
K8S基础概念
一、核心概念
1、Node
Node作为集群中的工作节点,运行真正的应用程序,在Node上Kubernetes管理的最小运行单元是Pod。Node上运行着Kubernetes的Kubelet、kube-proxy服务进程,这些服务进程负责Pod的创建、启动、监控、重启、销毁、以及实现软件模式的负载均衡。
Node包含的信息:
- Node地址:主机的IP地址,或Node ID。
- Node的运行状态:Pending、Running、Terminated三种状态。
- Node Condition:…
- Node系统容量:描述Node可用的系统资源,包括CPU、内存、最大可调度Pod数量等。
- 其他:内核版本号、Kubernetes版本等。
查看Node信息:
kubectl describe node
2、Pod
Pod是Kubernetes最基本的操作单元,包含一个或多个紧密相关的容器,
一个Pod可以被一个容器化的环境看作应用层的“逻辑宿主机”;
一个Pod中的多个容器应用通常是紧密耦合的,Pod在Node上被创建、启动或者销毁;
每个Pod里运行着一个特殊的被称之为Pause的容器,其他容器则为业务容器,这些业务容器共享Pause容器的网络栈和Volume挂载卷,因此他们之间通信和数据交换更为高效,在设计时我们可以充分利用这一特性将一组密切相关的服务进程放入同一个Pod中。
同一个Pod里的容器之间仅需通过localhost就能互相通信。

一个Pod中的应用容器共享同一组资源:
- PID命名空间:Pod中的不同应用程序可以看到其他应用程序的进程ID;
- 网络命名空间:Pod中的多个容器能够访问同一个IP和端口范围;
- IPC命名空间:Pod中的多个容器能够使用SystemV IPC或POSIX消息队列进行通信;
- UTS命名空间:Pod中的多个容器共享一个主机名;
- Volumes(共享存储卷):Pod中的各个容器可以访问在Pod级别定义的Volumes;
Pod的生命周期通过Replication Controller来管理;通过模板进行定义,然后分配到一个Node上运行,在Pod所包含容器运行结束后,Pod结束。
Kubernetes为Pod设计了一套独特的网络配置,包括:为每个Pod分配一个IP地址,使用Pod名作为容器间通信的主机名等。
3、Service
在Kubernetes的世界里,虽然每个Pod都会被分配一个单独的IP地址,但这个IP地址会随着Pod的销毁而消失,这就引出一个问题:
如果有一组Pod组成一个集群来提供服务,那么如何来访问它呢?Service!
一个Service可以看作一组提供相同服务的Pod的对外访问接口,Service作用于哪些Pod是通过Label Selector来定义的。
- 拥有一个指定的名字(比如my-mysql-server);
- 拥有一个虚拟IP(Cluster IP、Service IP或VIP)和端口号,销毁之前不会改变,只能内网访问;
- 能够提供某种远程服务能力;
- 被映射到了提供这种服务能力的一组容器应用上;
如果Service要提供外网服务,需指定公共IP和NodePort,或外部负载均衡器;
NodePort
系统会在Kubernetes集群中的每个Node上打开一个主机的真实端口,这样,能够访问Node的客户端就能通过这个端口访问到内部的Service了
4、Volume
Volume是Pod中能够被多个容器访问的共享目录。
5、Label
Label以key/value的形式附加到各种对象上,如Pod、Service、RC、Node等,以识别这些对象,管理关联关系等,如Service和Pod的关联关系。
6、RC(Replication Controller)
- 目标Pod的定义;
- 目标Pod需要运行的副本数量;
- 要监控的目标Pod标签(Lable);
Kubernetes通过RC中定义的Lable筛选出对应的Pod实例,并实时监控其状态和数量,如果实例数量少于定义的副本数量(Replicas),则会根据RC中定义的Pod模板来创建一个新的Pod,
然后将此Pod调度到合适的Node上启动运行,直到Pod实例数量达到预定目标。
二、Kubernetes总体架构
Master和Node
Kubernetes将集群中的机器划分为一个Master节点和一群工作节点(Node)。
其中,Master节点上运行着集群管理相关的一组进程etcd、API Server、Controller Manager、Scheduler,后三个组件构成了Kubernetes的总控中心,这些进程实现了整个集群的资源管理、Pod调度、弹性伸缩、安全控制、系统监控和纠错等管理功能,并且全都是自动完成。
在每个Node上运行Kubelet、Proxy、Docker daemon三个组件,负责对本节点上的Pod的生命周期进行管理,以及实现服务代理的功能。
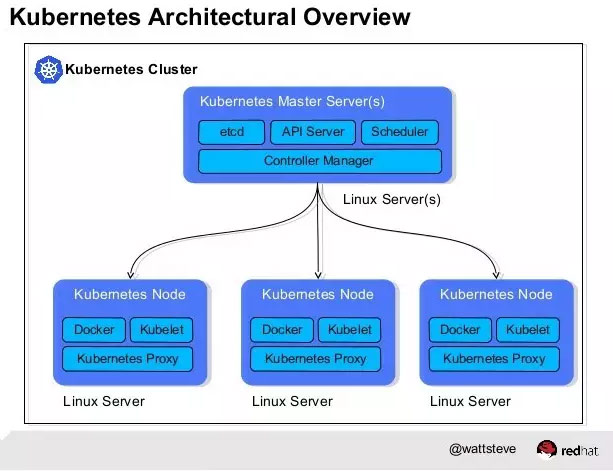
流程
通过Kubectl提交一个创建RC的请求,该请求通过API Server被写入etcd中,此时Controller Manager通过API Server的监听资源变化的接口监听到这个RC事件,分析之后,发现当前集群中还没有它所对应的Pod实例,于是根据RC里的Pod模板定义生成一个Pod对象,通过API Server写入etcd,接下来,此事件被Scheduler发现,它立即执行一个复杂的调度流程,为这个新Pod选定一个落户的Node,然后通过API Server讲这一结果写入到etcd中,随后,目标Node上运行的Kubelet进程通过API Server监测到这个“新生的”Pod,并按照它的定义,启动该Pod并任劳任怨地负责它的下半生,直到Pod的生命结束。
随后,我们通过Kubectl提交一个新的映射到该Pod的Service的创建请求,Controller Manager会通过Label标签查询到相关联的Pod实例,然后生成Service的Endpoints信息,并通过API Server写入到etcd中,接下来,所有Node上运行的Proxy进程通过API Server查询并监听Service对象与其对应的Endpoints信息,建立一个软件方式的负载均衡器来实现Service访问到后端Pod的流量转发功能。
-
etcd
用于持久化存储集群中所有的资源对象,如Node、Service、Pod、RC、Namespace等;API Server提供了操作etcd的封装接口API,这些API基本上都是集群中资源对象的增删改查及监听资源变化的接口。 -
API Server
提供了资源对象的唯一操作入口,其他所有组件都必须通过它提供的API来操作资源数据,通过对相关的资源数据“全量查询”+“变化监听”,这些组件可以很“实时”地完成相关的业务功能。 -
Controller Manager
集群内部的管理控制中心,其主要目的是实现Kubernetes集群的故障检测和恢复的自动化工作,比如根据RC的定义完成Pod的复制或移除,以确保Pod实例数符合RC副本的定义;根据Service与Pod的管理关系,完成服务的Endpoints对象的创建和更新;其他诸如Node的发现、管理和状态监控、死亡容器所占磁盘空间及本地缓存的镜像文件的清理等工作也是由Controller Manager完成的。 -
Scheduler
集群中的调度器,负责Pod在集群节点中的调度分配。 -
Kubelet
负责本Node节点上的Pod的创建、修改、监控、删除等全生命周期管理,同时Kubelet定时“上报”本Node的状态信息到API Server里。 -
Proxy
实现了Service的代理与软件模式的负载均衡器。
客户端通过Kubectl命令行工具或Kubectl Proxy来访问Kubernetes系统,在Kubernetes集群内部的客户端可以直接使用Kuberctl命令管理集群。Kubectl Proxy是API Server的一个反向代理,在Kubernetes集群外部的客户端可以通过Kubernetes Proxy来访问API Server。
API Server内部有一套完备的安全机制,包括认证、授权和准入控制等相关模块。
POD生命周期管理
(一) 核心概念
Pod是kubernetes中的核心概念,kubernetes对于Pod的管理也就是对Pod生命周期的管理,对Pod生命周期的管理也就是对Pod状态的管理,
我们通过下面Pod相关的各个实体信息关系图可以分析出来kubernetes是如何管理Pod状态的。
(二) 结构体介绍
Pod这个结构体中有个变量Status,通过这个变量可以得到每个Pod的状态信息,这个Status变量对应的结构体是PodStatus,
从图中可以看出来Pod状态信息同四个变量相关,分别是Phase、Conditions、InitContainerStatuses和ContainerStatuses,
这四个变量分别表示Pod所在生命周期阶段、Pod生命周期需要满足的条件、Pod中所有初始化容器状态、Pod中所有应用容器状态。
变量Phase有五个可选的值,分别是Pending、Running、Succeeded、Failed和Unknown。
这个五个值的含义分别是: 1) Pending:kubernetes已经开始创建Pod,但是Pod中的一个或多个容器还没有被启动。比如Pod正处在应该被分配到哪个节点上这个调度过程中,或者kubernetes还在从镜像仓库中下载Pod中容器镜像这个下载过程中。 2) Running:kubernetes已经将Pod分配到节点上,并且Pod中的所有容器都启动了。还包括Pod中至少有一个容器仍然在运行状态,或者正在重新启动状态。 3) Succeeded:Pod中的所有容器都处在终止状态,并且这些容器是自主正常退出到终止状态的,也就是退出代码为0,而且kubernetes也没有重启任何容器。 4) Failed:Pod中的所有容器都处在终止状态,并且至少有一个容器不是正常终止的,也就是退出代码不为0,或者是由于系统强行终止的。 5) Unknown:由于一些特殊情况无法获取Pod状态,比如由于网络原因无法同Pod所在的主机通讯。 变量Phase的取值还取决于结构体PodSpec中的RestartPolicy变量,这个RestartPolicy变量是用来设置Pod中容器重启策略的,包括三个可选值,分别是Always、OnFailure和Never。
这三个值得含义分别是: 1) Always:表示对容器一直执行重启策略。如果不设置RestartPolicy,那么Always是默认值。 2) OnFailure:表示在容器失败的时候重启容器。 3) Never:表示在对容器不执行重启策略。
变量Conditions对应结构体PodCondition,在这个结构体中有两个变量Type和Status。变量Type表示有效的条件类型,变量Status表示每种类型对应的状态。
变量Type有三个可选的值,分别是PodScheduled、Ready和Initialized。
这三个值的含义分别是: 1) PodScheduled:表示Pod处在调度过程中。 2) Ready:表示Pod已经能够提供服务了。 3) Initialized:表示Pod中所有初始化容器都已经成功启动了。
变量Status表示每种Type对应的状态,有三个可选的值,分别是True、False和Unknown。
这三个值的含义分别是: 1) True:表示Pod处于某种类型的有效条件中。 2) False:表示Pod不在某种类型的有效条件中。 3) Unknown:表示kubernetes无法判断Pod是否在某种类型的有效条件中。
变量InitContainerStatuses和ContainerStatuses对应结构体ContainerStatus,记录Pod中所有初始化容器状态和所有应用容器状态,结构体ContainerStatus表示一个容器的状态,在这个结构体中变量State表示容器当前状态,变量State对应结构体ContainerState。
结构体ContainerState中包括三个变量Waiting、Running和Terminated,分别表示等待状态、运行状态和结束状态,结构体ContainerState中三个变量只能有一个处在生效状态,如果无法确定哪个剩下,那么会选择等待状态。
变量Terminated对应结构体ContainerStateTerminated,结构体ContainerStateTerminated中有一个变量ExitCode,通过这个变量来记录上面提到的容器退出代码,如果容器正常退出那么退出代码为0,否则为其他值。
(三) 设置Pod生命周期
设置Pod生命周期,也就是设置结构体PodStatus中变量Phase的值,下面的流程图展示了如何设置变量Phase的值。
在kubernetes1.3的POD中,有两类容器,一类是系统容器(POD Container),一类是用户容器(User Container),在用户容器中,现在又分成两类容器,一类是初始化容器(Init Container),一类是应用容器(App Container),设置Pod生命周期需要使用到用户容器。
首先检查Pod中所有初始化容器状态,接着检查Pod中所有应用容器状态,接着根据这两类容器状态和RestartPolicy来设置Pod生命周期。
如下为根据具体不同的条件设置Pod生命周期的例子:
1.如果Pod中存在任何一个初始化容器,当这个初始化状态是Terminated,并且这个初始化容器非正常退出,也就是退出代码不为0,并且RestartPolicy是Never,那么Pod生命周期为Failed。 2.如果Pod中存在任何一个初始化容器,当这个初始化容器状态是Waiting,并且这个初始化容器上一次终止状态不为空,也就是LastTerminationState不为空,
并且这个初始化容器上一次是非正常退出,也就是退出代码不为0,并且RestartPolicy是Never,那么Pod生命周期为Failed。 3.如果Pod中存在任何一个应用容器,当这个应用容器状态是Waiting,并且这个应用容器上一次终止状态为空,也就是LastTerminationState为空,那么Pod生命周期为Pending。
也就是说当Pod中有应用容器没有开始运行的时候,Pod生命周期为Pending。 4.如果Pod中所有应用容器都不存在Waiting状态,或者Pod中存在Waiting状态的应用容器,但是这些应用容器上一次终止状态不为空,
如果满足上面两种情况之一,并且Pod中存在一个Running状态的应用容器,那么Pod生命周期为Running。
也就是说当Pod中所有应用容器都出于正常启动状态,并且存在一个状态是Running的应用容器时,那么Pod生命周期为Running。 5.如果Pod中不存在Running状态的应用容器,当满足这个条件时,如果Pod中存在Terminated状态的应用容器,
或者Pod中存在Waiting状态的应用容器,并且这些应用容器的上一次终止状态不为空,这时候如果RestartPolicy是Always,那么Pod生命周期为Running,
也就是说Pod中所有应用容器都存在重启状态,这时候如果RestartPolicy不是Always,那么如果所有应用容器都正常终止,那么Pod生命周期为Succeeded,这时候如果RestartPolicy为Never,
那么如果有一个容器处在失败状态,Pod生命周期就是Failed,这时候如果RestartPolicy是OnFailure,那么如果有一个容器处在重启失败状态,Pod生命周期就是Running。 6. 如果都不满足上面条件,那么Pod生命周期默认处在Pending状态。
pod定义详解
下面是一个完整的yaml格式定义的文件,注意格式,子集包含关系,不要有tab,要用空格。不是所有的元素都要写,按照实际应用场景配置即可。
定义一个简单pod(最好把docker源改成国内的)
apiVersion: v1 kind: Pod metadata: name: hello-world namespace: default spec: restartPolicy: OnFailure containers: - name: hello image: "ubuntu:14.04" command: ["/bin/echo","hello","world"] pod文件解释: apiVersion: v1//k8s版本 kind: pod//声明API对象类型这里是pod metadata: name:hello-word //pod名字必须在namespace中是唯一 spec://配置pod具体配置 restartPolicy: OnFailure // pod重启策略 [Always默认策略,当容器退出时总是重启容器|Never当容器退出时,从不重启|OnFailure容器正常退出不会再重新启动,退出码非0时才重启容器] containers: //pod中的容器列表,可以有多个容器 - name: hello //容器名字,在一个pod中唯一 image: "ubuntu:14.04" //镜像名字 command: ["/bin/echo","hello","word"]//设置容器的启动命令
创建pod
[root@k8s-master kubernetes-sample]# kubectl create -f helloworld.yml pod "hello-world" created
[root@k8s-master kubernetes-sample]# kubectl get pods --show-all=true NAME READY STATUS RESTARTS AGE hello-world 0/1 ContainerCreating 0 1m jenkins-4163869451-j5602 0/1 Pending 0 46m [root@k8s-master kubernetes-sample]#
这里要说一下command和args2个参数:

pod中定义env
容器获取pod信息
my_api.yaml
apiVersion: v1 kind: Pod metadata: name: print-pod-info namespace: default spec: containers: - name: my-pod image: busybox resources: requests: memory: "32Mi" cpu: "125m" limits: memory: "64Mi" cpu: "250m" env: - name: MY_POD valueFrom: fieldRef: fieldPath: metadata.name - name: MY_POD_NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespace - name: MY_POD_IP valueFrom: fieldRef: fieldPath: status.podIP - name: MY_POD_SERVICE_ACCOUNT valueFrom: fieldRef: fieldPath: spec.serviceAccountName - name: MY_CPU_REQUEST valueFrom: resourceFieldRef: containerName: my-pod resource: requests.cpu - name: MY_CPU_LIMIT valueFrom: resourceFieldRef: containerName: my-pod resource: limits.cpu - name: MY_MEM_REQUEST valueFrom: resourceFieldRef: containerName: my-pod resource: requests.memory - name: MY_MEM_LIMIT valueFrom: resourceFieldRef: containerName: my-pod resource: limits.memory command: ["/bin/sh","-c","while true;do sleep 5;done"] my_api.yaml
解释:
env:
- name: MY_POD 定义的变量名字最好是大写
valueFrom: 获取pod中的信息这个是固定的
fieldRef: 获取pod中的信息这个是固定的
fieldPath: metadata.name 获取pod中的信息这个是固定的
定义普通变量:
env:
- name: MY_POD 定义的变量名字最好是大写
value: "massage......" 变量的值
端口:
配置nginx
apiVersion: v1 kind: Pod metadata: name: my-nginx namespace: default spec: containers: - image: nginx imagePullPolicy: IfNotPresent name: nginx ports: - name: web containerPort: 80 //容器内部端口 protocol: TCP //协议可选 hostIP: 0.0.0.0 //worknodeIP可选,0.0.0.0就是任意选择 hostPort: 8000 //worknode(宿主机)上的端口
提示:
ports.name 这个值在pod中也是唯一的,当配置一个端口的时候是可选的,多个端口是必选。
如果同时2个pod的的宿主机端口都是80那么k8s会将容器分别调度到没有占用80端口机器上启动
数据持久化和共享
piVersion: v1 kind: Pod metadata: name: newhello namespace: default spec: restartPolicy: Never containers: - name: write image: "ubuntu:14.04" command: ["/bin/sh","-c","echo \"hello word\" >> /data/hello"] volumeMounts: - name: data 挂在下面定义卷data mountPath: /data 挂载到容器中的目录 - name: read image: "ubuntu:14.04" command: ["bash","-c","sleep 10; cat /data/hello"] volumeMounts: - name: data mountPath: /data volumes: 定义卷 - name: data 卷名字 hostPath: 宿主机 path: /tmp 宿主机路径
pod生命周期:
1、 Pending:kubernetes已经开始创建Pod,但是Pod中的一个或多个容器还没有被启动。比如Pod正处在应该被分配到哪个节点上这个调度过程中,或者kubernetes还在从镜像仓库中下载Pod中容器镜像这个下载过程中。
2、 Running:kubernetes已经将Pod分配到节点上,并且Pod中的所有容器都启动了。还包括Pod中至少有一个容器仍然在运行状态,或者正在重新启动状态。
3、 Succeeded:Pod中的所有容器都处在终止状态,并且这些容器是自主正常退出到终止状态的,也就是退出代码为0,而且kubernetes也没有重启任何容器。
4、 Failed:Pod中的所有容器都处在终止状态,并且至少有一个容器不是正常终止的,也就是退出代码不为0,或者是由于系统强行终止的。
5、 Unknown:由于一些特殊情况无法获取Pod状态,比如由于网络原因无法同Pod所在的主机通讯。
变量Phase的取值还取决于结构体PodSpec中的RestartPolicy变量,这个RestartPolicy变量是用来设置Pod中容器重启策略的,包括三个可选值,分别是Always、OnFailure和Never。
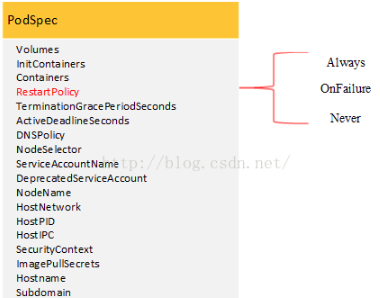
这三个值得含义分别是:
1、Always:表示对容器一直执行重启策略。如果不设置RestartPolicy,那么Always是默认值。
2、OnFailure:表示在容器失败的时候重启容器。
3、 Never:表示在对容器不执行重启策略。
总结一下pod重启策略和容器退出后。pod状态

pod生命周期回调
主要作用就是在容器开始的时候做一个动作,容器停止的时候做一个动作
apiVersion: v1
kind: Pod
metadata:
name: javaweb2
namespace: default
spec:
containers:
- image:ubuntu:14.04
name: war
lifecycle:
postStart:
exec:
command:
- "cp"
- "/sample.war"
- "/app"
preStop:
httpGet:
host: monitor.com
path: /warning
port: 8080
scheme: HTTP
PostStart:容器创建成功后回调
PreStop :容器终止前回调
自定义pod检查
在很多实际场景下,仅仅使用进程级健康检查还远远不够。有时,从Docker的角度来看,容器进程依旧在运行;但是如果从应用程序的角度来看,代码处于死锁状态,即容器永远都无法正常响应用户的业务
为了解决以上问题,Kubernetes引人了一个在容器内执行的活性探针(Liveness Probe)和(Readiness Probe)的概念,以支持用户自己实现应用业务级的健康检查。这些检查项由Kubelet代为执行,以确保用户的应用程序正确运转,至于什么样的状态才算“正确”,则由用户自己定义。
1Liveness Probe 容器自定义检查,检查失败容器被杀死,然后根据pod重启策略来做
2Readiness Probe 检查失败直接从代理后端移除,既不会分发请求给改pod。
Kubernetes支持3种类型的应用健康检查动作,分别为HTTP Get、Container Exec和TCP Socket。个人感觉exec的方式还是最通用的,因为不是每个服务都有http服务,但每个服务都可以在自己内部定义健康检查的job,定期执行,然后将检查结果保存到一个特定的文件中,外部探针就不断的查看这个健康文件就OK了。
HTTPget:
path URL路径
port 端口
host 请求IP
scheme:求情协议默认HTTP
[root@k8s-master livenessProbe]# cat test-livenessprobe.yaml apiVersion: v1 kind: Pod metadata: labels: name: test-livenessprobe name: test-livenessprobe spec: containers: - name: test-livenessprobe image: registry:5000/back_demon:1.0 livenessProbe: httpGet: path: /starott_cloud_client/test/overview-frontend port: 8080 initialDelaySeconds: 15 periodSeconds: 5 timeoutSeconds: 1 command: - /run.sh HTTPGET
TCP Socket:
tcpSocket:
port:8080
检查tcp端口8080是否正常
Exec:
exec:
command:
这里拿exec做例子演示Liveness Probe和Readiness Probe区别:
apiVersion: v1 kind: Pod metadata: name: livemess-probe labels: test: liveness spec: containers: - name: libeness image: "ubuntu:14.04" command: - /bin/sh - -c - echo ok > /tmp/health; sleep 30;rm -rf /tmp/health;sleep 600 livenessProbe: exec: command: - cat - /tmp/health initialDelaySeconds: 15 timeoutSeconds: 1 livenessProbe
日志查询:
一个pod中2个容器,一个正常退出一个异常退出。重启策略O:nFailure,异常退出时在重启容器
apiVersion: v1 kind: Pod metadata: name: logs-pod namespace: default spec: restartPolicy: OnFailure containers: - name: cont1 image: "ubuntu:14.04" command: ["bash","-c","echo \"cont1:`date --rfc-3339 ns`\";exit 0"] - name: cont2 image: "ubuntu:14.04" command: ["bash","-c","echo \"cont2:`date --rfc-3339 ns`\";exit 1"] logs-pod.yml
查看容器1和容器2日志
[root@kubernetes-master pods]# kubectl logs logs-pod cont1
cont1:2017-07-11 13:15:41.122936441+00:00
[root@kubernetes-master pods]# kubectl logs logs-pod cont2
cont2:2017-07-11 13:21:40.452165906+00:00
查看日志历史,有的时候会出现查询不到当前日志,我们就 可意查询上一次容器打的日志。加上这个--previous
[root@kubernetes-master pods]# kubectl logs logs-pod cont2 --previous
cont2:2017-07-11 13:21:40.452165906+00:00
定义持久化日志
apiVersion: v1 kind: Pod metadata: name: logs-pod namespace: default spec: restartPolicy: OnFailure containers: - name: cont1 terminationMessagePath: /dev/termination-log image: "ubuntu:14.04" command: ["bash","-c","echo \"cont1:`date --rfc-3339 ns`\" >> /dev/termination-log;"]
用到的参数terminationMessagePath:
[root@kubernetes-master pods]# kubectl get pod logs-pod --template="{{range .status.containerStatuses}}{{.state.terminated.message}}{{end}}" --show-all
cont1:2017-07-11 13:28:03.421374195+00:00
远程连接容器
1、exec(功能强大)
2、attach(这个比较麻烦)
远程执行命令并返回
[root@kubernetes-master pods]# kubectl exec mysql -- date
Tue Jul 11 13:42:44 UTC 2017
进入pod容器
[root@kubernetes-master pods]# kubectl exec -ti mysql /bin/bash
Kubernetes网络模型
Kubernetes网络模型设计的一个基础原则是:每个Pod都拥有一个独立的IP地址,而且假定所有Pod都在一个可以直接连通的、扁平的网络空间中。所以不管它们是否运行在同一个Node(宿主机)中,都要求它们可以直接通过对方的IP进行访问。设计这个原则的原因是,用户不需额外考虑如何建立Pod之间的连接,也不需要考虑将容器端口映射到主机端口等问题。
实际在Kubernetes的世界里,IP是以Pod为单位进行分配的。
按照这个网络抽象原则,Kubernetes对网络有什么前提和要求呢?
所有容器都可以在不用NAT的方式下同别的容器通信;
所有节点都可以在不用NAT的方式下同所有容器通信,反之亦然;
容器的地址和别人看到的地址是同一个地址;
网络通信的场景
1.容器到容器的通信。 同一个Pod内的容器(Pod内的容器是不会跨宿主机的)共享同一个网络命名空间,共享同一个Linux协议栈。可以直接通过localhost互相访问。 2.Pod之间的通信:同一个Node内。 通过Veth连接在同一个docker0网桥上,它们的IP地址都是从docker0的网桥上动态获取的,它们和网桥本身的IP3是同一个网络段的。 3.不同Node上的Pod之间的通信。 对docker0的IP地址做统一的规划;对Pod的IP地址做统一的规划; 4.Pod到Service之间的通信。 Service的虚拟IP通过每个Node上的kube-proxy映射到不同的Pod上,暂时只支持轮询。 5.外部到内部的访问 NodePort、LoadBalancer。
for SERVICES in kube-proxy kubelet flanneld docker;do systemctl restart $SERVICES ; systemctl enable $SERVICES; systemctl status $SERVICES ; done
k8s常用命令
使用以下命令可以看到目前集群里的信息:master kubectl get pod # 查看目前所有的pod kubectl get rs # 查看目前所有的replica set kubectl get deployment # 查看目前所有的deployment kubectl describe pod my-nginx # 查看my-nginx pod的详细状态 kubectl describe rs my-nginx # 查看my-nginx replica set的详细状态 kubectl describe deployment my-nginx # 查看my-nginx deployment的详细状态 kubectl get eventskubectl get events查看相关事件 kubectl delete deployment my-nginx
查看集群信息:
kubectl cluster-info
[root@k8s-master kubernetes-sample]# kubectl cluster-info
Kubernetes master is running at https://192.168.56.102:6443
KubeDNS is running at https://192.168.56.102:6443/api/v1/namespaces/kube-system/services/kube-dns/proxy
kubernetes-dashboard is running at https://192.168.56.102:6443/api/v1/namespaces/kube-system/services/kubernetes-dashboard/proxy
To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.
[root@k8s-master kubernetes-sample]#
查看各组件状态
[root@kubernetes-master pods]# kubectl -s http://localhost:8080 get componentstatuses
GET信息:
查看节点
[root@k8s-master kubernetes-sample]# kubectl get pods,nodes,rc,namespace
NAME READY STATUS RESTARTS AGE
po/hello-world 0/1 ContainerCreating 0 31m
po/jenkins-4163869451-j5602 0/1 Pending 0 1h
NAME STATUS AGE VERSION
no/k8s-master Ready 4h v1.7.2
no/k8s-node1 Ready 3h v1.7.2
no/k8s-node2 Ready 1h v1.7.2
NAME STATUS AGE
ns/default Active 4h
ns/kube-public Active 4h
ns/kube-system Active 4h
[root@k8s-master kubernetes-sample]#
以jison格式输出pod的详细信息
[root@k8s-master kubernetes-sample]# kubectl get po/hello-world -o json { "apiVersion": "v1", "kind": "Pod", "metadata": { "creationTimestamp": "2018-05-17T07:53:30Z", "name": "hello-world", "namespace": "default", "resourceVersion": "31332", "selfLink": "/api/v1/namespaces/default/pods/hello-world", "uid": "63b2d6f9-59a7-11e8-aab0-080027f3aff6" }, "spec": { "containers": [ { "command": [ "/bin/echo", "hello", "world" ], "image": "ubuntu:14.04", "imagePullPolicy": "IfNotPresent", "name": "hello", "resources": {}, "terminationMessagePath": "/dev/termination-log", "terminationMessagePolicy": "File", "volumeMounts": [ { "mountPath": "/var/run/secrets/kubernetes.io/serviceaccount", "name": "default-token-sx75g", "readOnly": true } ] } ], "dnsPolicy": "ClusterFirst", "nodeName": "k8s-node2", "restartPolicy": "OnFailure", "schedulerName": "default-scheduler", "securityContext": {}, "serviceAccount": "default", "serviceAccountName": "default", "terminationGracePeriodSeconds": 30, "tolerations": [ { "effect": "NoExecute", "key": "node.alpha.kubernetes.io/notReady", "operator": "Exists", "tolerationSeconds": 300 }, { "effect": "NoExecute", "key": "node.alpha.kubernetes.io/unreachable", "operator": "Exists", "tolerationSeconds": 300 } ], "volumes": [ { "name": "default-token-sx75g", "secret": { "defaultMode": 420, "secretName": "default-token-sx75g" } } ] }, "status": { "conditions": [ { "lastProbeTime": null, "lastTransitionTime": "2018-05-17T07:53:30Z", "status": "True", "type": "Initialized" }, { "lastProbeTime": null, "lastTransitionTime": "2018-05-17T07:53:30Z", "message": "containers with unready status: [hello]", "reason": "ContainersNotReady", "status": "False", "type": "Ready" }, { "lastProbeTime": null, "lastTransitionTime": "2018-05-17T07:53:30Z", "status": "True", "type": "PodScheduled" } ], "containerStatuses": [ { "image": "ubuntu:14.04", "imageID": "", "lastState": {}, "name": "hello", "ready": false, "restartCount": 0, "state": { "waiting": { "reason": "ContainerCreating" } } } ], "hostIP": "10.0.2.15", "phase": "Pending", "qosClass": "BestEffort", "startTime": "2018-05-17T07:53:30Z" } } [root@k8s-master kubernetes-sample]#
查看指定pod跑在哪个node上
[root@k8s-master kubernetes-sample]# kubectl get po/hello-world -o wide NAME READY STATUS RESTARTS AGE IP NODE hello-world 0/1 ContainerCreating 0 35m <none> k8s-node2
获取指定json或ymal格式的KEY数据,custom-columns=XXXXX(自定义列名):.status.hostIP(以“点开始”,然后写路径就可以):
[root@kubernetes-master pods]# kubectl get po mysql -o custom-columns=HOST-IP:.status.hostIP,POD-IP:.status.podIP
HOST-IP POD-IP
10.64.8.69 172.17.62.2
describe方法
类似于get,同样用于获取resource的相关信息。不同的是,get获得的是更详细的resource个性的详细信息,describe获得的是resource集群相关的信息。
describe命令同get类似,但是describe不支持-o选项,对于同一类型resource,describe输出的信息格式,内容域相同。
注:如果发现是查询某个resource的信息,使用get命令能够获取更加详尽的信息。但是如果想要查询某个resource的状态,如某个pod并不是在running状态,这时需要获取更详尽的状态信息时,就应该使用describe命令。
kubectl describe pod hello-world
create创建
kubectl命令用于根据文件或输入创建集群resource。如果已经定义了相应resource的yaml或son文件,直接kubectl create -f filename即可创建文件内定义的resource。
也可以直接只用子命令[namespace/secret/configmap/serviceaccount]等直接创建相应的resource。从追踪和维护的角度出发,建议使用json或yaml的方式定义资源。
kubectl create -f 文件名
replace更新替换资源
replace命令用于对已有资源进行更新、替换。如前面create中创建的nginx,当我们需要更新resource的一些属性的时候,如果修改副本数量,增加、修改label,更改image版本,修改端口等。都可以直接修改原yaml文件,然后执行replace命令。
注:
名字不能被更更新。另外,如果是更新label,原有标签的pod将会与更新label后的rc断开联系,有新label的rc将会创建指定副本数的新的pod,但是默认并不会删除原来的pod。
所以此时如果使用get po将会发现pod数翻倍,进一步check会发现原来的pod已经不会被新rc控制,此处只介绍命令不详谈此问题,好奇者可自行实验。
kubectl replace -f rc-nginx.yaml
patch
如果一个容器已经在运行,这时需要对一些容器属性进行修改,又不想删除容器,或不方便通过replace的方式进行更新。kubernetes还提供了一种在容器运行时,直接对容器进行修改的方式,就是patch命令。
如前面创建pod的label是app=nginx-2,如果在运行过程中,需要把其label改为app=nginx-3。
这patch命令如下:
kubectl patch pod rc-nginx-2-kpiqt -p '{"metadata":{"labels":{"app":"nginx-3"}}}'
edit
edit提供了另一种更新resource源的操作,通过edit能够灵活的在一个common的resource基础上,发展出更过的significant resource。
例如,使用edit直接更新前面创建的pod的命令为:
kubectl edit po rc-nginx-btv4j
上面命令的效果等效于:
kubectl get po rc-nginx-btv4j -o yaml >> /tmp/nginx-tmp.yaml vim /tmp/nginx-tmp.yaml /*do some changes here */ kubectl replace -f /tmp/nginx-tmp.yaml
Delete
根据resource名或label删除resource。
kubectl delete -f rc-nginx.yaml
kubectl delete po rc-nginx-btv4jkubectl delete po -lapp=nginx-2apply
apply命令提供了比patch,edit等更严格的更新resource的方式。通过apply,用户可以将resource的configuration使用source control的方式维护在版本库中。每次有更新时,将配置文件push到server,然后使用kubectl apply将更新应用到resource。kubernetes会在引用更新前将当前配置文件中的配置同已经应用的配置做比较,并只更新更改的部分,而不会主动更改任何用户未指定的部分。apply命令的使用方式同replace相同,不同的是,apply不会删除原有resource,然后创建新的。apply直接在原有resource的基础上进行更新。同时kubectl apply还会resource中添加一条注释,标记当前的apply。类似于git操作。
logs
logs命令用于显示pod运行中,容器内程序输出到标准输出的内容。跟docker的logs命令类似。如果要获得tail -f 的方式,也可以使用-f选项。
kubectl logs rc-nginx-2-kpiqt
rolling-update 提供了不中断业务的更新方式
rolling-update是一个非常重要的命令,对于已经部署并且正在运行的业务,rolling-update提供了不中断业务的更新方式。rolling-update每次起一个新的pod,等新pod完全起来后删除一个旧的pod,然后再起一个新的pod替换旧的pod,直到替换掉所有的pod。 rolling-update需要确保新的版本有不同的name,Version和label,否则会报错 。 kubectl rolling-update rc-nginx-2 -f rc-nginx.yaml 如果在升级过程中,发现有问题还可以中途停止update,并回滚到前面版本 kubectl rolling-update rc-nginx-2 —rollback rolling-update还有很多其他选项提供丰富的功能,如—update-period指定间隔周期,使用时可以使用-h查看help信息
scale 用于程序在负载加重或缩小时副本进行扩容或缩小
scale用于程序在负载加重或缩小时副本进行扩容或缩小,如前面创建的nginx有两个副本,可以轻松的使用scale命令对副本数进行扩展或缩小。 扩展副本数到4: kubectl scale rc rc-nginx-3 —replicas=4 重新缩减副本数到2: kubectl scale rc rc-nginx-3 —replicas=2
autoscale
scale虽然能够很方便的对副本数进行扩展或缩小,但是仍然需要人工介入,不能实时自动的根据系统负载对副本数进行扩、缩。autoscale命令提供了自动根据pod负载对其副本进行扩缩的功能。
autoscale命令会给一个rc指定一个副本数的范围,在实际运行中根据pod中运行的程序的负载自动在指定的范围内对pod进行扩容或缩容。如前面创建的nginx,可以用如下命令指定副本范围在1~4
kubectl autoscale rc rc-nginx-3 —min=1 —max=4
attach
attach命令类似于docker的attach命令,可以直接查看容器中以daemon形式运行的进程的输出,效果类似于logs -f,退出查看使用ctrl-c。如果一个pod中有多个容器,要查看具体的某个容器的的输出,需要在pod名后使用-c containers name指定运行的容器。如下示例的命令为查看kube-system namespace中的kube-dns-v9-rcfuk pod中的skydns容器的输出。
kubectl attach kube-dns-v9-rcfuk -c skydns —namespace=kube-system
exec
exec命令同样类似于docker的exec命令,为在一个已经运行的容器中执行一条shell命令,如果一个pod容器中,有多个容器,需要使用-c选项指定容器。
run
类似于docker的run命令,直接运行一个image。
cordon, drain, uncordon
这三个命令是正式release的1.2新加入的命令,三个命令一起介绍,是因为三个命令配合使用可以实现节点的维护。在1.2之前,因为没有相应的命令支持,如果要维护一个节点,只能stop该节点上的kubelet将该节点退出集群,是集群不在将新的pod调度到该节点上。如果该节点上本生就没有pod在运行,则不会对业务有任何影响。如果该节点上有pod正在运行,kubelet停止后,master会发现该节点不可达,而将该节点标记为notReady状态,不会将新的节点调度到该节点上。同时,会在其他节点上创建新的pod替换该节点上的pod。这种方式虽然能够保证集群的健壮性,但是任然有些暴力,如果业务只有一个副本,而且该副本正好运行在被维护节点上的话,可能仍然会造成业务的短暂中断。
1.2中新加入的这3个命令可以保证维护节点时,平滑的将被维护节点上的业务迁移到其他节点上,保证业务不受影响。如下图所示是一个整个的节点维护的流程(为了方便demo增加了一些查看节点信息的操作):
1)首先查看当前集群所有节点状态,可以看到共四个节点都处于ready状态;
2)查看当前nginx两个副本分别运行在d-node1和k-node2两个节点上;
3)使用cordon命令将d-node1标记为不可调度;
4)再使用kubectl get nodes查看节点状态,发现d-node1虽然还处于Ready状态,但是同时还被禁能了调度,这意味着新的pod将不会被调度到d-node1上。
5)再查看nginx状态,没有任何变化,两个副本仍运行在d-node1和k-node2上;
6)执行drain命令,将运行在d-node1上运行的pod平滑的赶到其他节点上;
7)再查看nginx的状态发现,d-node1上的副本已经被迁移到k-node1上;这时候就可以对d-node1进行一些节点维护的操作,如升级内核,升级Docker等;
8)节点维护完后,使用uncordon命令解锁d-node1,使其重新变得可调度;8)检查节点状态,发现d-node1重新变回Ready状态

查看某个pod重启次数(这个是参考)
[root@kubernetes-master pods]# kubectl get pod my-con --template="{{range .status.containerStatuses}}{{.name}}:{{.restartCount}}{{end}}"
con:6
查看pod生命周期
[root@kubernetes-master pods]# kubectl get pod mysql --template="{{.status.phase}}"
Running
kubectl get pod -o wide --all-namespaces kube-system kubernetes-dashboard-latest 1 1 1 0 31m [root@k8s-master ~]# kubectl get pod -o wide --all-namespaces NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE default jenkins-4163869451-j5602 0/1 Pending 0 19m <none> <none> kube-system etcd-k8s-master 1/1 Running 0 3h 10.0.2.15 k8s-master kube-system kube-apiserver-k8s-master 1/1 Running 0 3h 10.0.2.15 k8s-master kube-system kube-controller-manager-k8s-master 1/1 Running 0 3h 10.0.2.15 k8s-master kube-system kube-dns-2030594980-v8j7l 3/3 Running 0 3h 10.244.0.2 k8s-master kube-system kube-flannel-ds-3bbrz 2/2 Running 0 8m 10.0.2.15 k8s-node2 kube-system kube-flannel-ds-mkk29 2/2 Running 0 3h 10.0.2.15 k8s-master kube-system kube-flannel-ds-pvg63 2/2 Running 6 2h 10.0.2.15 k8s-node1 kube-system kube-proxy-fbbps 1/1 Running 0 8m 10.0.2.15 k8s-node2 kube-system kube-proxy-kb25p 1/1 Running 0 3h 10.0.2.15 k8s-master kube-system kube-proxy-n16cj 1/1 Running 2 2h 10.0.2.15 k8s-node1 kube-system kube-scheduler-k8s-master 1/1 Running 0 3h 10.0.2.15 k8s-master kube-system kubernetes-dashboard-latest-546057234-ph9ds 0/1 CrashLoopBackOff 10 31m 10.244.1.10 k8s-node1 [root@k8s-master ~]# kubectl get svc --all-namespaces NAMESPACE NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE default jenkins 10.98.112.112 <none> 8080/TCP,50000/TCP 20m default kubernetes 10.96.0.1 <none> 443/TCP 3h default nginx-internal-service 10.103.91.216 <none> 80/TCP 26m default nginx-service 10.97.251.207 <pending> 80:30149/TCP 26m kube-system kube-dns 10.96.0.10 <none> 53/UDP,53/TCP 3h kube-system kubernetes-dashboard 10.102.44.5 <none> 80/TCP 31m [root@k8s-master ~]# kubectl get deployment --all-namespaces NAMESPACE NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE default jenkins 1 1 1 0 20m kube-system kube-dns 1 1 1 1 3h kube-system kubernetes-dashboard-latest 1 1 1 0 32m [root@k8s-master ~]#


 浙公网安备 33010602011771号
浙公网安备 33010602011771号