K8S应用访问控制相关技术以及在公有云落地的实践经验
K8S应用访问控制相关技术以及在公有云落地的实践经验
背景
在企业内使用K8S,其上部署的应用是否需要严格的访问控制,这个答案并不总是肯定的,至少支持访问控制并不是方案选型时的优先考虑要素。但对于我们行云创新来讲,这种控制必不可少。因为,我们提供的公有云业务允许任何个人和团队自由地开发和部署应用到任意云端,那么为每位用户的应用提供安全可靠的访问控制是一个十分基本的要求。相信我们对公有云复杂需求的摸索经验和一些解决思路也将对众多企业落地K8S私有云非常有借鉴意义。
K8S提供了一种叫NetworkPolicy的对象,专门用来解决L3/L4访问控制的问题。然而,它只定义了如何制定这些策略,而它们如何来发挥作用却还要仰仗各K8S网络插件的支持程度。而对于不同类型的网络插件在支持NetworkPolicy方面又有各自的解法和面临的挑战。
在本次分享中,我们将在简单分析主流K8S网络插件如何支持NetworkPolicy之余,讲述行云创新在实现访问控制的过程中遇过到的那些挑战,以及它们又是如何被解决的。
1.首先我们来聊聊K8S NeworkPolicy 对象 。
简单的说,NetworkPolicy 是通过定义策略对选定POD进行网络通讯控制的,这样可以让运行在POD里的业务受到安全保护。K8S早在1.6版本中就支持了NetworkPolicy对象,但只能通过Selector对Pod间通讯进行控制,直至1.8版本在NetworkPolicyPeer对象支持IPBlock之后,才具备了通过指定IP段(CIDR)的方式对集群内外访问进行全面控制。
2.下面我们分析一下NetworkPolicy是如何工作的。
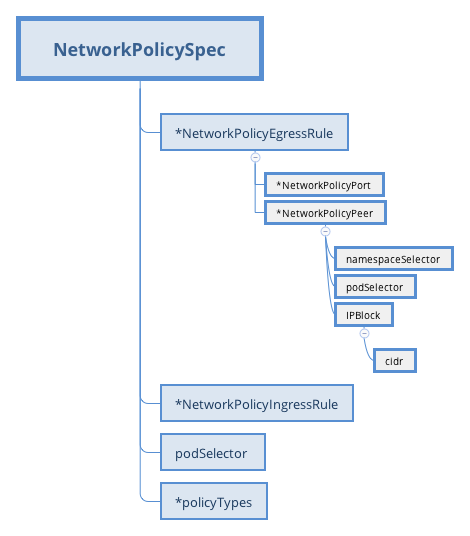
上图是NetworkPolicy对象的结构平铺图。NetworkPolicy的作用域在Namespace内,它通过podSelector来确定哪些Pod将受这个policy约束。在一个NetworkPolicy对象中,可以设置多条NetworkPolicyEgressRule和NetworkPolicyIngressRule,分别用来做出口和入口的访问控制。每条Rule由一组NetworkPolicyPeer和一组NetworkPolicyPort组成,意思比较明确,这组Peers的这些Ports被授予了访问权限。
NetworkPolicyPeer则可以是两类资源,其一是通过namespace selector和pod selector来筛选出Pod,另一则是前文提到过的IPBlock,它通过CIDR来指定。具体的配置方式可以参考官方文档【https://kubernetes.io/docs/concepts/services-networking/network-policies】。
从上图我们可以看出,无论Ingress还是Egress,NetworkPolicy定义的是Pod之间或者Pod和某些CIDR之间的关系。从K8S的设计理念和访问实际发生的位置来看,这样的设计实在再合理不过。然而,却给实现层面增加了不少复杂度,甚至可能会影响到是否能够让方案落地实现。
问题主要出在以下几方面。
1. Pod网络由各网络插件提供的网络驱动支持,NetworkPolicy几乎全部依赖这些网络驱动来实现,而不同原理的网络驱动并不一定能实现NetworkPolicy的全部功能,而且难易程度也有所不同,即便到了今天,K8S已经发布了1.10,NetworkPolicy仍然没有被所有主流网络插件完整支持。
2. 虽然Pod网络由网络驱动实现,但Service网络却是K8S管理的,而K8S应用都是通过Service向外提供服务的,这中间的转换也会对NetworkPolicy的实现有严重的影响。
3. 在遵循NetworkPolicy的前提下,同时还要考虑以下各种情况如何应对:
a. Pod访问API server的情形
b. 基于网络访问的Probes(LivenessProbe和ReadinessProbe)
c. kube-proxy的--masquerade-all选项的开启和关闭
d. NodePort类型的Service是否会受到影响
e. 集群扩容时NetworkPolicy的考虑等
接下来我们简单分析一下主流的网络插件对NetworkPolicy的支持程度。
首先我们聊一聊Calico。
Calico提供的是一个基于路由的解决方案,也就是说Pod之间的交互将通过在Node上生效的各种路由规则来实现。如下图所示。
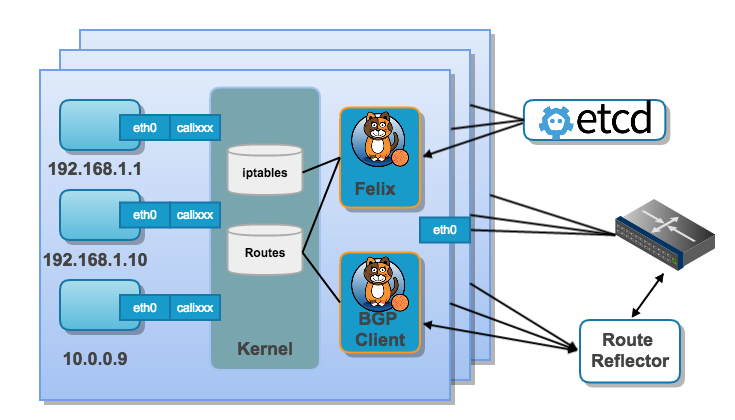
Calico部署完成后,每台Node上的Calico组件Felix会负责根据etcd中的配置来修改路由和iptables规则。Calico的组件BIRD则负责将这些路由策略分发到其他Node。Calico不但支持NetworkPolicy的特性,还支持了更多的安全策略,用户可以通过calicoctl客户端来配置,而这些特性也皆是通过iptables来实现的。
然后再说说Cilium。
Cilium是一个十分有趣的项目,在组网方面它同时提供了基于路由的组网方式和基于VxLAN的Overlay网络。而在访问控制方面,它使用了BPF而非netfilter。如下图所示。
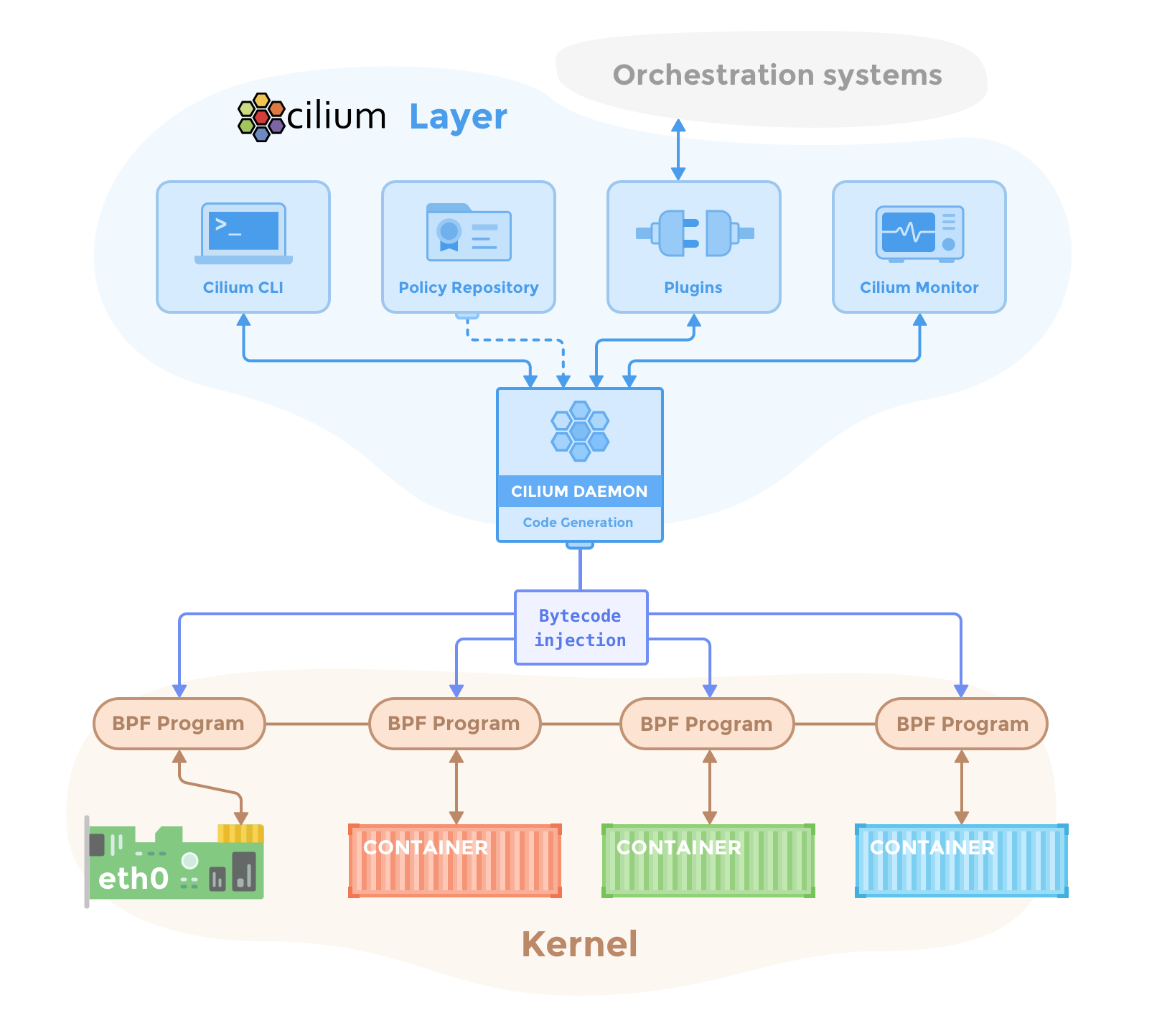
比起其他的网络驱动,Cilium还比较年轻,尚未完全支持NetworkPolicy,但是它提供了CiliumNetworkPolicy对象用来提供更多的访问控制特性,不只包括L3/L4的访问控制,甚至涵盖了L7的访问控制,十分了得。
最后我们聊聊WeaveNet。WeaveNet提供了一种十分便利的方式在K8S主机之间构建一个Overlay网络,工作原理如下图所示。
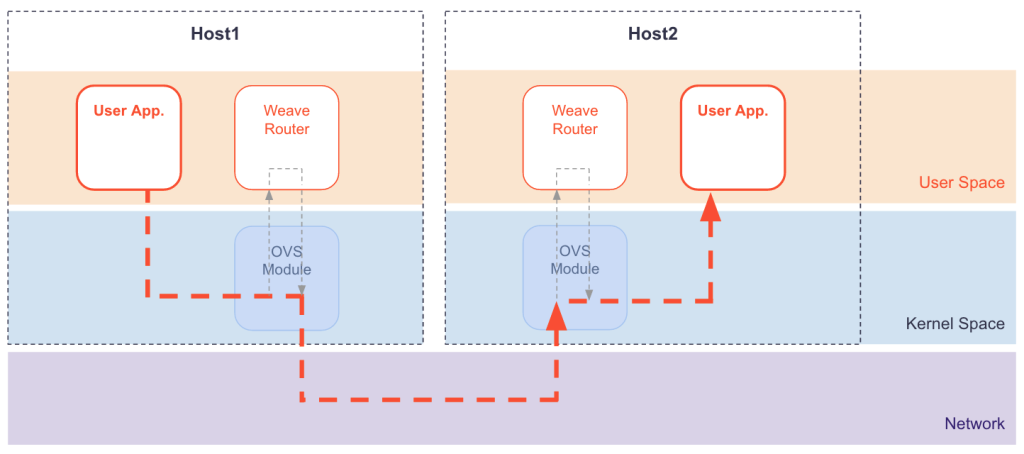
WeaveNet在K8S上以DaemonSet的形式部署,每个Pod中包含两个容器,分别是weave-kube和weave-npc。前者负责构建网络,后者则是[n]etwork-[p]olicy-[c]ontroller。WeaveNet需要在每台主机上创建一个bridge,作为主机上所有接入weave网络的Pod的网关,不同主机的bridge之间的数据流则会通过VxLAN协议转发,其他的数据流都会在主机上经过SNAT从而进入主机网络。
对于NetworkPolicy,WeaveNet仅仅支持NetworkPolicyIngressRule和基于Selector的NetworkPolicyPeer,并不支持IPBlock类型的Peer。WeaveNet的实现方式和其他插件类似,通过从API Server监听NetworkPolicy的状态,修改主机上iptables策略和ipset来实现控制。
我们行云创新是如何进行选择呢?
行云创新的公有云服务必须要具备跨多个云供应商的能力来帮助用户解除对单一云依赖,并构筑成本优势。不同的云厂商,如阿里、华为、Azure、Ucloud、AWS等提供的网络架构和网络能力是差异很大的, 这就决定了我们必然会面对十分复杂并且多样的网络环境,也应该选择一种与各公云的网络架构兼容最好的K8S网络方案。
先看看我们曾经在阿里上遇到的一个问题:

阿里云在网络底层采用了ARP劫持技术,所有网络通讯(包括L2)都要到网关中转,自定义的“非法网络” 将被丢弃,此时需要在阿里云平台上的路由表中增加策略,才有可能成功。而其它家云在这些方面的行为又会大不相同,包括可能会存在路由表条目数量的限制。因此,基于路由技术的网络插件,如Calico就不是最合适的选择。
那么看看基于“隧道”技术的实现方案。同样使用VxLAN技术的Flannel和WeaveNet要如何选择呢?WeaveNet除了配置简单,它还有一个独特的功能,那就是它并不要求所有主机必须处于full mesh network中,对于如下这种网络拓扑它也能够支持。

所以行云创新在公有云的实现上选择了WeaveNet,但如同其它网络插件一样,在NetworkPolicy的支持上,它也无法完全满足我们应对的公有云环境下应用控问控制需求。
对于我们来说,对NetworkPolicy最迫切的需求当是支持IPBlock类型的NetworkPolicyPeer,这也是多集群管理的需要。试想多个微服务分别部署在不同地理位置、不同云商的集群中时,IPBlock是K8S给我们的唯一选择。为什么WeaveNet只支持了通过Selector来定义NetworkPolicyPeer,IPBlock不能用类似的方法来实现吗?那我们必须来分析一下。
weave-npc通过API Server监听NetworkPolicy的变化,并随之改变配置。它在得到NetworkPolicyPeer对象后,根据其中的Selector筛选出符合条件的Pod,在得到Pod的IP地址后便可以在Pod所在主机iptables的Filter表中设置规则,接受来自这些地址的请求。当然,实际的实现方式要更高效和复杂一点。那么基于IPBlock的NetworkPolicyPeer是否也能如此简单?答案当然是否定的,至于原因还要从如何从集群外访问到集群内应用说起,我们称之为L3接入方式。
K8S以Service的方式管理L3接入,那么便可以通过LoadBalancer和NodePort直接从集群外访问Service,这是比较常见的方式。但技术上来讲,我们还可以打通集群外到ClusterIP的路由,来直接访问Service的ClusterIP。照此原理,若大家希望从集群外直接访问Pod网络本身,通过直接路由的方式也是可以达成的,只不过要把Pod的IP暴露到全网中。
我们来看看自集群外访问集群内服务的简图。
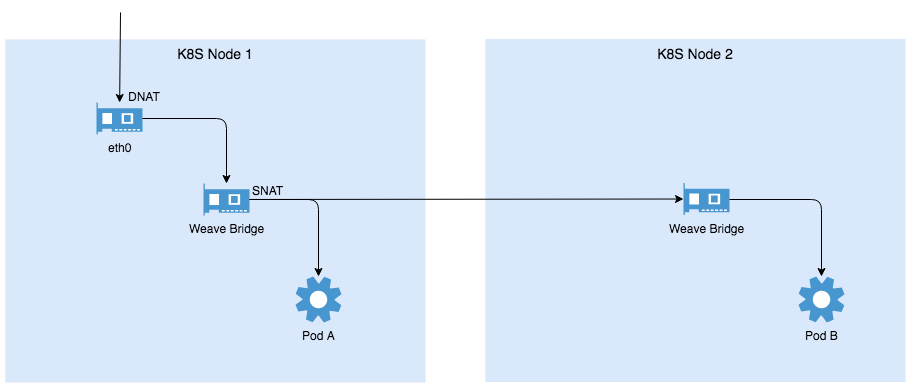
如上图所示,无论是通过NodePort还是直接访问Service ClusterIP的方式来接入,所有请求都会在进入主机网络时经过DNAT,将目标地址和端口转换成Service对应的Pod及其端口。而在经由Weave bridge将请求转发到Pod或者另一台Node的Weave Bridge前(此时会通过隧道方式以VxLAN协议传输)会再做一次SNAT,将源地址修改为Weave Bridge的地址,这是K8S确定的规则。
面对这个问题,我们的解决思路是,只要将针对每个Pod的NetworkPolicy应用到所有的Node上而非仅仅在Pod所在的Node上即可,如同kube-proxy一样。这样,WeaveNet就可以全面支持单K8S集群的NetworkPolicy了。此外,还有一个有趣的问题值得思考,Pod和Node之间的交互是否要受NetworkPolicy的约束[?这个问题我将在稍后和各位朋友加以分析。
接下来,我们来讲述一个更加复杂的场景,也是行云创新要面对的场景,即将不同的微服务部署到不同地理位置、不同云商的K8S集群,它们要如何相互访问,又如何来做访问控制呢?为了延续用户在K8S集群中的使用习惯和代码习惯,在跨集群部署服务时维持Service和K8S的服务发现机制是必须的(跨地理位置、跨云商的服务发现我们会在未来分享中详细加以交流)。请看下图。
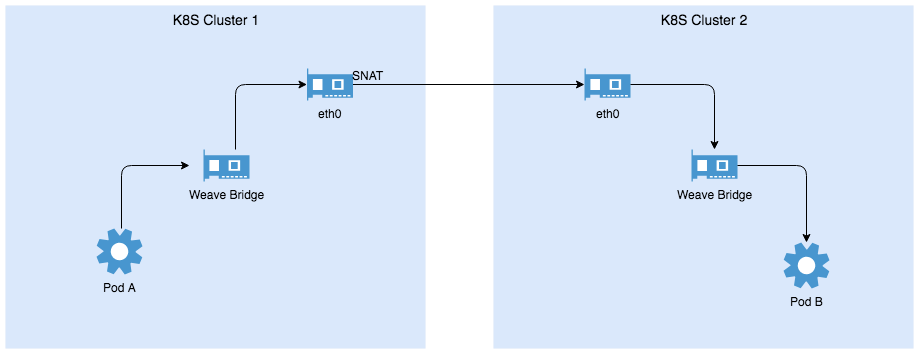
从路由的角度来看,跨集群访问并没有什么特别之处,打通双向路由即可。然而WeaveNet提供的是Overlay的解决方案,主机网络上并不存在到Pod网络的路由策略,所有的Pod到集群外的访问均在从主机网卡发出时做了SNAT,故在Cluster2的Node上看到的请求源地址是Cluster1的Node地址,而非Pod A的地址,因此不能在Cluster2上简单地使用Pod A的地址通过IPBlock配置NetworkPolicy。
那么WeaveNet在此时做SNAT是必要的吗?答案是肯定的。Pod网络和主机网络是相互隔离的,若他们要互相访问,则必须要建立起路由(Calico的做法),或者在这种特殊架构的前提下使用SNAT,使得Pod网络保持独立且不污染外部网络环境。那么为了实现跨集群的访问控制,我们必须对从Pod发出的请求区别对待,若是访问其他集群的Service则不需要SNAT,否则依然要做SNAT。
至此,WeaveNet在行云创新跨地理位置、跨云商的场景下的连通和访问控制就完全实现了,而且它最大限度地继承了用户对K8S的使用习惯。至于如何使用和开发网络插件,关键还是在于充分理解K8S对Service和Pod网络的定义。
最后,对于前文中提出的问题“Pod和Node之间的交互是否要受NetworkPolicy的约束?”来分享一下我们的思考。
从完整性的角度来讲,一旦开启了NetworkPolicy,那么所有的交互都应当受其控制,这其中自然包括Pod和Node之间的通讯。此时就需要考虑,当Pod需要访问API Server或者设置Probe策略时,为它们开通访问控制的责任是否要交给用户?用户是否有足够的信息来完成这些设置?但从运营的角度来讲,集群中所有的Node都在运营商的控制中,是安全的,也就可以认为Pod和这些Node之间的通讯也是安全的。
分享徐国韬,行云创新公司架构师。我们公司为开发者提供一站式全云端开发平台。我主要负责公司产品的底层技术,包括容器、网络、存储、安全等多个领域。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号