------ 解析因内核栈溢出导致的 “double fault” 蓝屏 ------
——————————————————————————————————————————————————————————————————————————
前一篇指出 tail_recursivef_factorial() 会递归调用自身来计算某个正整数的阶乘。当要计算的目标数值过大,经历多次调用后,
就会耗尽可用的内核栈,引发一次页错误异常,而转移控制到错误处理程序前再次向无效的内存地址压入“陷阱帧”则会让原本可
以处理的异常升级为“double fault”,致使系统崩溃。本篇通过试图计算 685! 来触发“double fault”并进行分析。
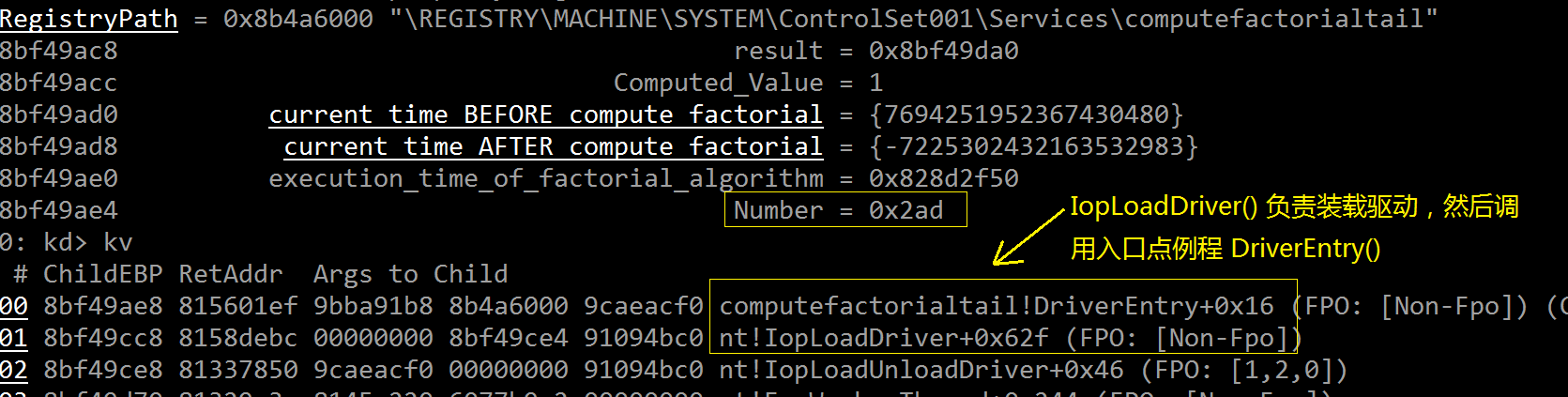
将编译好的驱动拷贝到被调试机器上,利用 sc.exe 把它加载至内核空间,源码中(参见上一篇)设置的初始断点被激活从而断入
调试机上的 WinDbg.exe,观察驱动入口点“DriverEntry()”内的局部变量,其中“Number”的值 0x2ad 正是要计算阶乘的数
685:
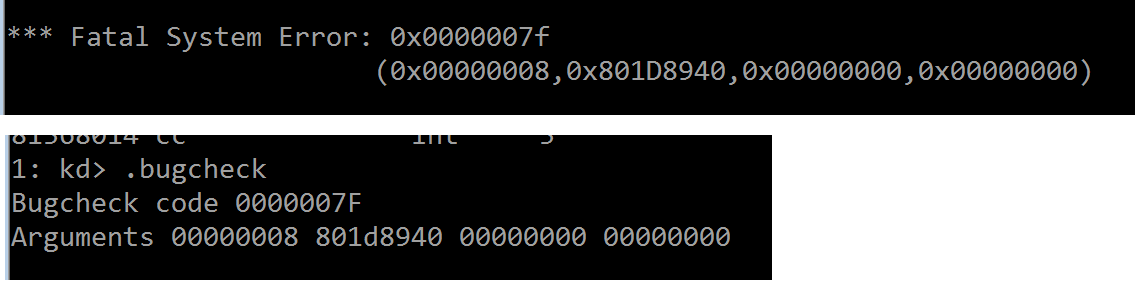
按下“g”键恢复执行,没多久就让系统崩溃了,这在我们的意料之中,如果没有连接宿主机上的调试器,目标系统就会直接
蓝屏,并且显示“bug check”代码——0000007F:
在 MSDN 网站上搜索该错误码,它对应于“UNEXPECTED_KERNEL_MODE_TRAP”,官方给出的解释如下:
The UNEXPECTED_KERNEL_MODE_TRAP bug check has a value of 0x0000007F.
This bug check indicates that the Intel CPU generated a trap and the kernel failed to catch this trap.This trap could be a bound trap (a trap the kernel is not permitted to catch) or a double fault
(a fault that occurred while processing an earlier fault, which always results in a system failure).这种错误是由于 Intel CPU 生成了一个陷阱(trap),而内核未能捕获这个陷阱。
此陷阱可能是一个受困陷阱(内核不允许捕获的陷阱),或一个“double fault”(当处理一个早先的错误时又出现一个错误,
这样就总是会导致系统故障)。
原文描述中的后一种情况(处理错误时又发生另一个错误)就是我们此刻的处境。
UNEXPECTED_KERNEL_MODE_TRAP 有四个参数,你可以从上一张图看到,首个参数值为“0x00000008(陷阱编号)”,
官方对该值的解释为:
0x00000008, or Double Fault, indicates that an exception occurs during a call to the handler for a prior exception.
Typically, the two exceptions are handled serially.
However, there are several exceptions that cannot be handled serially,
and in this situation the processor signals a double fault. There are two common causes of a double fault:A kernel stack overflow. This overflow occurs when a guard page is hit, and the kernel tries to push a trap frame.
Because there is no stack left, a stack overflow results, causing the double fault.
If you think this overview has occurred, use !thread to determine the stack limits, and then use kb
(Display Stack Backtrace) with a large parameter (for example, kb 100) to display the full stack.A hardware problem.
“Double Fault”,指明在调用前一个异常处理程序期间,又出现了一个异常。一般而言,两个异常是顺序处理的。
然而,有一些异常无法顺序处理,在这种情况下处理器就会发出一个“double fault”信号。有两种常见情况会导致
“double fault”:1。一次内核栈溢出。当接触到一个保护页时就会发生此类溢出,然后内核试图向其中压入一个陷阱帧。
因为已经没有剩余栈可用了,导致又一次栈溢出,造成“double fault”。如果你认为发生了这种溢出,利用“!thread”调试器
命令确定栈界限,然后使用“kb”(显示栈回溯)命令,并带着较大的参数(比如 kb 100)来显示完整的栈。2。硬件问题
遵循原文的指示,我们先检查当前线程的栈界限,然后执行栈回溯看是否真的越界了,如下图所示,内核栈边界在 8bf47000 处,
而发生异常前的最后一次递归调用的帧指针(ChildEBP)为 8bf47008 ,已经快要出界了:
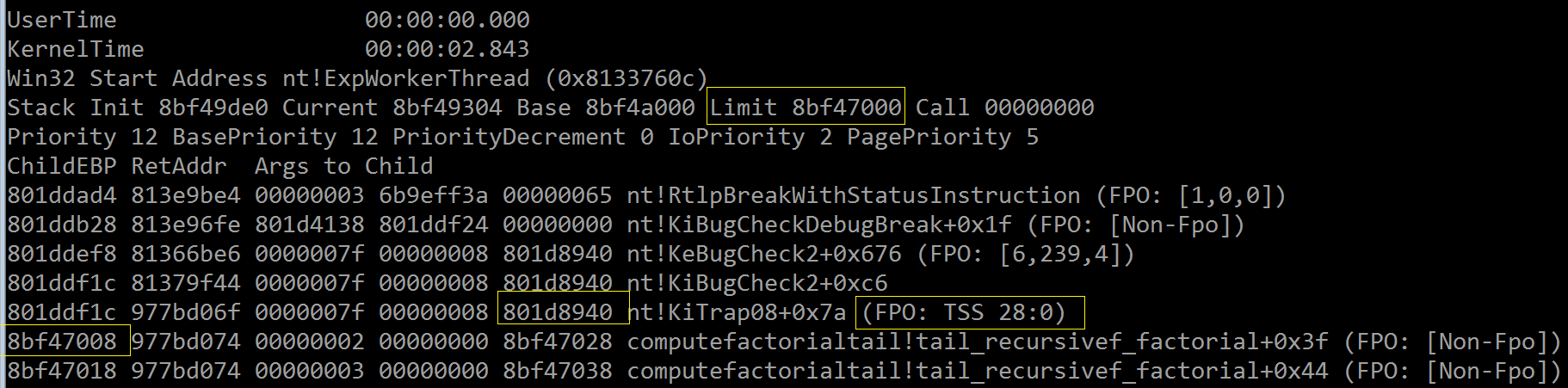
“nt!KiTrap08”是实际的陷阱处理程序,有趣的是前面的陷阱编号(0x00000008)就在这个例程的名字中,这绝不是巧合,
实际上“nt!KiTrap08”就是“double fault”专用的异常处理程序!
传递给它的第三个参数“801d8940”同时也就是 UNEXPECTED_KERNEL_MODE_TRAP 的第二个参数,它是一
个“nt!_NT_TIB”结构的“SubSystemTib”字段值:
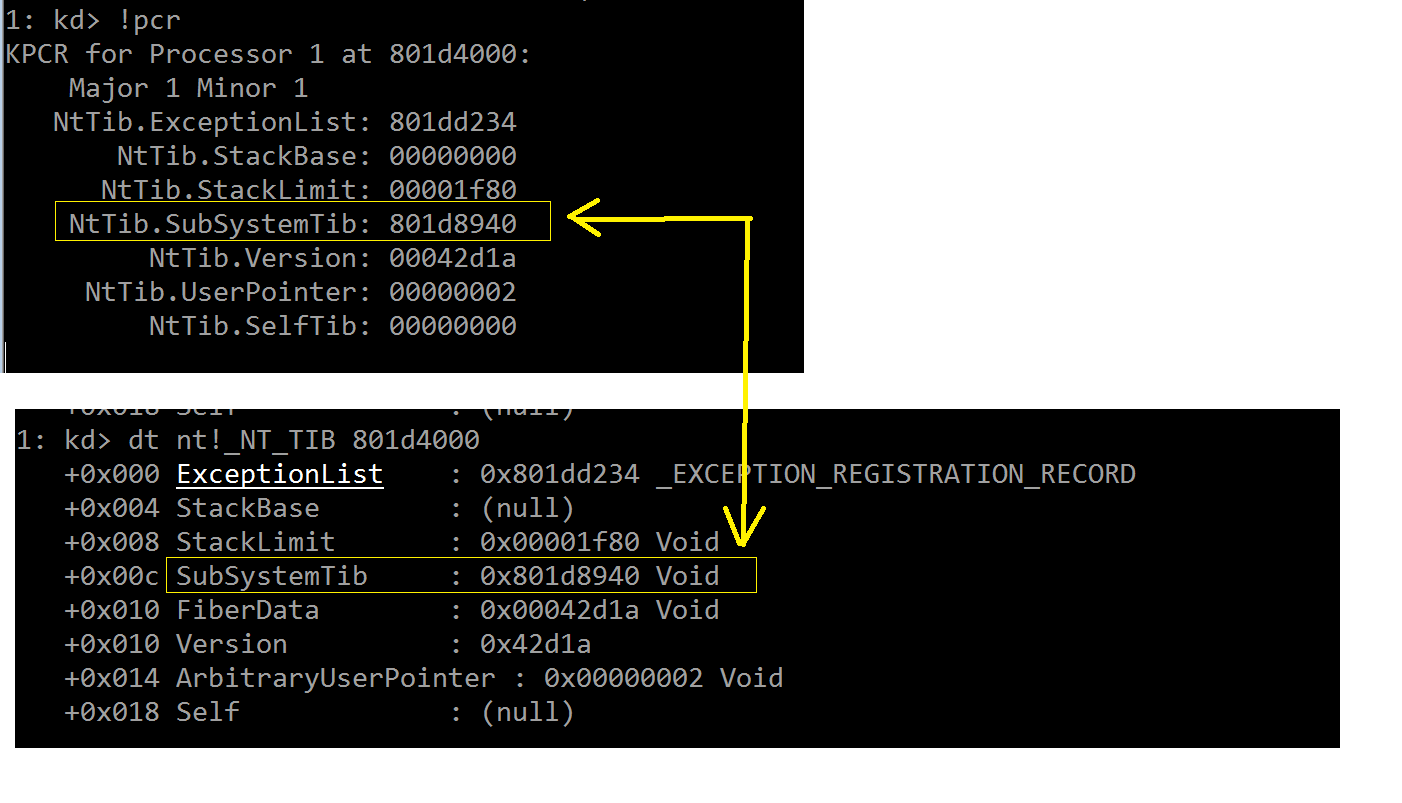
其实这个字段中包含的信息对于我们此刻的故障排查而言并不那么重要,只是怕有人好奇它的来龙去脉,才略作说明罢了。
上图中的 nt!KiTrap08 栈帧名称后面给出了一个 TSS(任务状态段)的段选择符为 28。这才是关键的信息,通过它可会回到
事故现场,分析异常发生时的上下文。这个段选择符存储在“nt!_KTSS”结构的首个字段(Backlink)内:
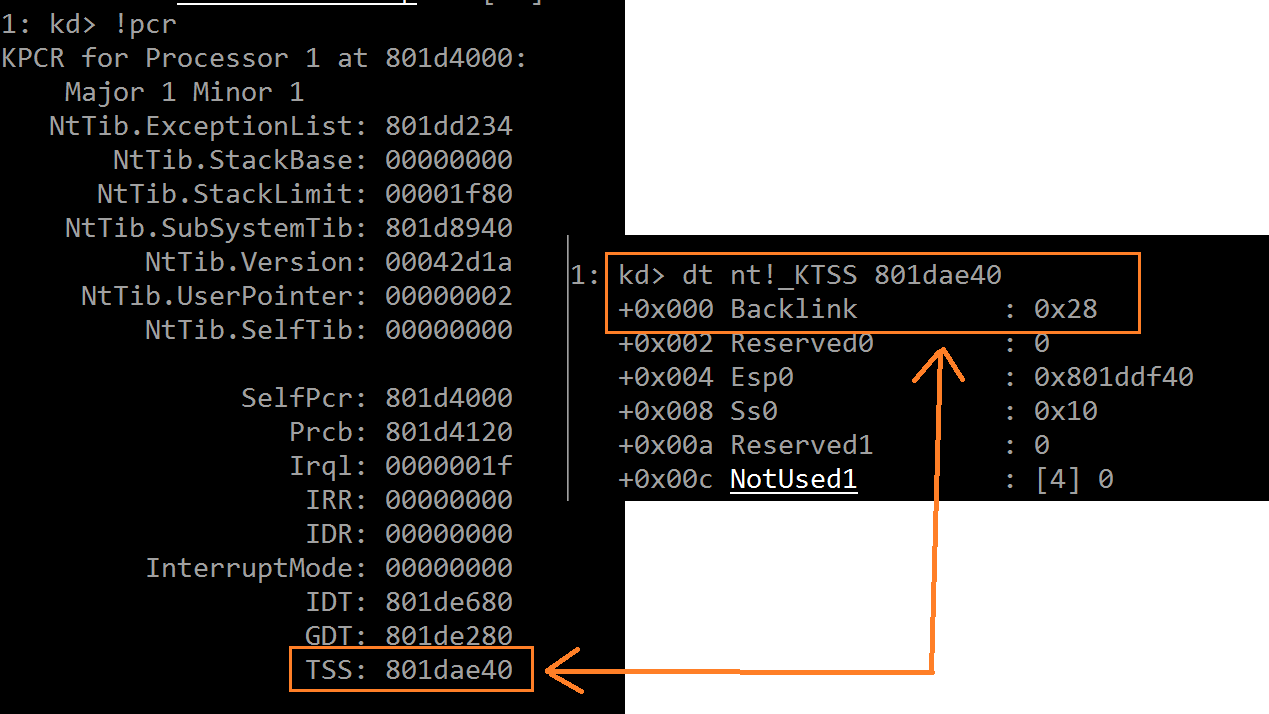
看到这里应该能够稍稍体会出内核中相关数据结构设计的多么用心良苦!
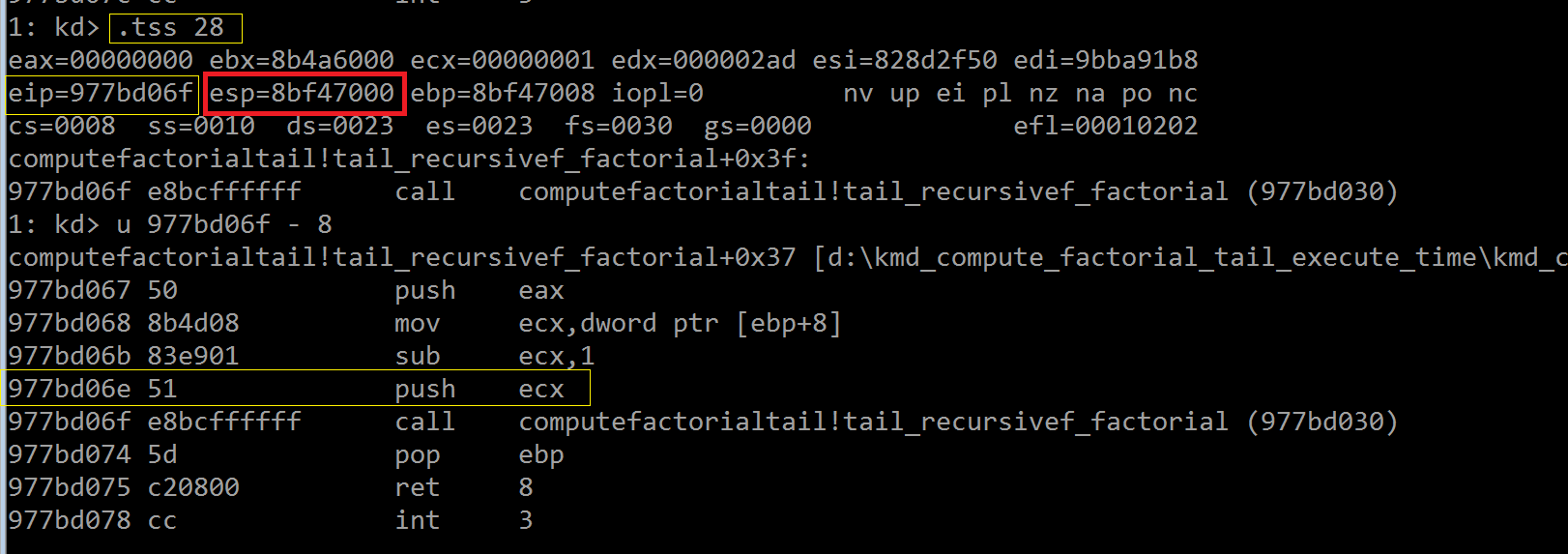
放下我们的多愁善感,利用调试器的“.tss”命令,后接段选择符,即可回到事故现场,如下所示,异常发生时,EIP 指向即将执行
的指令地址为 977bd06f,换言之是该地址处的“前一条”指令(push ecx)导致的异常,为啥这条压栈指令会导致异常呢?
你看“那时”的 esp 已经指向了内核栈的边界点(8bf47000),而压栈指令需要先把 esp 值减去 4 字节,然后再把 ecx 的内容
写入 8BF46FFC 地址处,该地址已经位于边界之外。
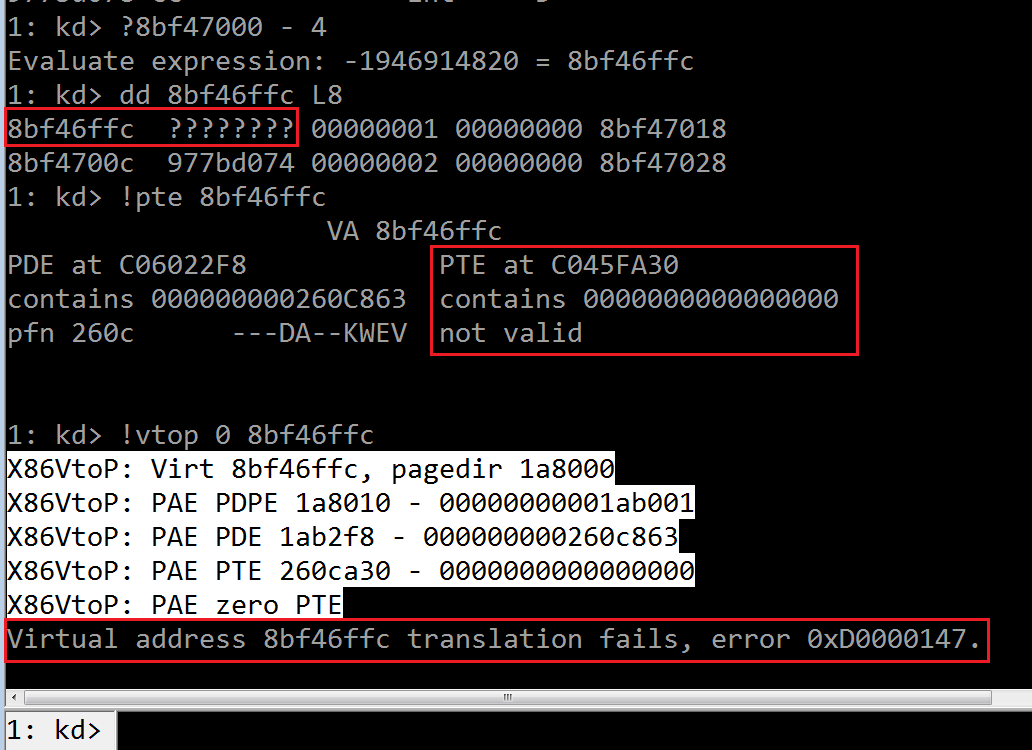
还记得前一篇我们计算出每次递归调用都会消耗掉 16 字节的内核栈空间吗?这出错前的最后一次调用中,试图消耗的最后 4 字节
就在边界之外!
低于 8bf47000 的虚拟内存没有分配实际的物理页,而且我们模拟对 8BF46FFC 执行物理地址转译也失败,证实是由于访问到
无效地址引发异常的(CR2 寄存器存储导致页错误的访问地址):

如前所述,页错误发生后,在控制权转移到 nt!KiTrap08 之前,再次向这个无效的地址压入一张“陷阱帧”,导致再度出现错误,
而 nt!KiTrap08 通过传递给它的首个参数(0x0000007f)明白了这是一个“double fault”,所以调用 nt!KiBugCheck,后者
探测调试器是否存在,决定是要绘制蓝屏还是断入调试器。这就是前面那张栈回溯输出的由来!
执行“kv 1000”回溯大范围的栈帧,你可以看到 683 次(栈帧编号 0x2b0 - 5)对 tail_recursivef_factorial() 的调用,在
我们的预测点(685 号栈帧)之前就发生了溢出:

最后介绍一个强大的命令“!analyze -v”,它会自动分析内核崩溃的原因,并给出所有对故障排除有帮助的信息,对于本例而言,
有价值的信息截图如下:
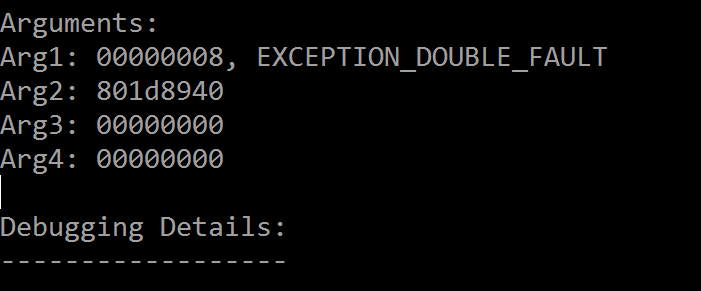

—————————————————————————————————————————————————————
小结:本篇以源码+调试+在线文档等综合手段排除了“double fault”蓝屏故障;编写驱动并上机调试是理解内核设计思想
的最佳途经!
—————————————————————————————————————————————————————
posted on 2018-02-19 22:03 f1yin9_0x5hark 阅读(4594) 评论(1) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号