浅析Postgres中的并发控制(Concurrency Control)与事务特性(上)
PostgreSQL为开发者提供了一组丰富的工具来管理对数据的并发访问。在内部,数据一致性通过使用一种多版本模型(多版本并发控制,MVCC)来维护。这就意味着每个 SQL 语句看到的都只是一小段时间之前的数据快照(一个数据库版本),而不管底层数据的当前状态。这样可以保护语句不会看到可能由其他在相同数据行上执行更新的并发事务造成的不一致数据,为每一个数据库会话提供事务隔离。MVCC避免了传统的数据库系统的锁定方法,将锁争夺最小化来允许多用户环境中的合理性能。
使用MVCC并发控制模型而不是锁定的主要优点是在MVCC中,对查询(读)数据的锁请求与写数据的锁请求不冲突,所以读不会阻塞写,而写也从不阻塞读。甚至在通过使用革新的可序列化快照隔离(SSI)级别提供最严格的事务隔离级别时,PostgreSQL也维持这个保证。
今天我们就从基础开始聊聊PostgreSQL内部的这一特性,聊聊MVCC和PostgreSQL中的事务特性。
这里,我们先用一个表格展示PostgreSQL中的事务等级,在看到后面章节时可以翻回来看看。
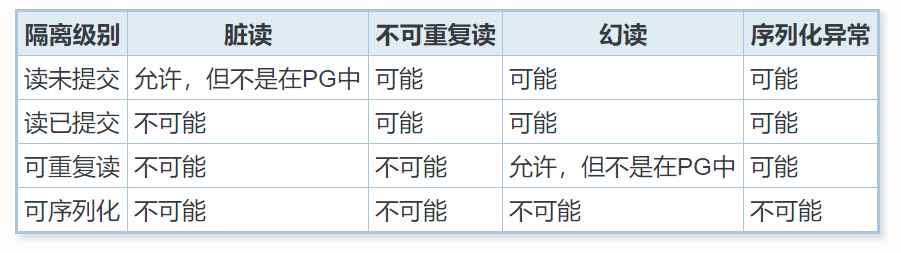
1.基础知识
1.1事务ID
当一个事务开始时,PostgreSQL中的事务管理系统会为该事务分配一个唯一标识符,即事务ID(txid).PostgreSQL中的txid被定义为一个32位的无符号整数,也就是说,它能记录大约42亿个事务。通常txid对我们是透明的,但是我们可以利用PostgreSQL内部的函数来获取当前事务的txid:
postgres=# BEGIN;
BEGIN
postgres=# SELECT txid_current();
txid_current
--------------
233
(1 row)
在所有的txid中,有几个值是有特殊含义的:
txid = 0 表示 Invalid txid,通常作为判断txid的有效性使用;
txid = 1 表示 Bootstrap txid,目前情况下,只在intidb的时候,初始化数据库的时候使用
txid = 2 表示 Frozen txid,一般是在Vacuum时使用(在后面会提到)。
记住这样一个假设:txid小的事务所修改的元组对txid大的事务来说,是可见的,反之则不可见。
1.2元组(tuple)结构
关于元组的结构能说的东西很多,我在这篇文章中也谈到了一些。不过我们这里不谈那么深。关于元组(tuple)原则上可以分成普通的元组和TOAST元组。这里为简化起见,我们就只谈论简单的元组。
简单元组的结构图如下:
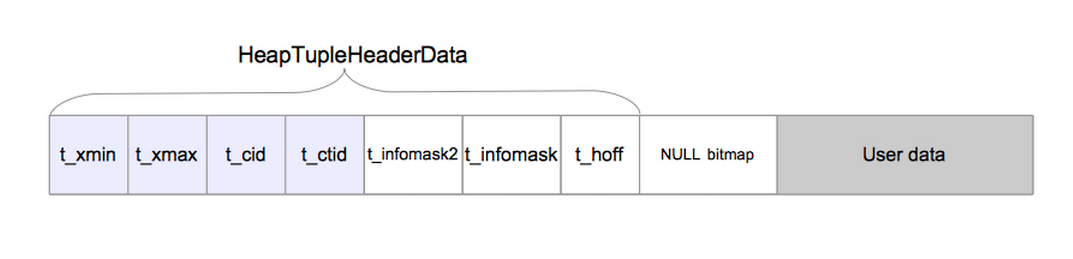
在上图中我们需要了解的和事务相关的结构是HeapTupleHeaderData结构,这个也就是一条元组的“头”部分。
有几个字段需要我们了解下:
-
t_xmin中保存的是插入这条元组的事务的txid
-
t_xmax中保存的是更新或者删除这条元组的事务的txid。如果这条元组并没有没删除或者更新,那么t_xmax字段被设置为0,即该字段INVALID
-
t_cid中保存的是插入这条元组的命令的id。在一个事务中可能会有多个命令,事务中的这些命令会依次被编号(从0开始递增)。对于如下的事务: BEGIN;INSERT ;INSERT END。那么第一个INSERT的t_cid为0,第二个INSERT的t_cid为1.依次类推。
-
t_ctid中保存元组的标识符(即tid)。它指向该元组本身或者该元组的新“版本”。因为PostgreSQL对记录的修改不会直接修改tuple中的用户数据,而是重新生成一个tuple,旧的tuple通过t_ctid指向新的tuple。如果一条记录被修改多次,那么该记录会存在多个“版本”。各版本之间通过t_ctid串联,形成一个版本链。通过这个版本链,我们就可以找到最新的版本了。实际的t_ctid是一个二元组(x,y).其中x(从0开始编号)代表元组所在的page,y(从1开始编号)表示在该page的第几个位置上。
1.3元组(tuple)的INSERT/DELETE/UPDATE操作
上面说到PostgreSQL中对记录的修改不是直接修改tuple结构,而是重新生成一个tuple,旧的tuple通过t_ctid指向新的tuple。那么这里我们依次解释INSERT/DELETE/UPDATE是如何实现的。
我们先上一个简图,这里面的page header,line pointer这些这里谈论无关的结构我就不画出来了。我们重点关注tuple在page中的位置关系。

1.3.1 INSERT操作
INSERT操作最简单,直接将一条元组放进对应的page里面即可。如下:
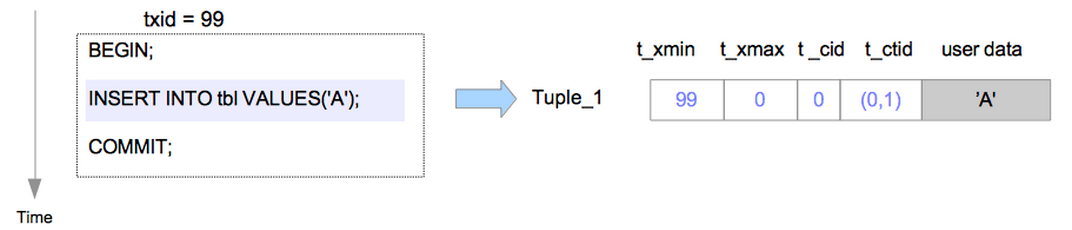
这里我们假设
-
1.该表在执行插入前为空
-
2.txid为99的事务插入了该元组==> Tuple_1。
于是在Tuple_1中我们可以看到:
-
t_xmin被设置为了99,也就是事务的txid,99.
-
t_xmax被设置为了0,因为该元组还没有被更新或者删除
-
t_cid被设置为了0,很显然,它是被事务的第一条命令插入的
-
t_ctid被设置为了(0,1),这是这个表的第一个元组,因此它被放置在第0 page的第1个位置上。
如何从数据库外部来验证呢?PostgreSQL提供了一个插件:pageinspect
我们可以像下面那样去查看数据库页面上的信息:
postgres=# CREATE EXTENSION pageinspect;
CREATE EXTENSION
postgres=# CREATE TABLE tbl (data text);
CREATE TABLE
postgres=# INSERT INTO tbl VALUES('A');
INSERT 0 1
postgres=# SELECT lp as tuple, t_xmin, t_xmax, t_field3 as t_cid, t_ctid
FROM heap_page_items(get_raw_page('tbl', 0));
tuple | t_xmin | t_xmax | t_cid | t_ctid
-------+--------+--------+-------+--------
1 | 99 | 0 | 0 | (0,1)
(1 row)
1.3.2 DELETE操作
上面说过了,PostgreSQL中的删除操作只是在逻辑上“删除了”元组,实际上该元组依然留存在数据库的存储页面中,只是对该元组进行了一些处理,使得其在查询中变得“不可见”。
假设我们在txid为111的事务中将上面插入的元组进行删除时,其结果如下:
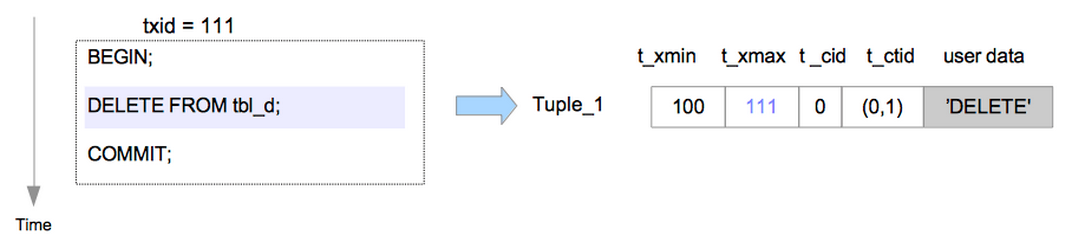
我们可以看到,Tuple_1元组的t_xmax字段被修改了,被改成了111,即删除Tuple_1的事务的txid。
当txid为111的事务被提交时,Tuple_1就成了无效的元组了,成为“dead tuple”。
从图上可以看到,这个Tuple_1依然残留在数据库的页面上。随着数据库的运行,可以预见,这种“dead tuple”会越来越多。他们,会在运行VACUUM命令时被清理掉,有关VACUUM不是我们这次讨论的重点,这里略去。
1.3.3 UPDATE操作
相对于前面两个操作,UPDATE显得稍微复杂一点。根据我们上面所说,PostgreSQL对记录的修改不会直接修改tuple中的用户数据。PostgreSQL对UPDATE的处理是先删除旧数据,后增加新数据。“翻译”过来就是将要更新的旧tuple标记为DELETE,然后再插入一条新的tuple。
同样地,我们假设在txid为99的事务中插入一条记录,并且在txid为100的事务中被先后更新2次。过程如下:
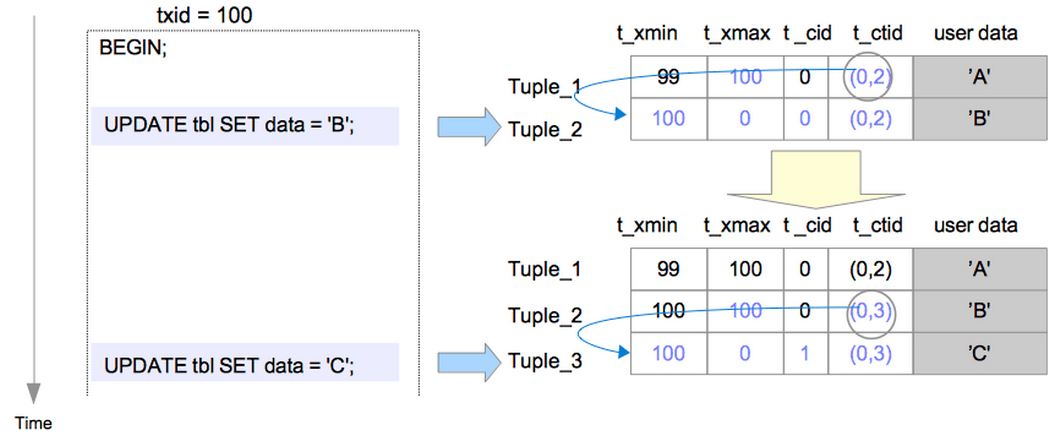
根据我们提到的"先删除旧数据,后增加新数据"的原则,当执行txid为100的事务中的第一条UPDATE命令时,操作分为两步:
-
删除旧元组Tuple_1:设置Tuple_1的t_xmax值为当前事务的txid;
-
新增新元组Tuple_2:设置Tuple_2的t_xmin,t_xmax,t_cid,t_ctid;设置Tuple_1的t_ctid指向Tuple_2
即:
对于Tuple_1:
t_xmax = 100;
t_ctid : (0,1) => (0,2)
对于Tuple_2:
t_xmin = 100;
t_xmax = 0;
t_cid = 0;
t_ctid = (0,2)
同理,当执行txid为100的事务中的第二条UPDATE命令也是如此:
对于Tuple_2:
t_xmax = 100;
t_ctid : (0,2) => (0,3)
对于Tuple_3:
t_xmin = 100;
t_xmax = 0;
t_cid = 1;
t_ctid = (0,3)
当txid为100的事务被提交时,Tuple_1和Tuple_2就成了“dead tuple”,反之,如果该事务被abort,则Tuple_2和Tuple_3就成了“dead tuple”。
说了以上这些,大家应该对这些操作在数据库内部的实现有一个粗略的理解。同时,大家可能对这个ctid很好奇。这是个标记tuple所在位置的标记。那么问题来了,tuple插入的位置是如何选定的?完全是按照顺序存放么?如果是那样,我觉得可能直接记录tuple在页面内部的偏移就好了。问题就在于这个位置的选定是有"技术"的,PostgreSQL内部有一个称为FSM的机制,即Free Space Map。通过它发现一个表的各个页面的空余空间,从而决定放在那里比较好。具体的不多说,有兴趣的可以通过PostgreSQL的另一个插件pg_freespacemap来探究一下。
postgres=# CREATE EXTENSION pg_freespacemap;
CREATE EXTENSION
postgres=# SELECT *, round(100 * avail/8192 ,2) as "freespace ratio"
FROM pg_freespace('accounts');
blkno | avail | freespace ratio
-------+-------+-----------------
0 | 7904 | 96.00
1 | 7520 | 91.00
2 | 7136 | 87.00
3 | 7136 | 87.00
4 | 7136 | 87.00
5 | 7136 | 87.00
....
有了上面的这些基础,我们就可以继续讨论一些较为深入的内容了。
2.MVCC基础
2.1 事务提交日志(commit log)
PostgreSQL采用的日志主要有XLOG和CLOG,即事务日志和事务提交日志。XLOG是一般的日志记录,即通常意义上所认识的日志记录,它记录了事务对数据更新的过程和事务的最终状态。CLOG在一般的数据库教材上是没有提及的,其实CLOG是XLOG的一种辅助形式,记录了事务的最终状态。因为每一条XLOGH志记录相对较大,如果需要通过日志判断一个事务的状态,那么使用CLOG比使用XLOG要髙效得多。同时CLOG占用的空间也非常有限,因此它被存储在共享内存中,可以快速地读取。
下面我们就来看看clog的工作原理及其维护过程。
首先,在CLOG中,PostgreSQL定义了四个事务状态:
IN_PROGRESS,
COMMITTED,
ABORTED,
SUB_COMMITTED.
除了最后一个状态,其它的状态都是“人如其名”,不多说。而SUB_COMMITTED针对的是子事务,这里先不讨论太多。
由于存储在共享内存中,CLOG是以8KB大小的page存储的。在CLOG的页面内部事务状态是以类似"数组"的形式存储的。其中"数组"的下标就是事务的ID,"数组"中的值即为对应下标的事务的当前状态。由于CLOG只记录事务的4个状态,因此,只需要2个bit就可以表示,即一个字节可以表示4个事务状态。在一个CLOG page(8KB)中,可以表示8K*8b/2b=32K=2^15条CLOG记录。
下面上例子:
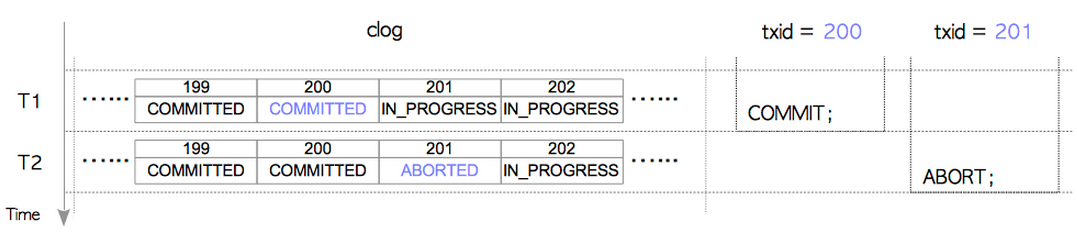
在T1时刻:txid为200的事务提交了,那么在CLOG中txid为200的事务的状态从IN_PROGRESS装换为COMMITTED。
在T2时刻:txid为201的事务abort了,那么在CLOG中txid为201的事务的状态从IN_PROGRESS装换为ABORTED。
整个CLOG就这样一直追溯着事务系统中所有事务的状态。如果有新的事务则直接在"数组"后面添加。当当前页面(8KB大小)已经存满时,则增加一个新的page进行记录。
当PostgreSQL数据库shutdown或者当进行checkpoint时,CLOG中的数据会被写回到pg_clog目录下。打开pg_clog目录,我们会发现一些命名为0000,0001之类的文件。这些即为CLOG文件。这些文件的最大的size为256KB。也就是说,一个文件最多可以存储256KB/8kB=32个CLOG。如果当前有8个CLOG,那么0000文件就可以存下来。而如果当前有35个CLOG,那么就需要0000,0001两个文件来存储,以此类推。
而当PostgreSQL数据库启动的时候,pg_clog文件夹下的CLOG记录又会被读到共享内存中。
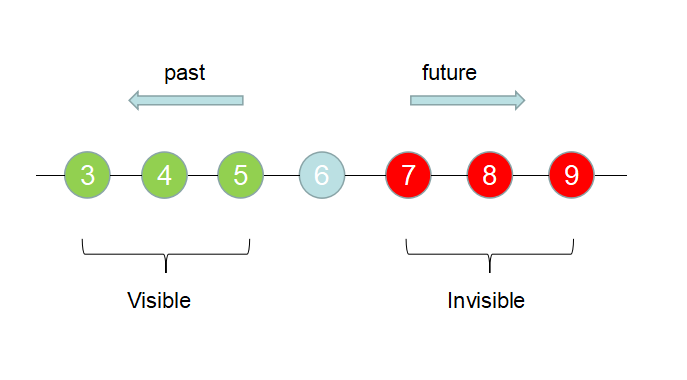
2.2 事务快照(Transaction Snapshot)
终于要说到事务快照了。
事务快照我认为是一个很形象的词,很容易从字面上理解它的意味。所谓"快照",就是拿着照相机"咔嚓"一声记录下当前瞬间的信息,在按下快门后所发生的变化我们统统无法察觉,即invisible。
同样地,事务快照就是当某一个事务执行期间,记录的某一个时间点上哪些事务是active,所谓active,就是说这个事务要么在执行中(in progress),要么还没有开始。
PostgreSQL有内置的函数可以获取当前的数据快照:txid_current_snapshot()函数
通过该函数可以获取当前的快照,但是快照信息解读起来需要费一点脑筋。
postgres=# SELECT txid_current_snapshot();
txid_current_snapshot
-----------------------
100:104:100,102
(1 row)
上面的数据快照是这样一个数字序列构成: xmin:xmax:xip_list
下面我来一一介绍各个字段的意义。
- xmin
最早的active的事务的txid,即txid值最小的active事务;所有txid小于该值的事务,如果1.状态为commited则为visible,2.状态aborted则为dead,
- xmax
第一个还未分配的txid,所有txid大于该值的事务在快照生成时尚未开始,即不可见
- xip_list
快照生成时所有active的事务的txid。
对照上面的解释,我们来两个有代表性的例子吧:
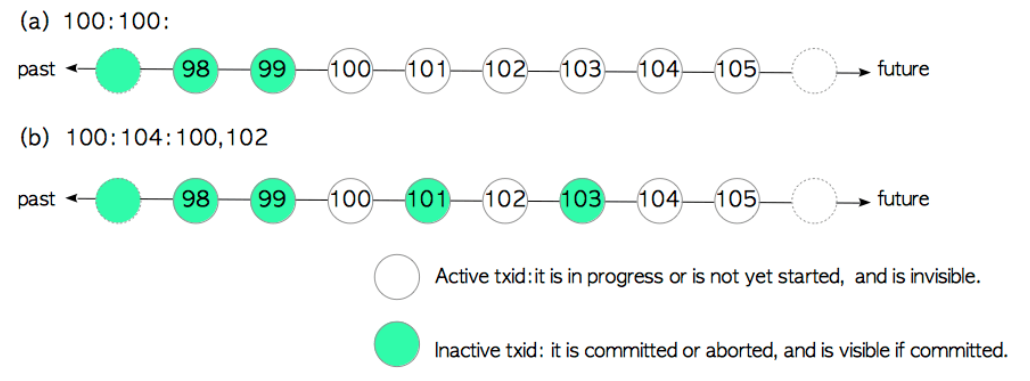
- 对于(a):
txid小于100的事务都不是active的;
txid大于等于100的事务都是active的。
- 对于(b)
txid小于100的事务都不是active的;
txid大于等于104的事务都是active的;
txid为100和102都是active的,101和103都不是active的。
那么我们疑惑了,我们花这么多篇幅去判断一个事务是不是active有什么意义呢?
下面来了。
在PostgreSQL中,当一个事务的隔离级别是READ COMMITTED时,在该事务中的每个命令执行之前都会重新获取一次snapshot,而如果一个事务的隔离级别是REPEATABLE READ或者SERIALIZABLE时,该事务只在第一条命令执行时获取snapshot。
记住以上的差别,正是以上的差别引起tuple的可见性的差别,从而实现不同的隔离级别。
还是来一张图来解释上面的话吧。
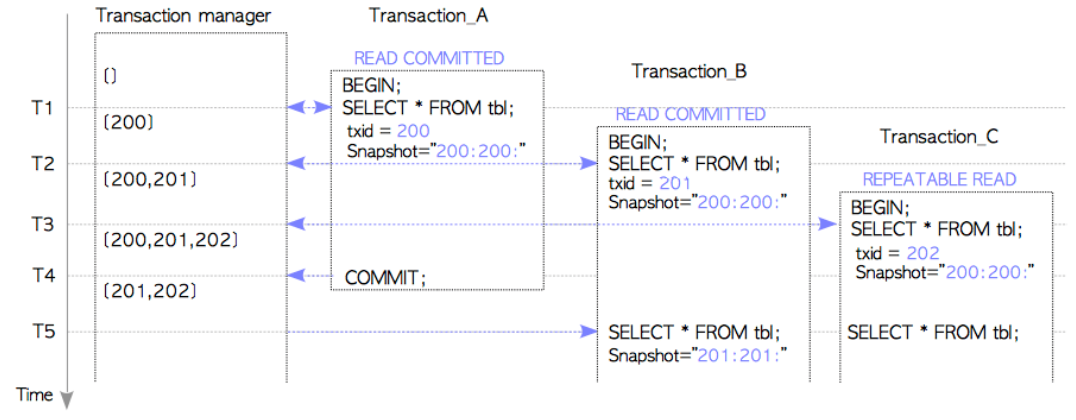
我们假设上面的三个事务依次执行,其中Transaction_A 和Transaction_B的隔离级别都是READ COMMITTED,Transaction_C的隔离级别是REPEATABLE READ。我们分时间段T1~T5来解释:
T1
Transaction_A开始并执行第一条命令,此时获取txid和snapshot。事务系统给Transaction_A分配txid为200,并获取当前快照为 200:200:
T2
Transaction_B开始并执行第一条命令,此时获取txid和snapshot。事务系统给Transaction_B分配txid为201,并获取当前快照为 200:200:,因为Transaction_A正在执行中,所以Transaction_B无法看到Transaction_A中的修改。
T3
Transaction_C开始并执行第一条命令,此时获取txid和snapshot。事务系统给Transaction_C分配txid为202,并获取当前快照为 200:200:,因为Transaction_A正在执行中,所以Transaction_C无法看到Transaction_A和Transaction_B中的修改。
T4
Transaction_A进行了commit。事务管理系统删除了Transaction_A的信息。
T5
Transaction_B和Transaction_C分别执行它们的SELECT命令。
此时,Transaction_B获取一个新的snapshot(因为它的隔离级别是READ COMMITTED),该snapshot为 201:201:。因为Transaction_A的已经提交。Transaction_A对Transaction_B可见。
同时,由于Transaction_C的隔离级别是REPEATABLE READ,它仍然使用第一条命令执行时获得的snapshot 200:200 ,因此Transaction_A和Transaction_B仍然对Transaction_C不可见。
2.3元组可见性规则
所谓"元组可见性(Tuple Visibility)"的规则就是利用:
1.tuple中的t_xmin和t_xmax字段;
2.clog
3.当前的snapshot
来判断一个tuple对当前事务中的执行语句是可见还是不可见。所谓可见与不可见就是说当前命令在处理时是否要处理该tuple。
还是为了简便起见,我们回避了子事务和有关t_ctid的问题。只讨论最简单的情形。
我们选取十条规则并将他们分为三类进行说明。
1. t_xmin的状态为ABORTED
我们知道t_xmin是一个tuple被INSERT时的事务txid。如果该事务的状态为ABORTED,说明该事务被取消,那么理所当然该事务所INSERT的tuple自然是无效并且是不可见的。所以Rule1即为:
Rule 1: If Status(Tuple.t_xmin) = ABORTED ⇒ Tuple is Invisible
2. t_xmin的状态为IN_PROGRESS
如果一个tuple的t_xmin的状态为IN_PROGRESS,那么很大可能它是不可见的。
因为:
如果这个tuple是其它事务(非当前事务)所插入的,那么这个tuple显然是不可见的,因为这个tuple还未提交(postgreSQL不支持读未提交)。
Rule 2: If Status(t_xmin) = IN_PROGRESS && t_xmin ≠ current_txid ⇒ Tuple is Invisible
如果这个tuple是当前事务提交的,并tuple的t_xmax值不是0,即该tuple是由当前事务插入,但是被当前事务UPDATE或者DELETE过了,因此,显然是不可见的。
Rule 3: If Status(t_xmin) = IN_PROGRESS && t_xmin = current_txid && t_xmax ≠ INVAILD ⇒ Tuple is Invisible
反之,如果这个tuple是当前事务提交的,并tuple的t_xmax值是0,说明这个tuple是由当前事务插入并且并没有被修改过,所以,它是可见的。
Rule 4: If Status(t_xmin) = IN_PROGRESS && t_xmin = current_txid && t_xmax = INVAILD ⇒ Tuple is Visible
3. t_xmin的状态为COMMITTED
和上面的相反,如果一个tuple的t_xmin的状态为COMMITTED,那么很大可能它是可见的。
先把规则列出来,后面再解释。
Rule 5: If Status(t_xmin) = COMMITTED && Snapshot(t_xmin) = active ⇒ Tuple is Invisible
Rule 6: If Status(t_xmin) = COMMITTED && Snapshot(t_xmin) ≠ active && (t_xmax = INVALID || Status(t_xmax) = ABORTED) ⇒ Tuple is Visible
Rule 7: If Status(t_xmin) = COMMITTED && Status(t_xmax) = IN_PROGRESS && t_xmax = current_txid ⇒ Tuple is Invisible
Rule 8: If Status(t_xmin) = COMMITTED && Status(t_xmax) = IN_PROGRESS && t_xmax ≠ current_txid ⇒ Tuple is Visible
Rule 9: If Status(t_xmin) = COMMITTED && Status(t_xmax) = COMMITTED && Snapshot(t_xmax) = active ⇒ Tuple is Visible
Rule 10: If Status(t_xmin) = COMMITTED && Status(t_xmax) = COMMITTED && Snapshot(t_xmax) ≠ active ⇒ Tuple is Invisible
Rule5是比较显然的,对于一个tuple,插入它的事务已经提交(COMMITED),并且该事务在当前的snapshot下是active的,说明该事务对当前事务中的命令来说是 in progress 或者 not yet started(忘记的话,看下2.2节的内容),故该事务插入的tuple对在当前为不可见;
Rule6,显然,该tuple没有被修改或者修改它的事务被abort了 = > 该tuple没有被修改;插入该tuple的事务x在当前snapshot中是inactive(inactive说明事务x对于当前要执行的SQL命令来说要么被提交了,要么被abort了),所以可见;
Rule7,如果tuple被当前事务UPDATE或者DELETE了,自然这个tuple对于我们来说是旧版本了,不可见;
Rule8,和Rule7对比,这个tuple是被别的事务x修改(UPDATE或者DELETE)了,而且事务x没有被提交(postgreSQL不支持读未提交),所以修改后的元组对我们不可见,我们能看到的还是当前这个元组,所以当前tuple可见;
Rule9,虽然修改这个tuple的事务x已经提交了,但是事务x在当前snapshot中是active的,即对当前事务中的命令来说是 in progress 或者 not yet started(第二次用到这个假设了),所以事务x的修改对当前命令不可见,所以我们看到了还是这个tuple;
Rule10,和上一条相反,修改这个tuple的事务x已经提交了,并且事务x在当前snapshot中是inactive(inactive说明事务x对于当前要执行的SQL命令来说要么被提交了,要么被abort了)的,所以对当前事务中的命令来说,这个事务x已经提交,所以这个tuple对当前事务中的命令而言,已经是被修改过了,即是旧版本的了,所以即为不可见。
3.PostgreSQL中的MVCC
又交代了一些基础知识,下面正式进入MVCC。
3.1 元组可见性检测
这一节我们来谈论PostgreSQL中的"元组可见性"的检测。
所谓"元组可见性"的检测就是利用元组可见性规则来判断一个tuple对当前事务中的执行语句是可见还是不可见。我们知道在PostgreSQL中是tuple是多版本,那么对于一个事务中的命令来说,它需要找到对应事务中当前命令应该看到的那个版本的tuple进行处理。
通过"元组可见性"的检测不仅仅可以帮助找到正确"版本"的tuple,同时还可以用来解决 ANSI SQL-92 标准中定义的异常:
脏读;
不可重复读;
幻读
即,可以实现不同的事务隔离级别。
还是上例子吧:
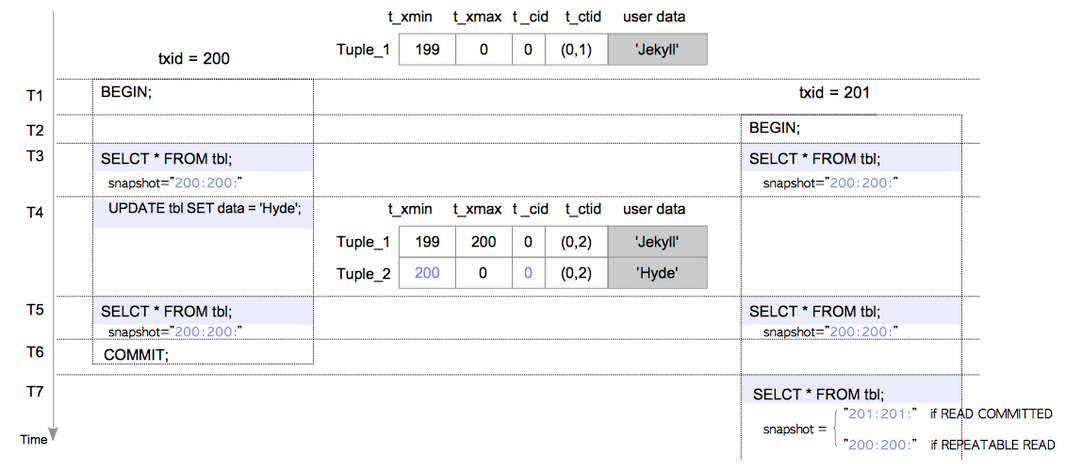
简化起见,txid=200的事务的隔离级别为READ COMMITTED,txid=201的事务的隔离级别我们分READ COMMITTED或者REPEATABLE READ两种情况讨论。
上图中命令的执行顺序如下:
T1 :txid=200的事务开始
T2 :txid=201的事务开始
T3 :txid=200和txid=201的事务分别执行SELECT命令
T4 :txid=200的事务执行UPDATE命令
T5 :txid=200和txid=201的事务分别执行SELECT命令
T6 :txid=200的事务commit
T7 :txid=201的事务执行SELECT命令
下面我们就来看看PostgreSQL是如何执行"元组可见性"检测的。
T3 :
在T3时刻,当前表中只有Tuple_1,根据Rule6该tuple对所有事务可见;
T5 :
在T5时刻的情况有所不同,我们对两个事务分开讨论。
对于txid = 200的事务,此刻,我们可知Tuple_1是不可见的(根据Rule7),Tuple_2可见(根据Rule4);
因此,此时SELECT语句的返回结果为:
postgres=# -- txid 200
postgres=# SELECT * FROM tbl;
name
------
Hyde
(1 row)
对于txid = 201的事务,此刻,我们可知Tuple_1是不可见的(根据Rule8),Tuple_2同样不可见(根据Rule2);
因此,此时SELECT语句的返回结果为:
postgres=# -- txid 201
postgres=# SELECT * FROM tbl;
name
--------
Jekyll
(1 row)
我们可以看到,这里txid = 201的事务不会读取txid = 200的事务的未提交的更新,也就是回避了脏读问题。在PostgreSQL所有的事务隔离级别中都不会造成脏读。
T7 :
在T7时刻,只有txid = 201的事务还在运行,txid = 200的事务已经提交。现在我们分两种情况来讨论txid = 201的事务的行为。
-
1)txid = 201的事务的隔离级别为READ COMMITTED
此时由于txid = 200的事务已经提交,因此,此时重新获取的snapshot为 201:201: 。因此,我们可以知道Tuple_1是不可见的(根据Rule10),Tuple_2是可见的(根据Rule6),
因此,在READ COMMITTED级别下,SELECT语句的返回结果为:
postgres=# -- txid 201 (READ COMMITTED)
postgres=# SELECT * FROM tbl;
name
------
Hyde
(1 row)
我们可以看到,该事务在隔离级别为READ COMMITTED时,前后两次相同的SELECT获取的结果不同,也就是不可重复读。
-
2)txid = 201的事务的隔离级别为REPEATABLE READ
此时虽然txid = 200的事务已经提交,但是我们知道在REPEATABLE READ/SERIALIZABLE时,事务只在执行第一条命令时获取一次snapshot,因此,此时snapshot仍保持不变为 200:200: 。因此,我们可以知道Tuple_1是不可见的(根据Rule9),Tuple_2是可见的(根据Rule5),
因此,在READ COMMITTED级别下,SELECT语句的返回结果为:
postgres=# -- txid 201 (READ COMMITTED)
postgres=# SELECT * FROM tbl;
name
--------
Jekyll
(1 row)
我们可以看到,事务在隔离级别为REPEATABLE READ时,前后两次相同的SELECT获取的结果不变,即回避了不可重复读。
到这里,我们已经解决了解决了脏读和不可重复读的问题,那么还有一个幻读。然而幻读在PostgreSQL的事务在隔离级别为REPEATABLE READ时存在么?
我们知道,幻读的定义是:一个事务重新执行一个返回符合一个搜索条件的行集合的查询, 发现满足条件的行集合因为另一个最近提交的事务而发生了改变。
显然,在PostgreSQL中,由于快照隔离机制,我们继续上面的分析就能发现:在REPEATABLE READ/SERIALIZABLE隔离级别时消除了幻读(篇幅限制,我就不写了),即在从REPEATABLE READ开始就回避了幻读的问题,这和其它数据库上不太一样,PostgreSQL中提供的隔离级别更加严格。
关于这个系列,还剩下"如何避免Lost Update"和"SSI(Serializable Snapshot Isolation)"这两个问题没讨论,篇幅太长了,并不是写论文,容楼主喝口茶,留在下篇再说吧~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号