浅谈postgresql的GIN索引(通用倒排索引)
1.倒排索引原理
倒排索引来源于搜索引擎的技术,可以说是搜索引擎的基石。正是有了倒排索引技术,搜索引擎才能有效率的进行数据库查找、删除等操作。在详细说明倒排索引之前,我们说一下与之相关的正排索引并与之比较。
1.1正排索引
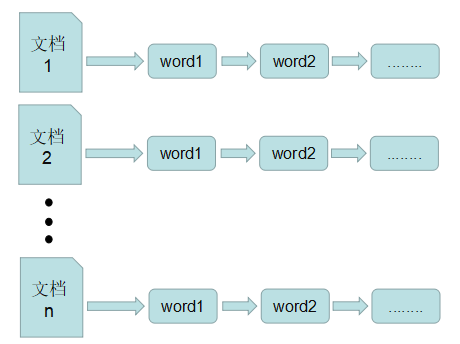
在搜索引擎中,正排表是以文档的ID为关键字,表中记录文档中每个字的位置信息,查找时扫描表中每个文档中字的信息直到找出所有包含查询关键字的文档。
正排表结构如图1所示,这种组织方法在建立索引的时候结构比较简单,建立比较方便且易于维护;因为索引是基于文档建立的,若是有新的文档加入,直接为该文档建立一个新的索引块,挂接在原来索引文件的后面。若是有文档删除,则直接找到该文档号文档对应的索引信息,将其直接删除。但是在查询的时候需对所有的文档进行扫描以确保没有遗漏,这样就使得检索时间大大延长,检索效率低下。
尽管正排表的工作原理非常的简单,但是由于其检索效率太低,除非在特定情况下,否则实用性价值不大。
1.2倒排索引
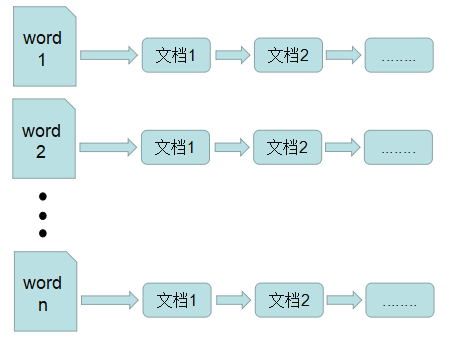
倒排表以字或词为关键字进行索引,表中关键字所对应的记录表项记录了出现这个字或词的所有文档,一个表项就是一个字表段,它记录该文档的ID和字符在该文档中出现的位置情况。
由于每个字或词对应的文档数量在动态变化,所以倒排表的建立和维护都较为复杂,但是在查询的时候由于可以一次得到查询关键字所对应的所有文档,所以效率高于正排表。在全文检索中,检索的快速响应是一个最为关键的性能,而索引建立由于在后台进行,尽管效率相对低一些,但不会影响整个搜索引擎的效率。
倒排表的结构图如下图
2.postgresql中的倒排索引
2.1 概述
GIN(Generalized Inverted Index, 通用倒排索引)是一个存储对(key, posting list)集合的索引结构,其中key是一个键值,而posting list 是一组出现过key的位置。如(‘hello’, ’14:2 23:4’)中,表示hello在14:2和23:4这两个位置出现过,在PG中这些位置实际上就是元组的tid。
在表中的每一个属性,在建立索引时,都可能会被解析为多个键值,所以同一个元组的tid可能会出现在多个key的posting list中。
通过这种索引结构可以快速的查找到包含指定关键字的元组,因此GIN索引特别适用于支持全文搜索,而PG的GIN索引模块也就是为了支持全文搜索而开发的。
2.2 扩展性
GIN索引具有很好的可扩展性,允许在开发自定义数据类型时由该数据类型的领域专家(而非数据库专家)设计适当的访问方法,这些访问方法只需考虑对于数据类型本身的语义处理,GIN索引自身可以处理并发控制、日志记录、搜索树结构等操作。
定义一个GIN访问方法所要做的就是实现3个用户定义的方法,这些方法定义了键值、键值与键值之间的关系、被索引值、能够使用索引的查询以及部分匹配。这些方法是:
int compare(Datum a, Datum b)
比较两个键(不是被索引项)并且返回一个整数,整数可以是小于零、零、大于零, 分别表示第一个键小于、等于、大于第二个键。空值键不会被传递给这个函数。
Datum *extractValue(Datum itemValue, int32 *nkeys, bool **nullFlags)
根据参数inputValue生成一个键值数组,并返回其指针,键值数组中元素的个数存放在另一个参数nkeys中。
Datum *extractQuery(Datum query, int32 *nkeys, StrategyNumber n, bool
**pmatch, Pointer **extra_data, bool **nullFlags, int32 *searchMode)
根据参数query生成一个用于查询的键值数组,并返回其指针。
extractQuery通过参数n指定的操作符策略号来决定query的数据类型以及需要提取的键值,返回键值数组的长度存放在nkeys参数中。如果query中不包含键值,则nkeys可以为0或者-1:nkeys = 0 表示索引中所有值都满足查询,将执行完全索引扫描(查询null时是这样); nkeys = -1 表示索引中没有键值满足查询,跳过索引扫描。
在部分匹配时,输出参数pmatch记录返回的键值数组中的每一个键值是否请求部分匹配。
输出参数extra_data用来向consistent和comparPartial方法传递用户自定义需要的数据。
一个操作符类必须提供一个函数检查一个被索引的项是否匹配查询。有两种形式, 一个布尔函数consistent,以及一个三元函数triConsistent。 triConsistent覆盖了两者的功能,因此提供一个足矣。但是, 如果布尔函数的计算代价要更低,两者都提供就会有好处。如果只提供布尔变体, 一些基于在取得所有键之前拒绝索引项的优化将会被禁用。
bool consistent(bool check[], StrategyNumber n, Datum query, int32 nkeys, Pointer extra_data[], bool *recheck, Datum queryKeys[], bool nullFlags[])
如果一个被索引项满足(如果重新检查指示被返回,则表示可能满足)有策略号 n的查询操作符,则返回 TRUE。
GinTernaryValue triConsistent(GinTernaryValue check[], StrategyNumber n, Datum query, int32 nkeys, Pointer extra_data[], Datum queryKeys[], bool nullFlags[])
triConsistent类似于consistent,但不是一个布尔的 check[],对每个键有三种可能值:GIN_TRUE、 GIN_FALSE和GIN_MAYBE。GIN_FALSE和 GIN_TRUE具有和常规布尔值相同的含义。GIN_MAYBE 意味着键的存在未知。当GIN_MAYBE值出现时,如果项匹配 (不管该索引项是否包含对应的查询键),该函数应该只返回 GIN_TRUE。 同样地,如果项不匹配(不管它是否包含 GIN_MAYBE 键),该函数必须只返回 GIN_FALSE。 如果结果依赖于 GIN_MAYBE 项,即无法根据已知查询键确认或拒绝匹配, 该函数必须返回 GIN_MAYBE。
int comparePartial(Datum partial_key, Datum key, StrategyNumber n, Pointer extra_data)
将部分匹配的查询与索引值进行比较,返回值为负值表示两者不匹配,但继续索引扫描;返回值为0表示两者匹配;返回值为正值表示停止扫描。
要支持"部分匹配"查询,一个操作符类必须提供comparePartial 方法,并且它的extractQuery方法必须在遇到一个部分匹配查询时设置 pmatch参数
所以在PG中添加一种新的数据类型并且让GIN支持该数据类型,则需要完成以下步骤:
1.添加数据类型
2.为新数据类型实现并注册各种操作符所需要的函数,然后创建新类型的操作符
3.用CREATE OPERATOR CLASS为新的数据类型创建一个操作符类,该语句需要指定GIN索引所需要的3个支持函数
对以上的函数云里雾里? 我建议你可以看看contrib\cube模块。这个模块实现了一种数据类型cube来表示多维立方体。同样他实现了以上3个函数(虽然针对的是gist和b-tree,但是大体相似)。
2.3 GIN索引结构
2.3.1 逻辑结构
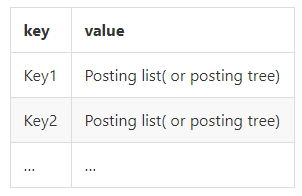
GIN索引在逻辑上可以看成一个relation,该relation有两种结构:
- 只索引基表的一列
- 索引基表的多列(复合、多列索引)
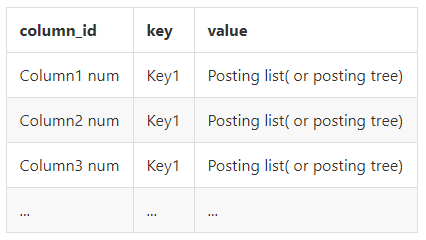
那我们可以知道在这种结构下,对于基表中不同列的相同的key,在GIN索引中也会当作不同的key来处理。
2.3.2 物理结构
GIN索引在物理存储上包含如下内容:
1. Entry:GIN索引中的一个元素,可以认为是一个词位,也可以理解为一个key
2. Entry tree:在Entry上构建的B树
3. posting list:一个Entry出现的物理位置(heap ctid, 堆表行号)的链表
4. posting tree:在一个Entry出现的物理位置链表(heap ctid, 堆表行号)上构建的B树,所以posting tree的KEY是ctid,而entry tree的KEY是被索引的列的值
5. pending list:索引元组的临时存储链表,用于fastupdate模式的插入操作
从上面可以看出GIN索引主要由Entry tree和posting tree(or posting list)组成,其中Entry tree是GIN索引的主结构树,posting tree是辅助树。
entry tree类似于b+tree,而posting tree则类似于b-tree。
另外,不管entry tree还是posting tree,它们都是按KEY有序组织的。
2.4 GIN索引的insert和fastupdate优化
GIN索引的插入操作与btree索引不同,对于btree索引,基表增加一行,btree索引也是增加一个索引项。而对于GIN索引基表增加一行,GIN索引可能需要增加多个索引项。所以GIN索引的插入是低效的。所以PG为了解决这个问题,实现了两种插入模式:
2.4.1. 正常模式
在该模式下,基表元组产生的新的GIN索引,会被立即插入到GIN索引
2.4.2. fastupdate模式
在该模式下,基表元组产生的新的GIN索引,会被插入到pending list中,而pending list会在一定条件下批量的插入到GIN索引中
下面就说明一下fastupdate模式的插入。
2.4.2.1 开启和关闭fastupdate模式
可以通过create index 的WITH FASTUPDATE = OFF来关闭fastupdate模式,默认情况下是开启fastupdate模式
2.4.2.2 对索引扫描的影响
在fastupdate模式下,新的索引元组以追加的方式插入到pending list中,不会进行任何的排序和去重操作,所以,在扫描时,只能顺序扫描,因此pending list的扫描效率是非常低的,必须保证pending list的大小不要太大
2.4.2.3 对插入的影响
通常情况下,在fastupdate模式下,基表的更新效率是比较高的,但是如果一个事务的更新刚好让pending list到达临界点,而导致合并操作,则会使该事务比正常的事务慢很多
2.4.2.4 pending list的合并
把pending list的索引元组合并到GIN索引树上有2种触发条件:
- 当pending list所占空间大于work_mem时
PS(有gin_pending_list_limit参数的版本,通过gin_pending_list_limit参数来控制,而非work_mem)
- 在vacuum 索引的基表时(包括autovacuum在内)
因此可以根据autovacuum的间隔时间和work_mem来控制pending list的大小,避免其过大而拖慢扫描速度
在pending list合并时,其采用与GIN索引构建时相同的方式,即先把pending list内的数据,组织成一个RB树,然后再把RB树合并到GIN索引上。RB树可以把pending list中无序的数据变成有序,并且可以合并重复key的项,提高插入效率。
2.5 GIN索引的vacuum
GIN索引的vacuum是用来清理无用的posting list或者posting tree的,GIN索引的vacuum与btree索引的vacuum一样,提供了两个接口ginbulkdelete和ginvacuumcleanup。
GIN索引的vacuum主要是清理entry tree和posting tree,如果entry的posting list为空了,vacuum依然不会删除该entry,说明entry tree中的entry永远不会被删除;对于posting tree,如果posting tree也空了,在系统依然会把posting tree的root页面保留,并关联到entry上面。
3.小结
这篇文章主要开个头,同时也主要是一篇学习笔记,下一篇会多写写自己的理解,会着重从代码角度解读GIN索引以及分析实例等。
敬请期待~
引用如下:
https://yq.aliyun.com/articles/69250#
http://www.cnblogs.com/maybe2030/p/4791611.html
https://my.oschina.net/Kenyon/blog/366505

 浙公网安备 33010602011771号
浙公网安备 33010602011771号