跟我一起读postgresql源码(十五)——Executor(查询执行模块之——control节点(上))
控制节点
控制节点用于完成一些特殊的流程执行方式。由于PostgreSQL为査询语句生成二叉树状的査询计划,其中大部分节点的执行过程需要两个以内的输入和一个输出。但有一些特殊的功能为了优化的需要,会含有特殊的执行方式和输人需求(例如对于update、INSERT和DELETE,在普通的SELECT基础上有一个ModifyTable节点,UNION操作在一个计划节点就执行多个表(大于2)的合并,Append节点并未把UNION涉及的多个表放在孩子节点中,而是将这些表组成一个链表放在Append节点的appendplans字段中,处理时依次处理该链表中的节点获取输入),这一类的节点被称为控制节点。下面给出了PostgreSQL中的控制节点列表。
T_ResultState,
T_ModifyTableState,
T_AppendState,
T_RecursiveUnionState,
T_BitmapAndState,
T_BitmapOrState,
1.Result节点
Result节点主有两种用途。
我们先讨论比较简单的一种情况。针对那些不扫描表的查询,例如:
postgres=# explain select 1+2;
QUERY PLAN
------------------------------------------
Result (cost=0.00..0.01 rows=1 width=0)
(1 row)
postgres=# explain insert into zxc values (1,'ddff');
QUERY PLAN
-------------------------------------------------
Insert on zxc (cost=0.00..0.01 rows=1 width=0)
-> Result (cost=0.00..0.01 rows=1 width=0)
(2 rows)
当SELECT査询中没有FROM子句时或者INSERT语句只有一个VALUES子句(这种情况我们在前面介绍ValueScan节点时提到过)时,执行査询计划不需要扫描表,执行器会直接计算SELECT的投影属性或者使用VALUES子句构造元组。
Result计划节点的另一种用途相对复杂点,是用来优化包含仅需计算一次的过滤条件,例如:
postgres=# explain select * from zxc where 1>2;
QUERY PLAN
-----------------------------------------------------------
Result (cost=0.00..22.70 rows=1 width=36)
One-Time Filter: false
-> Seq Scan on zxc (cost=0.00..22.70 rows=1 width=36)
(3 rows)
由于PostgreSQL采用了一次一元组的方式执行査询计划树,而WHERE子句中的条件表达式结果是常量,只需计算一次即可。因此,Result节点可针对此种情况进行优化,避免重复计算这类表达式。这时,Result节点仅有一个子节点(左子节点)。
为了能够处理以上两种情况,Result节点被定义成如下所示的样子,除了继承Plan节点的基
本属性外,还扩展定义了 resconstantqual字段。顾名思义,该字段保存只需计算一次的常量表达式。
typedef struct Result
{
Plan plan;
Node *resconstantqual;
} Result;
Result节点初始化过程(ExecInitResult函数)会初始化ResultSlate结构,该结构如下:
typedef struct ResultState
{
PlanState ps; /* its first field is NodeTag */
ExprState *resconstantqual;
bool rs_done; /* are we done? */
bool rs_checkqual; /* do we need to check the qual? */
} ResultState;
如果有常量表达式,则放置在resconstantqual字段中,而re_checkqual则用于标记是否需要计算常量表达式,re_done表示Result节点是否已经处理完所有元组。Result初始化过程在计划节点的标准初始化过程之外增加了几项检査:
-
1)保证无右子节点。
-
2)检査是否有常量表达式,有则将执行状态节点的rs_checkqual设置为真,否则设置为假。
Result节点的初始化函数ExecInitResult除了一些基础的初始化外,主要的就是初始化ResultState的rs_done、rs_checkqual和resconstantqual字段。后两个字段都是根据Result节点的resconstantqual字段来进行初始化的。
Result节点的执行函数ExecResult中,首先判断rs_checkqual是否为真,为真表示需要进行常量表达式计算,计算完成后将rs_checkqual设置为假,下次执行不会再进行计算。如果表达式计算结果为假,表示没有满足条件的结果,则Result节点直接返回NULL。若表达式计算结果为真,则会检査是否有左子树,有则从其中获取元组;没有左子树表示为VALUES子句,则直接设置rs_done为真,因为只有一个元组需要输出(这里的VALUES子句中只允许有一个元组)。最后对结果元组执行投影操作并返回。
对于Result节点的清理过程(ExecEndResult函数),由于不存在右子节点,所以只需调用左子节点的清理过程。
2.Append节点
Append节点用于处理包含一个或多个子计划的链表(如下图)。
...
/
Append -------+------+------+--- nil
/ \ | | |
nil nil ... ... ...
subplans
落实到查询计划里,我们看到的是这样的:
postgres=# explain select * from zxc union all select * from user_define_table ;
QUERY PLAN
----------------------------------------------------------------------------
Append (cost=0.00..45.40 rows=2540 width=36)
-> Seq Scan on zxc (cost=0.00..22.70 rows=1270 width=36)
-> Seq Scan on user_define_table (cost=0.00..22.70 rows=1270 width=36)
(3 rows)
Append处理过程会逐个处理这些子计划(forwards or backwards),当一个子计划返回了所有的结果后,会接着执行链表中的下一个子计划,直到链表中的所有子计划都被执行完。从这种执行方式可知,Append节点不使用左右孩子节点。其特点就在于依次执行子计划链表(见下图)。该节点可用于处理包含多个子査询的UNION操作,以及支持继承查询(在含有继承表的查询中,查询需要scan父表和子表)。
这里student表和employee继承自person表,student-emp继承自student表和employee表,
那么对于查询: select name from person;
查询计划类似如下:
|
Append -------+-------+--------+--------+
/ \ | | | |
nil nil Scan Scan Scan Scan
| | | |
person employee student student-emp
Append节点的定义如下所示,很简单。它在Plan节点的基础上扩展定义了 appendplans字段,其中appendplans用于存储子计划链表。
typedef struct Append
{
Plan plan;
List *appendplans;
} Append;
Append节点的初始化过程(ExecInitAppend函数)会初始化AppendState节点,然后初始化子计划链表中的每一个子计划,并将它们的状态记录节点组织成一个数组,使AppendState节点的appendplans 字段指向该数组。 as_nplans 记录 Append 节点中子计划链表的长度, as_whichplan 则用于在执行中指示当前处理的子计划在链表中的偏移量.
typedef struct AppendState
{
PlanState ps; /* its first field is NodeTag */
PlanState **appendplans; /* array of PlanStates for my inputs */
int as_nplans; /* how many plans are in the array */
int as_whichplan; /* which plan is being executed (0 .. n-1) */
} AppendState;
Append节点的执行过程也很简单。该过程由ExecAppend函数完成。它会首先从as_whichplan标记的子计划开始执行,如果返回的元组非空,则直接返冋结果。如果当前子计划返回的是空元组,那么会将as_whichPlan移动到下一个子计划(因为执行过程可以向前和向后扫描,向前扫描为加1,反之减1),并继续执行当前子计划。倘若已经没有下一个子计划可以处理,则直接返回空元组。
由于没有左右孩子节点,Append节点清理工作(ExecEndAppend函数)不需要递归调用左右子节点的清理过程,而是扫描整个子计划链表,依次调用子计划的清理函数。
3.BitmapAnd/BitmapOr节点
BitmapAnd和BitmapOr都是位图(Bitmap)类型节点,用于位图计算。
先上例子:
EXPLAIN SELECT * FROM tenk1 WHERE unique1 < 100 AND unique2 > 9000;
QUERY PLAN
-------------------------------------------------------------------------------------
Bitmap Heap Scan on tenk1 (cost=25.08..60.21 rows=10 width=244)
Recheck Cond: ((unique1 < 100) AND (unique2 > 9000))
-> BitmapAnd (cost=25.08..25.08 rows=10 width=0)
-> Bitmap Index Scan on tenk1_unique1 (cost=0.00..5.04 rows=101 width=0)
Index Cond: (unique1 < 100)
-> Bitmap Index Scan on tenk1_unique2 (cost=0.00..19.78 rows=999 width=0)
Index Cond: (unique2 > 9000)
首先介绍一个位图运算的例子。在使用索引扫描表时,可用位图来标识满足扫描条件的元组(Bitmap Index Scan),即将满足条件的元组的对应位置1,这样就可以使用位图来表示整个表中满足扫描条件的元组。当一个表上有多个属性约束且都有索引时,可以利用各个索引分别扫描得到满足对应属性约束的结果位图,然后根据多个属性约束上的逻辑关系对位图进行与或运算得到最终的结果位图。
如下图所示,假设表有属性attrA和attrB,且分别建立了索引。如果需要进行的査询中有条件“(涉及attrA的条件)AND (涉及attrB的条件)”,则可以首先利用第一个条件扫描属性attrA上的索引并构建位图Bitmap A,其中每一位对应表中的一个元组,如果元组对应的位为1表示该元组满足条件。用同样的方法利用attrB上的索引构建位图Bitmap B。由于两个属性的约束间是“与”关系,因此可以对两个位图进行AND操作,从而得到Bitmap AB,其中值为1的位表示对应的元组同时满足A、B两属性上约束。
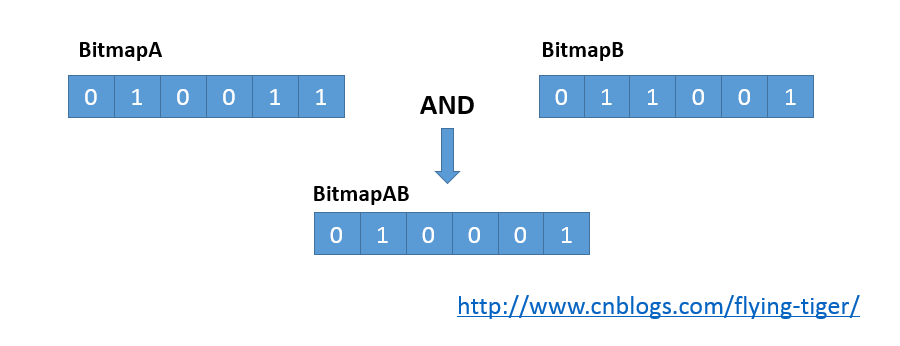
BitmapAnd和BitmapOr节点实现了两个或多个位图的“与”和“或”运算。这两个节点的数据组织类似于Append节点,将产生每一个位图的子计划放在一个链表里,在执行过程中先执行子计划节点获取位图,然后进行“与”(“或”)操作。下面给出了 BitmapAnd节点(BitmapOr节点的也类似)的数据结构,它们都有一个子计划的链表(bitmapplans字段)。但和Append节点不同之处在于这两个节点的子计划返回的是位图,而不是元组,因此,该节点不出现在ExecProcNode函数的判断条件中(该函数中只涉及返回元组的计划节点)。
typedef struct BitmapAnd
{
Plan plan;
List *bitmapplans;
} BitmapAnd;
typedef struct BitmapAndState
{
PlanState ps; /* its first field is NodeTag */
PlanState **bitmapplans; /* array of PlanStates for my inputs */
int nplans; /* number of input plans */
} BitmapAndState;
Bitmap类节点的初始化过程(ExecInitBitmapAnd和ExecInitBitmapOr函数)将初始化BitmapAndState/BitmapOrState节点,其过程与AppendState节点类似,状态节点定义中也扩展了子计划链表对应的状态节点指针数组bitmapplans以及子计划个数nplans。Bitmap类节点执行时也是依次获取每个子计划的位图,进行号/或操作,并将结果位图返回。其清理过程也是依次调用每个子计划的清理过程,而不会处理未使用的左右子节点。
总之,该节点和Append很类似,我就不多说了。
4.RecursiveUnion节点
RecursiveUnion节点用于处理递归定义的UNION语句。下面给出一个例子,使用SQL语句定义从1到100求和,査询语句如下:
postgres=# explain WITH RECURSIVE t(n)AS(
VALUES (1)
UNION ALL
SELECT n +1 FROM t WHERE n < 100)
select sum(n) FROM t;
QUERY PLAN
-------------------------------------------------------------------------
Aggregate (cost=3.65..3.66 rows=1 width=4)
CTE t
-> Recursive Union (cost=0.00..2.95 rows=31 width=4)
-> Result (cost=0.00..0.01 rows=1 width=0)
-> WorkTable Scan on t t_1 (cost=0.00..0.23 rows=3 width=4)
Filter: (n < 100)
-> CTE Scan on t (cost=0.00..0.62 rows=31 width=4)
(7 rows)
该査询定义了一个临时表并将VALUES子句给出的元组作为t的初始值,“SELECT n + 1 FROM t WHERE n < 100”将t中属性n小于100的元组的n值加1并返回,UNION ALL操作将SELECT 语句产生的新元组集合合并到临时表 t 中。 以上的 SELECT 和 UNION 操作将递归地执行下去,直到SELECT语句没有新元组输出为止。最后执行 “SELECT sum (n) FROM t” 对 t 中元组的n值做求和操作。
上述査询由RecursiveUnion节点处理。有一个初始输入集作为递归过程的初始数据(如上例中“VALUES(1)”),然后进行递归部分(上例中的“SELECTn + 1 FROM t WHERE n < 100”)的处理得到输出,并将新得到的输出与初始输入合并后作为下次递归的输入(例如第一次递归处理时新的输出集为{2},与初始输入合并后为{1, 2})。
RecursiveUnion节点的数据结构如下所示,它在Plan的基础上扩展定义了wtParam字段用于与WorkTableScan(负责对临时表的扫描,即递归部分的査询语句的执行,我在前面文章提到过)传递参数。执行中RecursiveUnion与WorkTableScan之间的参数传递是通过Estate中es_param_exec_vals指向的参数数组完成的,wtParam表示传递的参数在该数组中的偏移量。
其他四个扩展属性(numCols、dupColIdx、dupOperators 和 numGroups)用于 UNION 时不包含关键字ALL的情况:
- munCols存储了用于去重判断的属性个数;
- dupColIdx数组记录用十去重判断的属性号;
- dupOperatore数组记录了用于判断各属性是否相同的函数的OID;
- numGroups记录了结果元组数的估计值。
typedef struct RecursiveUnion
{
Plan plan;
int wtParam; /* ID of Param representing work table */
/* Remaining fields are zero/null in UNION ALL case */
int numCols; /* number of columns to check for
* duplicate-ness */
AttrNumber *dupColIdx; /* their indexes in the target list */
Oid *dupOperators; /* equality operators to compare with */
long numGroups; /* estimated number of groups in input */
} RecursiveUnion;
RecursiveUnion节点的初始化过程(ExecInitRecursiveUnion函数)除标准初始化过程外,首先会根据numCols是否为0来辨别是否需要在合并时进行去重。如果需要去重,则根据dupOpemtors字段初始化RccursiveUnionState节点的eqfunctions和hashfunctions字段,同时申请两个内存上下文用于去重操作,并创建去重操作用的Hash表。另外,还将为RecureiveUnionState节点的working_table和intermediate_table字段初始化元组缓存结构。
typedef struct RecursiveUnionState
{
PlanState ps; /* its first field is NodeTag */
bool recursing; /* True when we're done scanning the non-recursive term */
bool intermediate_empty; /* True if intermediate_table is currently empty */
Tuplestorestate *working_table; /* working table (to be scanned by recursive term) */
Tuplestorestate *intermediate_table; /* current recursive output (next generation of WT) */
/* Remaining fields are unused in UNION ALL case */
FmgrInfo *eqfunctions; /* per-grouping-field equality fns */
FmgrInfo *hashfunctions; /* per-grouping-field hash fns */
MemoryContext tempContext; /* short-term context for comparisons */
TupleHashTable hashtable; /* hash table for tuples already seen */
MemoryContext tableContext; /* memory context containing hash table */
} RecursiveUnionState;
RecursiveUnion节点的执行过程(ExecRecursiveUnion函数)如下:
首先执行左子节点计划,将获取的元组直接返回。如果需要去重,则箱要把返回的元组加入到hashtable中。同时,将初始集存储在working_table指向的元组缓存结构中。
当处理完毕所有的左子节点计划后,会执行右子节点计划以获取结果元组。其中,右子节点计划中的WorkTableScan会以working_table为扫描对象。右子节点计划返回的结果元组将作为RecursiveUnion节点的输出,同时缓存在另一个元组存储结构intermediate_table中。每当woridng_table被扫描完毕,RecursiveUnion节点的执行流程会将intermediate_table 赋值给 working_table,然后再次执行右子节点计划获取元组,直到无元组输出为止。同样,如果需要去重,右子节点计划的所有输出也会被存入同一个Hash表(hashlable),若重复则不会输出。
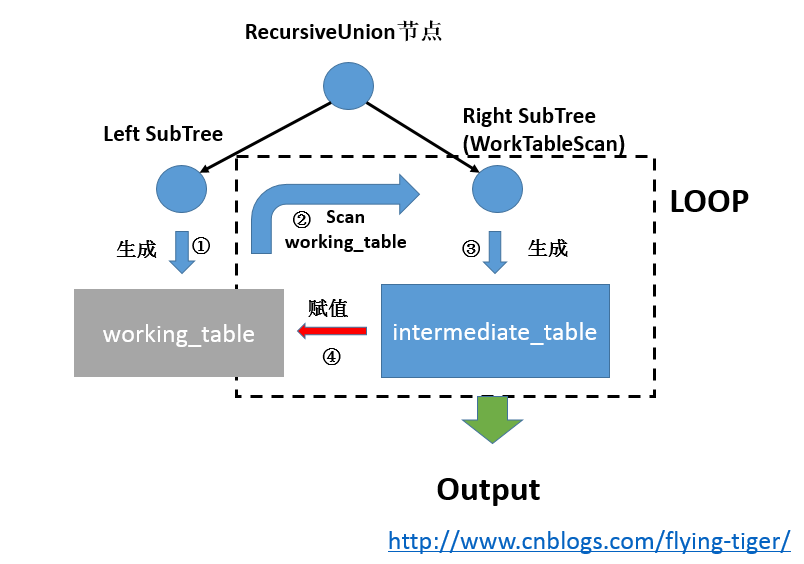
在RecursiveUnion节点的清理过程中,除了对子节点完成递归清理和状态节点的清理外,还会针对初始化中创建的各种数据结构进行清理,例如清理working_table和intermediate_table两个元组缓存结构,以及去重操作时用到的内存上下文。
还剩下一个ModifyTable节点。这个节点比较复杂,涉及到Update、Insert和Delete操作的处理。我们下一篇再见吧~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号