------ 新春第一炮:阶乘算法性能分析与 double fault 蓝屏故障排查 Part I ------
——————————————————————————————————————————————————————————————————————————
春节期间闲来无事想研究下算法,上机测试代码却遇到了意外错误,在此记录整个过程,祝各位新的一年在算法设计和故障排查方
面的思维敏锐度媲美 dog 的嗅觉!
——————————————————————————————————————————————————————————————————————————
整数 n 的阶乘(factorial)记作“n!”,比如要计算 5!,那么就是计算 5 * 4 * 3 * 2 * 1 = 120。
在 32 位系统上,“unsigned int(ULONG)”型变量能够持有的最大 10 进制值为 4,294,967,295(FFFF FFFF),意味着无符号数最多只能用来计算
12!(479,001,600 = 1C8C FC00);若计算 13!(6,227,020,800 = 1 7328 CC00)就会发生溢出。
类似地,“int”型变量能够持有的最大 10 进制值为 2,147,483,647(7FFF FFFF),意味着有符号数最多也只能用来计算
12!;若计算 13! 就会发生下溢(8000 0000 = -2,147,483,648)。
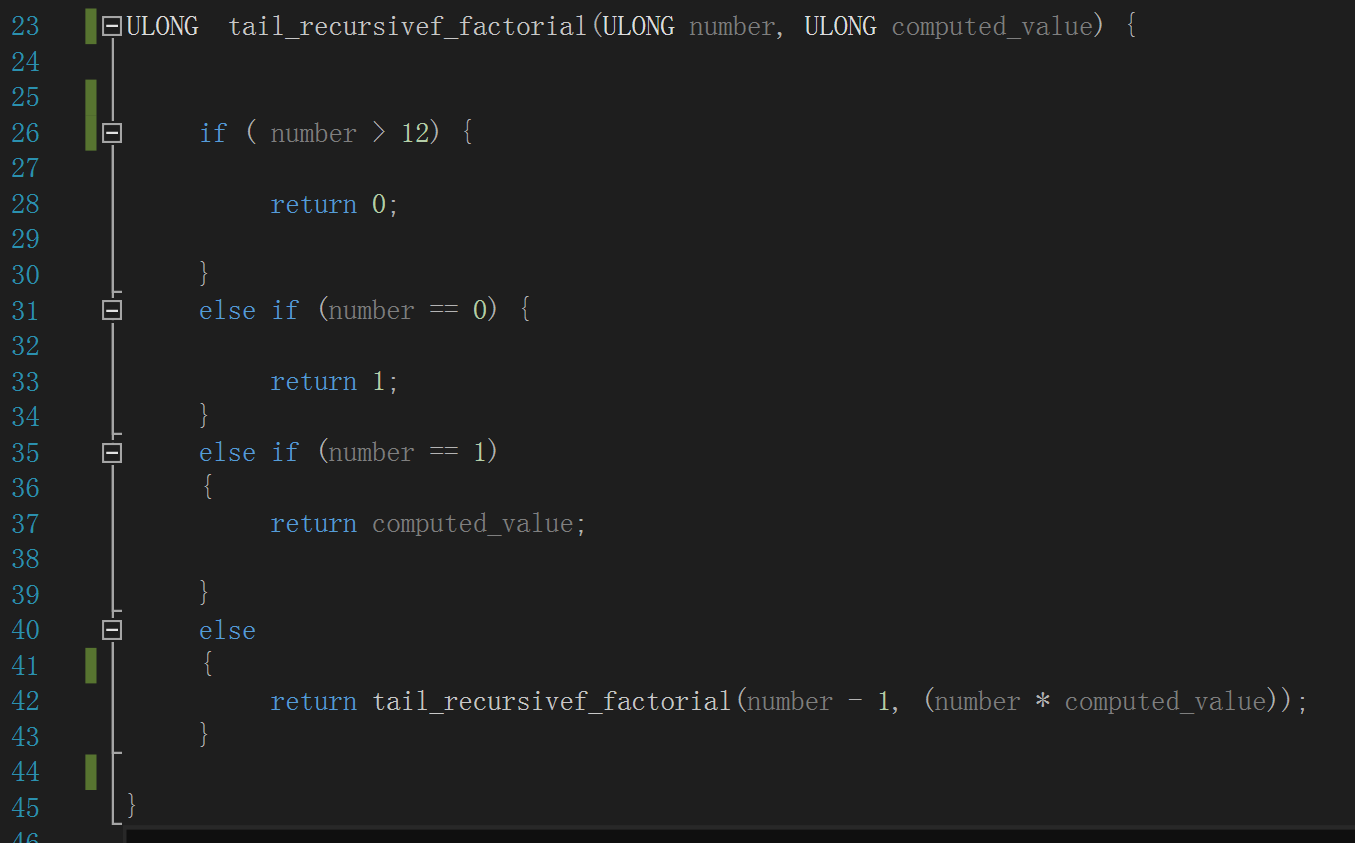
一般的编程范式通常以函数递归调用自身来实现阶乘计算,并在函数内部添加递归的终止条件。
下图是一种叫做“尾递归”的阶乘计算算法,从源码级别来看,它的巧妙之处在于第二个形参“computed_value”可以用来保存
本次递归的计算结果,然后作为下一次的输入。每次第一个参数“number”的值都递减,终止条件就是当它降到 1 时,即返回最新的 computed_value
值。“tail_recursivef_factorial()”开头的判断逻辑确保了我们不会因为计算 13! 或更大数的阶乘导致溢出:
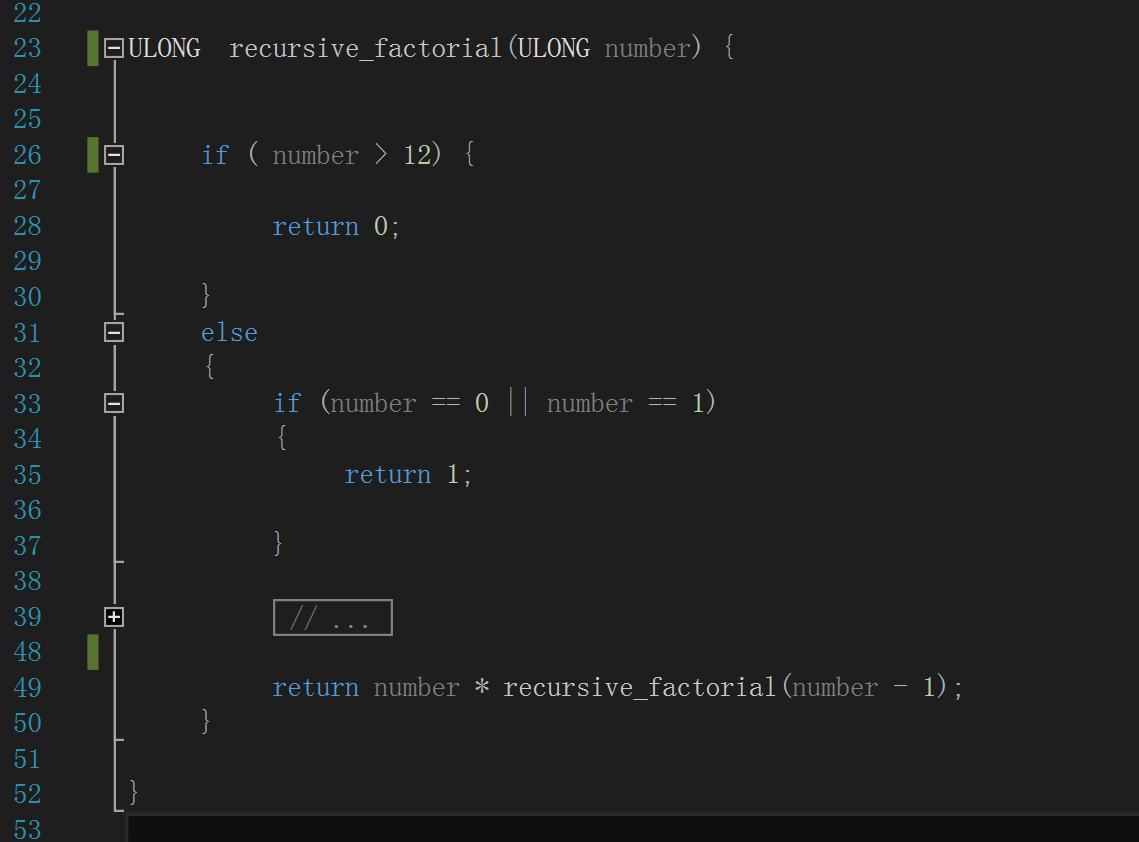
作为对比,下图则是另一种“基本递归”的阶乘计算算法,“recursive_factorial()”只有一个形参,就是要计算阶乘的正整数。
前面的逻辑大致与 tail_recursivef_factorial() 相同,除了最后那条 return 语句,它把对自身的递归调用放进了一个表达式
中,这种做法对性能的影响是致命的,因为不得不等待递归调用终止才能完成整个表达式的求值计算:
————————————————————————————————————————————————————————————————————————————————————
假设我们忽略溢出的情况,或者在 64 位系统上执行这段代码,就可以传入更大的正整数。而从源码上看,recursive_factorial() 的
性能严重依赖于输入参数——试想要计算 100!,它可能需要反复地创建,销毁函数调用栈帧 100 次,才能完成表达式求值并返
回。
反观 tail_recursivef_factorial(),因为它引入了一个额外变量存储每次调用的结果,从形式上而言与 for 循环并无太大区别,
“貌似”编译器可以优化这段代码来生成与 for 循环类似的汇编指令,从而避免函数调用造成的额外 CPU 时钟周期开销(反复的压
栈弹栈都需要访问内存)。
我们的美好愿望是:同样计算 100!,tail_recursivef_factorial() 无需多余的 99 次函数调用栈帧开销,在汇编级别直接用与类似 for
循环的迭代控制结构即可实现相同效果,使得执行时间大幅缩短。
在后面的调试环节你会看到:这个“美好愿望”或许对其它编译器而言能够成立,对 Visual C/C++ 编译器而言则不行——它还不
够智能来进行尾递归优化(或称尾递归“消除”)。
做性能分析就需要计算两者的执行时间,我们使用内核例程“KeQuerySystemTime()”,分别在两个函数各自的调用前后获取一次
当前系统时间,然后相减得出差值,它就是两种阶乘计算算法的运行时间,如下图,注意黄框部分的逻辑,变
量“execution_time_of_factorial_algorithm”存储它们各自的运行时间:
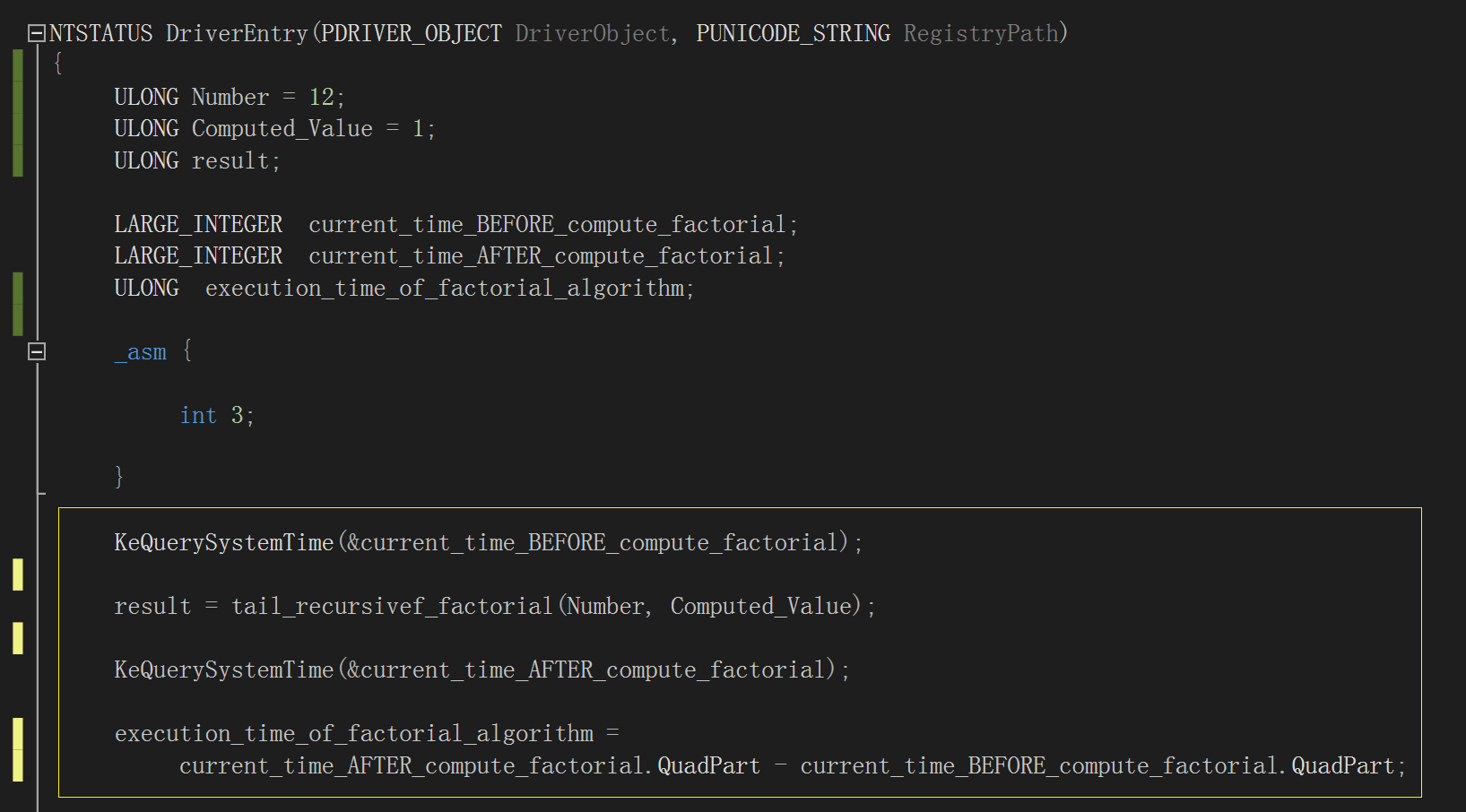
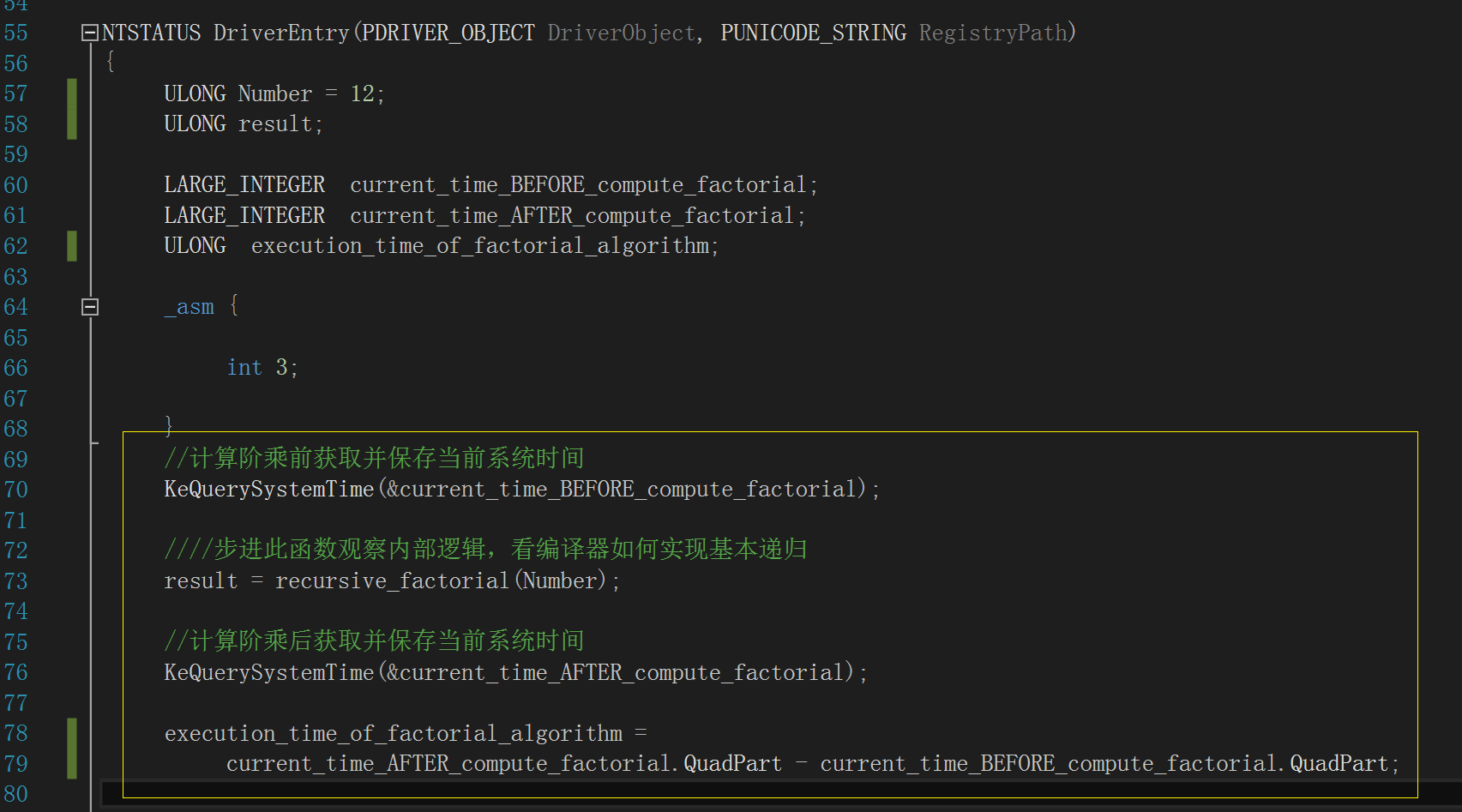
图中以内联汇编添加的软件断点是为了方便观察 KeQuerySystemTime() 如何使用“LARGE_INTEGER”这个结构体:
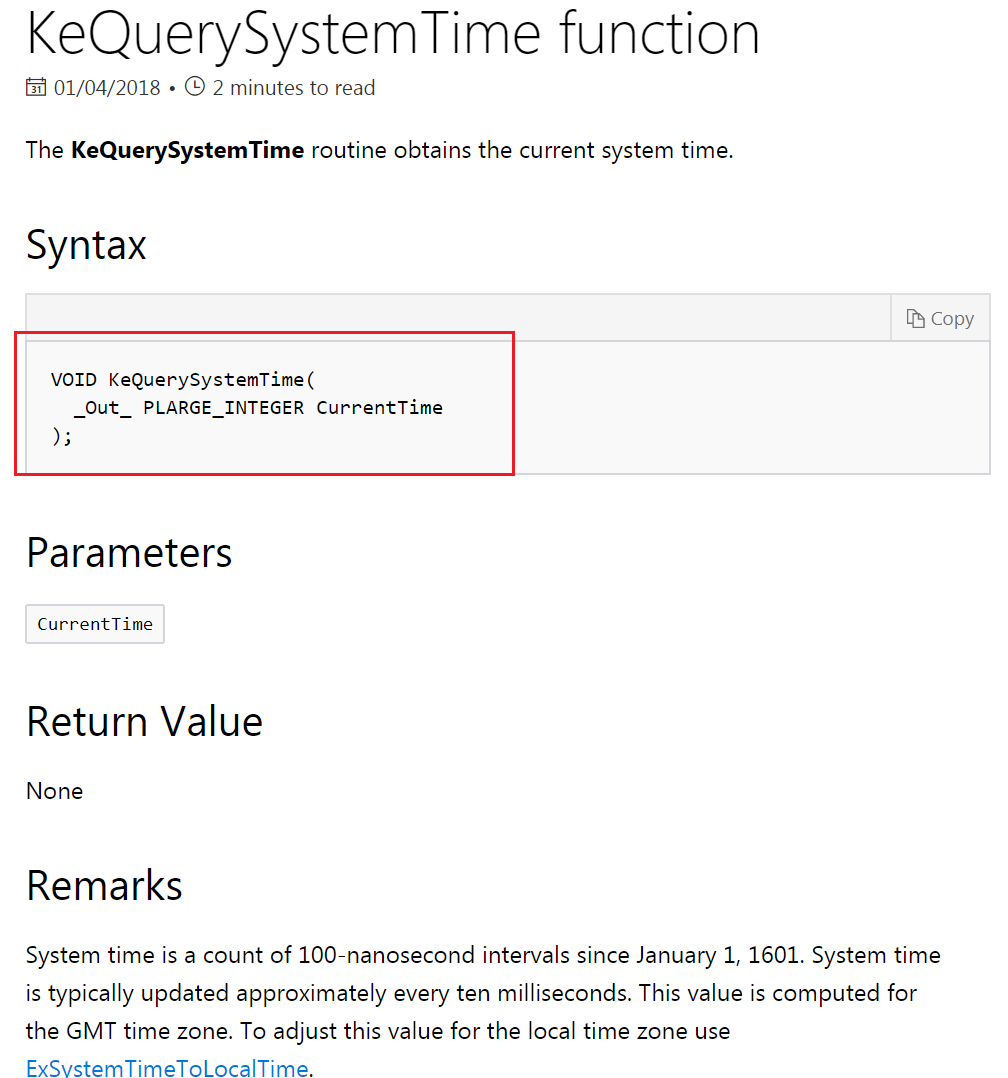
原始文档写得很清楚—— KeQuerySystemTime() 输出的系统时间(由一枚“LARGE_INTEGER”型指针引用)
是从 1601年1月1日开始至当前的“100 纳秒”数量,通常约每 10 毫秒会更新一次系统时间。
KeQuerySystemTime() 的输出值是根据 GMT 时区计算的,使用 ExSystemTimeToLocalTime() 可以把它调整为本地时区的值。
既然 1 毫秒 = 1000 微秒 = 1000000 纳秒,只需把这个值除以 10000 即可得到“毫秒数”,再除以 1000 即可得出以秒为单位
的运行时间。
但是事情没那么简单,你想看看:从 1601年1月1日以来到当前 KeQuerySystemTime() 调用经历了多少个“100 纳秒”,无论这
个数值为何,肯定不是 32 位系统上的 4 字节变量能够容纳得下的,所以要么在 64 位 Windows 上调试这段代码,要么必须使用
LARGE_INTEGER 结构体的 QuadPart 字段,该字段实质上是内存中一个连续的 8 字节区域:

以 32 位系统而言,ULONG 型变量最多支持 4294967295 个“100 纳秒”,亦即 429 秒;换言之,阶乘算法运行超过 7 分钟,
就无法用 ULONG 变量(execution_time_of_factorial_algorithm)存储执行时间(该值已溢出所以不正确)。
👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽
这不是问题,我们的测试代码载体是内核态驱动程序,没有内核-用户模式的切换开销,加上现代高性能微处理器每秒都能够执行
上千万条指令,所以上述两种算法再怎么低效,执行时间应该都在数十毫秒级别,除非我们计算 1000!乃至 10000!——在后面
你会看到,从理论上而言(忽略 64 位数能够表示的上限值,即便连 64 位数也无法存放 21! 和更大的正整数阶乘值),
recursive_factorial() 求值 10000!所需的运行时间可能缓慢到秒级别,但事实上,每个线程的内核栈
空间是很狭小的,以至于当我们计算 255! 时就会因为向内核栈上压入过多的参数而越界,访问到了无效的内存地址,导致页错
误,而此后向同一个无效地址压入异常现场并转移控制到错误处理程序之前,会进一步升级成“double fault”,因为连续两次访
存操作都是无效的,最终致使系统崩溃蓝屏(或者断入调试器)。
总而言之,两个从 1601年1月1日以来的历时是 64 位数,相减后只有低 32 位——多数情况下,高 32 位都是零。这样我们就能够
比较两种算法的性能优劣了。
👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽
正如你可能意识到的那样:当要计算阶乘的数太小时,两者间的性能差距不明显,所以我把上面计算 12! 的逻辑改成了计算 229!
,同时又不会导致内核栈溢出,调试过程如下,首先来看看 tail_recursivef_factorial() 的反汇编代码,它说明了微软 Visual C/C++ 编译器是如何实现尾递归
算法对应的指令序列:
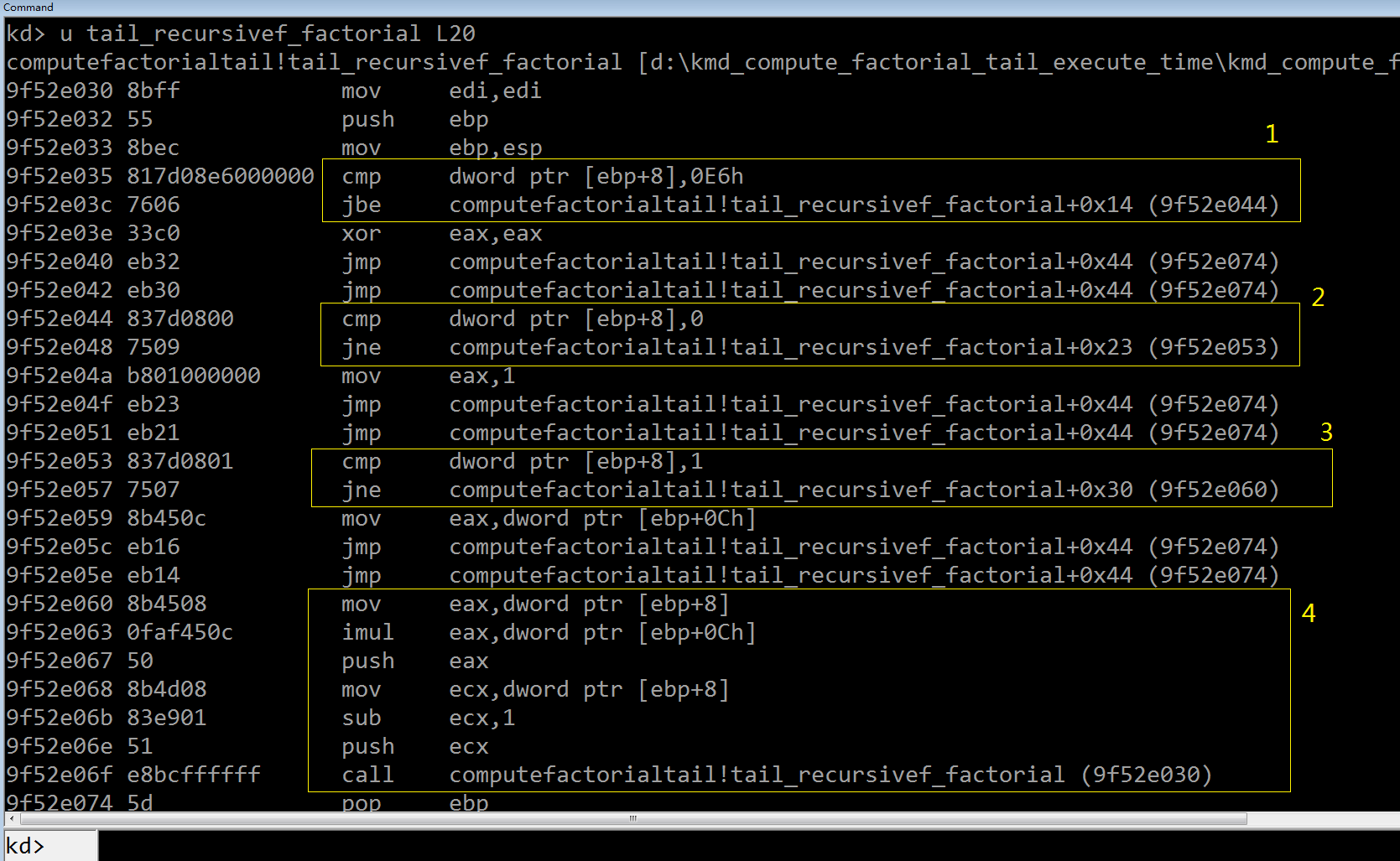
上图编号 1 黄框中的汇编代码把 ebp+8 处的内核内存与立即数 0xe6(230)比较(cmp),如果低于等于 230 就跳转到 9f52e044
地址处执行(jbe),反之则清零 eax 寄存器后跳转到 9f52e074 地址处,在那里的“pop ebp”和“ret 8”(图中没有绘出)指令序列
导致 tail_recursivef_factorial() 返回——因此我们推断 ebp+8 就是第一个参数 number,并对应于源码中检查它是否大于 230 的逻辑;
类似地,编号 2 黄框中的汇编代码对应源码中检查 number 是否等于 0 的逻辑——如果不等于 0 则跳转(jne)到 9f52e053
地址处(编号 3 黄框),在该处继续检查 number 是否等于 1 ——如果 number 已经递减至 1,表明满足递归退出条件,把
ebp + c 处的栈内存值(亦即 第二个参数 computed_value )拷贝到 eax 寄存器内作为返回值,跳转到 9f52e074 地址处返回;
否则,把 number 移动到 eax 中并与 computed_value 执行有符号乘法(imul),然后把存储在 eax 中的计算结果压入栈上,
同时 number 递减 1 后的值移动到 ecx 中(通常被当成循环计数器),为下一次的 tail_recursivef_factorial() 调用做好准备。
从上图你可以发现两件有趣的事情:
其一,尽管我在源码中显示指定了两个参数的类型,以及返回值均为“ULONG”(无符号),但 Visual C/C++ 编译器依旧无动于衷,
坚持在汇编级别使用有符号数乘法指令“imul”,而非无符号的版本“mul”;而根据 intel 手册,“imul”指令的双操作数模式中,
如果计算结果超过了目的操作数(本例中是 eax)的大小,则从乘积的最高位开始截断——若被丢弃的不是符号位,该指令会设置
EFLAG 寄存器中的溢出和进位标志—— 32 位有符号数的上限值为 2,147,483,647(7FFF FFFF),若超出就会下溢,结合上面的
反汇编代码推算:当第四次递归调用时(229 * 228 * 227 * 226,亦即当 ecx 值为 0xe2 时)就会发生下溢,从而设置相关标志位,我们在后面调试会验证;
其二,尽管源码中的尾递归调用已经刻意书写成能够被编译器利用等价的迭代控制结构替换,从而节约反复的函数调用开销,但
Visual C/C++ 却笨得没有意识到这一点,还是傻傻地照本宣科来翻译,这导致我们的 tail_recursivef_factorial() 实际执行
性能不如理论上那样比基本递归的 recursive_factorial() 优越!
👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽
了解 tail_recursivef_factorial() 的机器机实现后,接下来就是断点设置的艺术了——当前触发的断点是我在源码中指定的
,位于 KeQuerySystemTime() 调用前,目的是检查 LARGE_INTEGER 结构体是怎样被使用的;
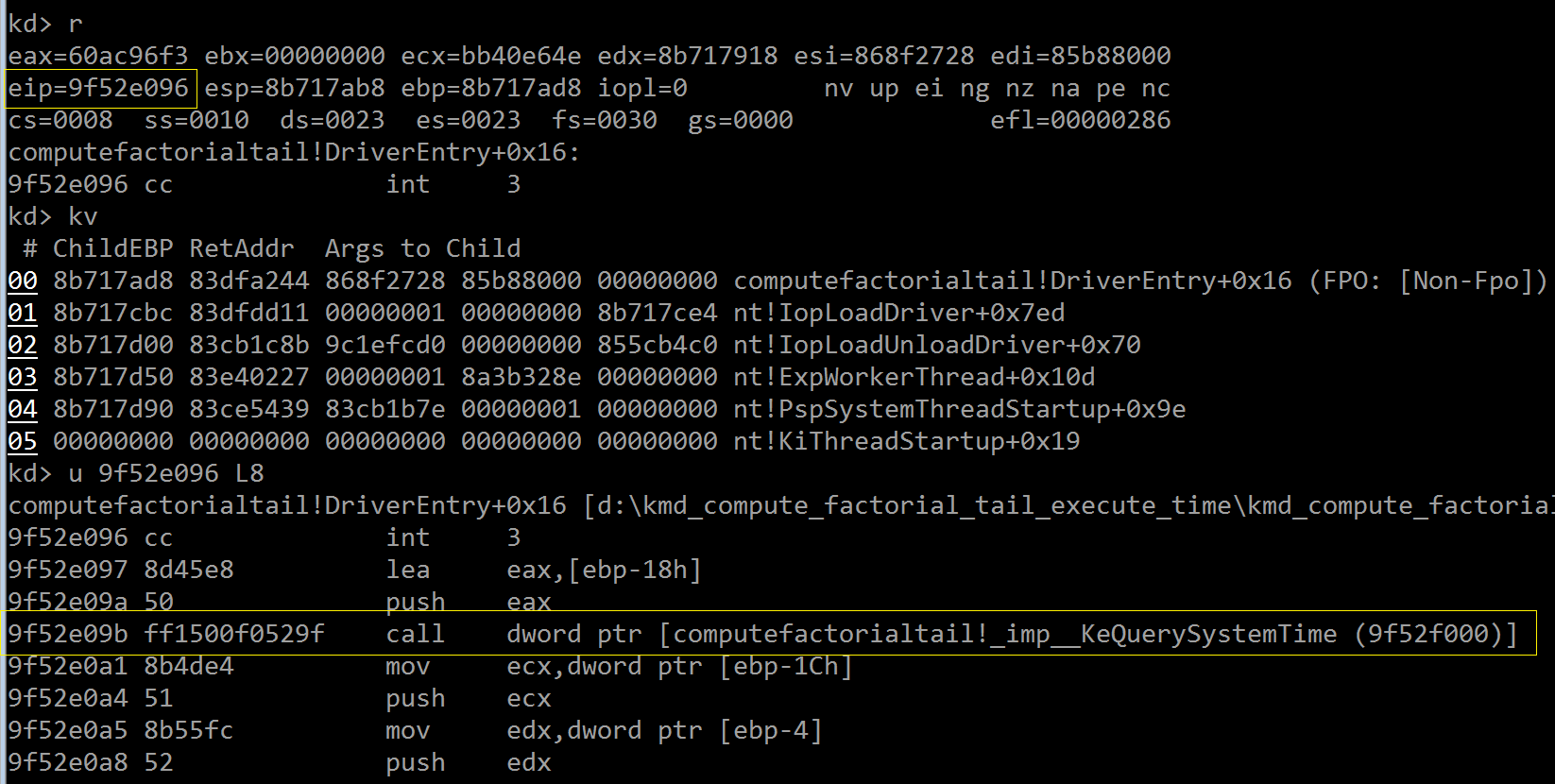
上图中 ebp-18 处的内核栈内容是啥?让我们观察 DriverEntry() 的局部变量统计信息:
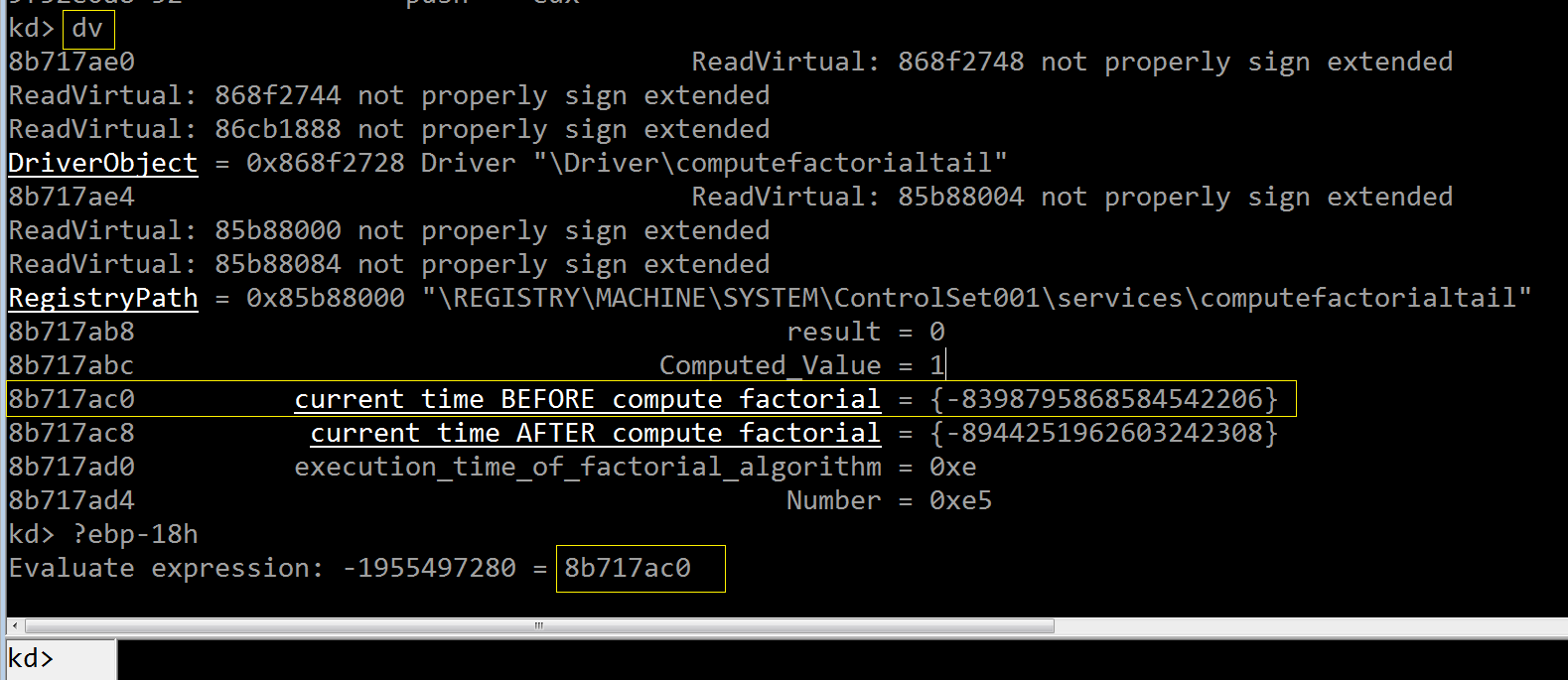
原来 ebp-18 处就是一个 LARGE_INTEGER 实例—— current_time_BEFORE_compute_factorial,而指令“lea eax,[ebp-18h]”
把它的地址移动到 eax 中,然后压入栈上,这符合 KeQuerySystemTime() 的形参类型要求—— C 的取地址操作符“&”在汇编级别用“lea”指令实
现,形参“PLARGE_INTEGER”需要持有一个 LARGE_INTEGER 实例的地址,单步跟踪(F8)验证:
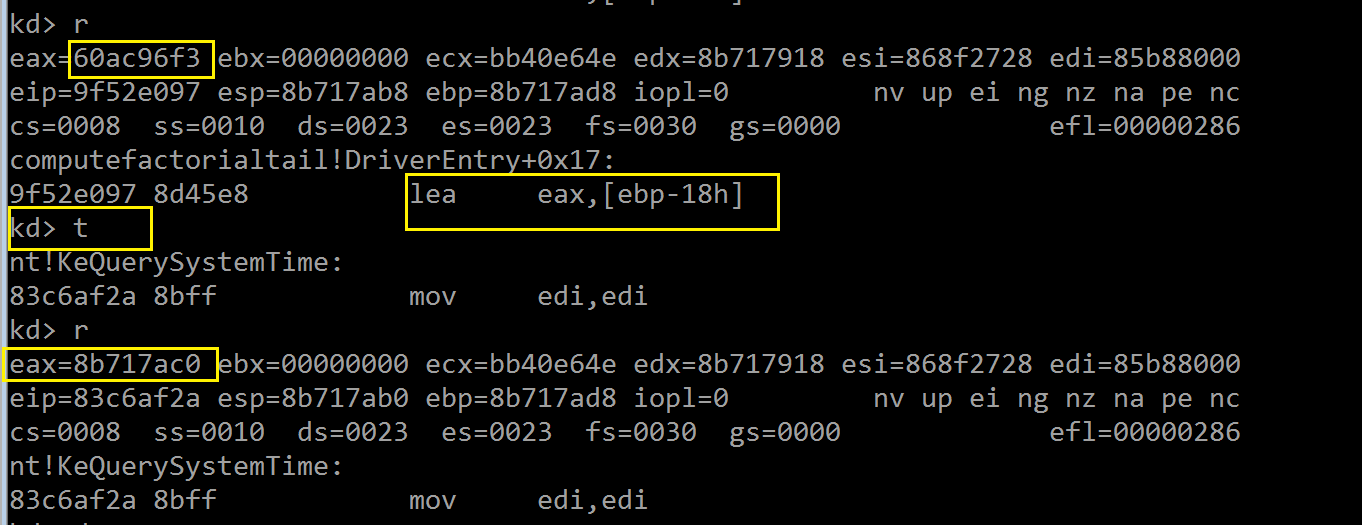
此刻我们进入了系统例程 KeQuerySystemTime() 内部,我们想知道它当它返回后,变量 current_time_BEFORE_compute_factorial
的内部组织形式;同时还要在后续的 tail_recursivef_factorial() 调用内部设置几个断点,方便研究“imul”指令的行为:
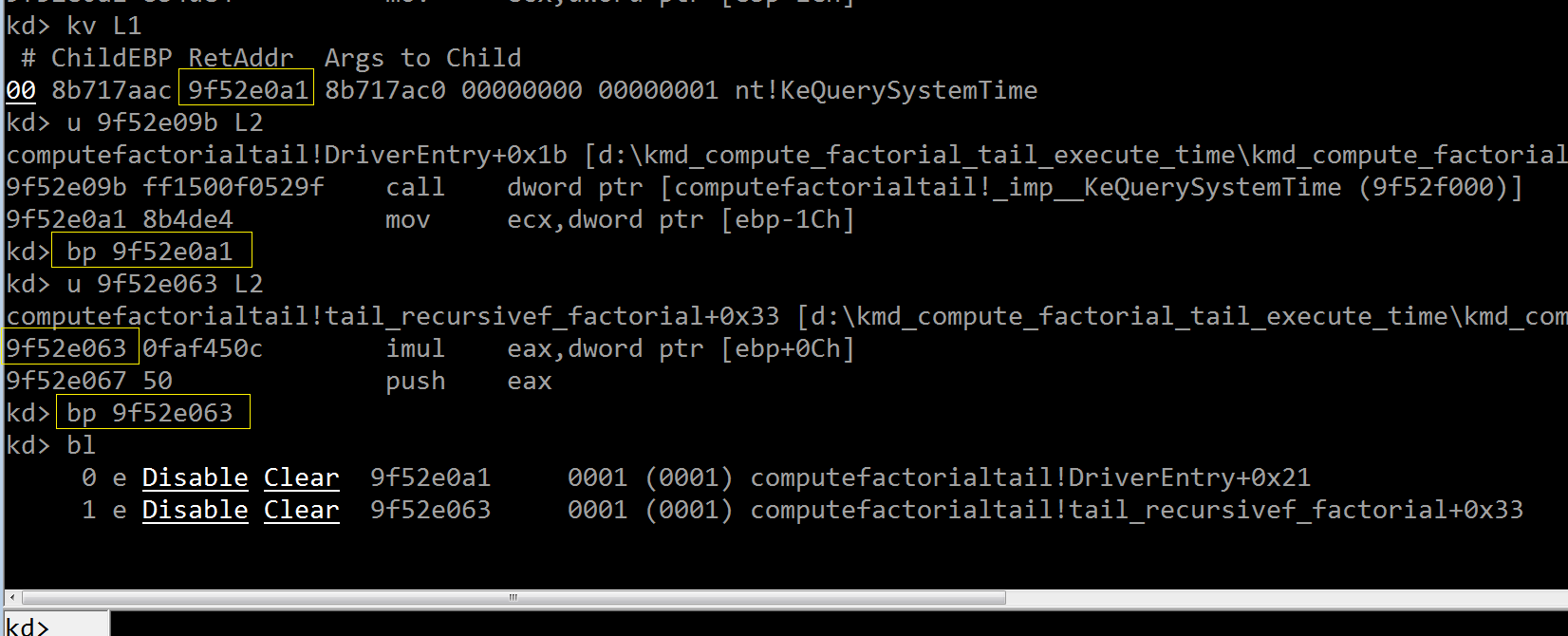
上图分别在 KeQuerySystemTime() 返回后(返回地址 9f52e0a1 那里),以及 tail_recursivef_factorial() 内部的“imul”指令地址处(9f52e063
处),设置了两个断点,我们按下“g”键继续执行以触发第一个断点,然后观察存储了当前系统时间的 current_time_BEFORE_compute_factorial 结
构内部:
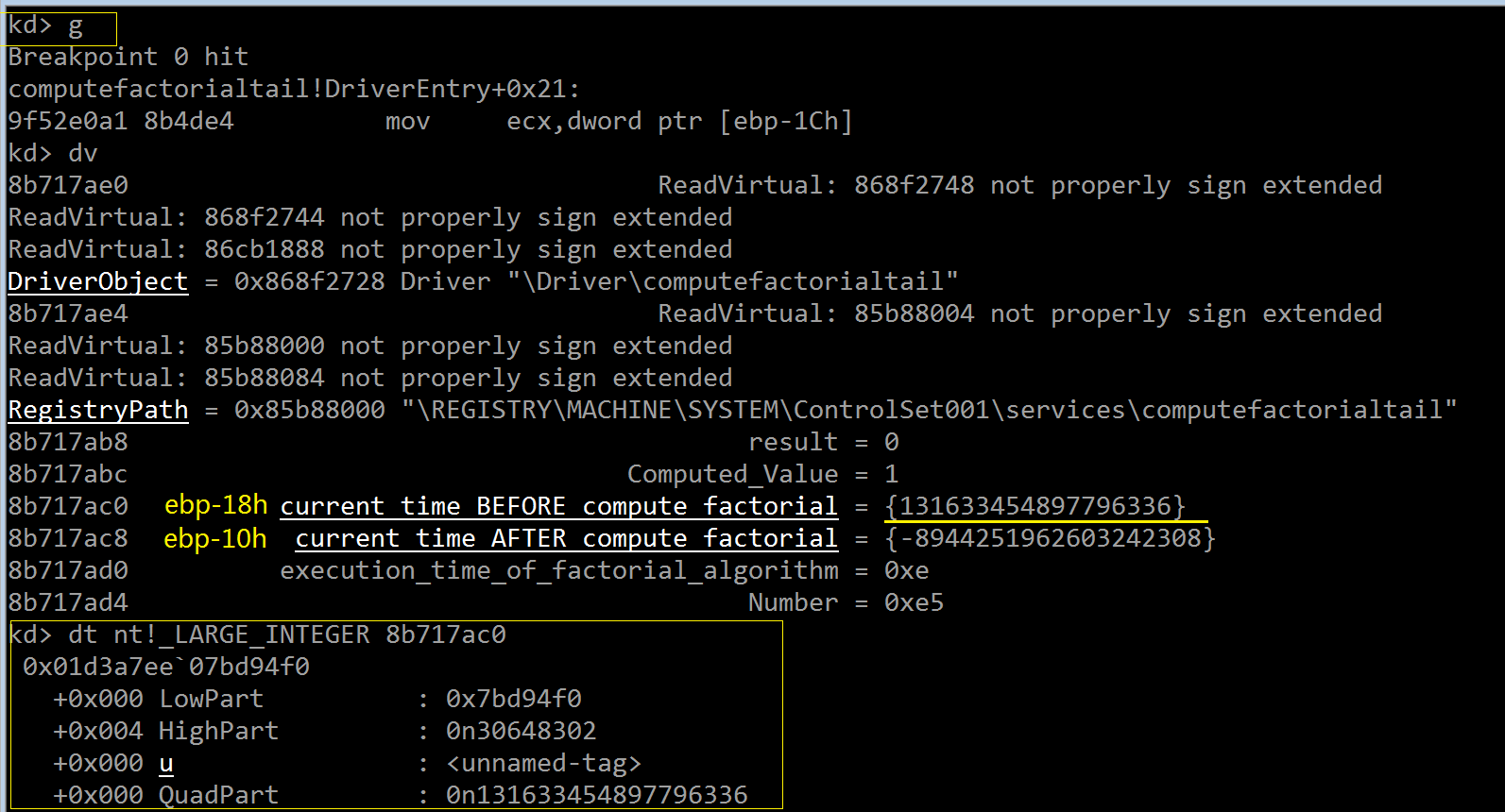
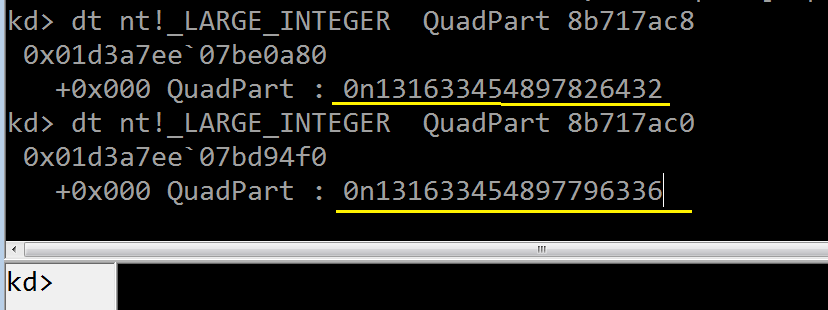
可以看到 current_time_BEFORE_compute_factorial 的 QuadPart 字段 10 进制值为 131633454897796336,它就是自从
1601年1月1日以来经过的“100”纳秒数量——让我们转换成年:131633454897796336 / (10000 * 1000 * 60 * 60 * 24 * 365) = 417
最终结果等于 2018 - 1601 = 417 年。至此我们成功通过 KeQuerySystemTime() 获取到当前系统时间。
此外,ebp-10 处的内核栈存储另一个 LARGE_INTEGER 实例:current_time_AFTER_compute_factorial,两者占用的空间差值
(0x8 字节)就是 LARGE_INTEGER 结构体的大小。
先禁用掉 9f52e063 的断点,然后在 9f52e0bb 处,也就是第二次 KeQuerySystemTime() 调用的返回地址设置第三个断点,
这样可以准确地计算出尾递归阶乘算法的执行时间,如下图所示,把这两个 LARGE_INTEGER 的 QuadPart 字段值相减,换算成毫秒,
执行时间为:(131633454897826432 - 131633454897796336) / 10000 = 3 毫秒;
229! 值为零是因为发生了溢出(前面讲过,32 位系统上计算 13! 就会溢出)
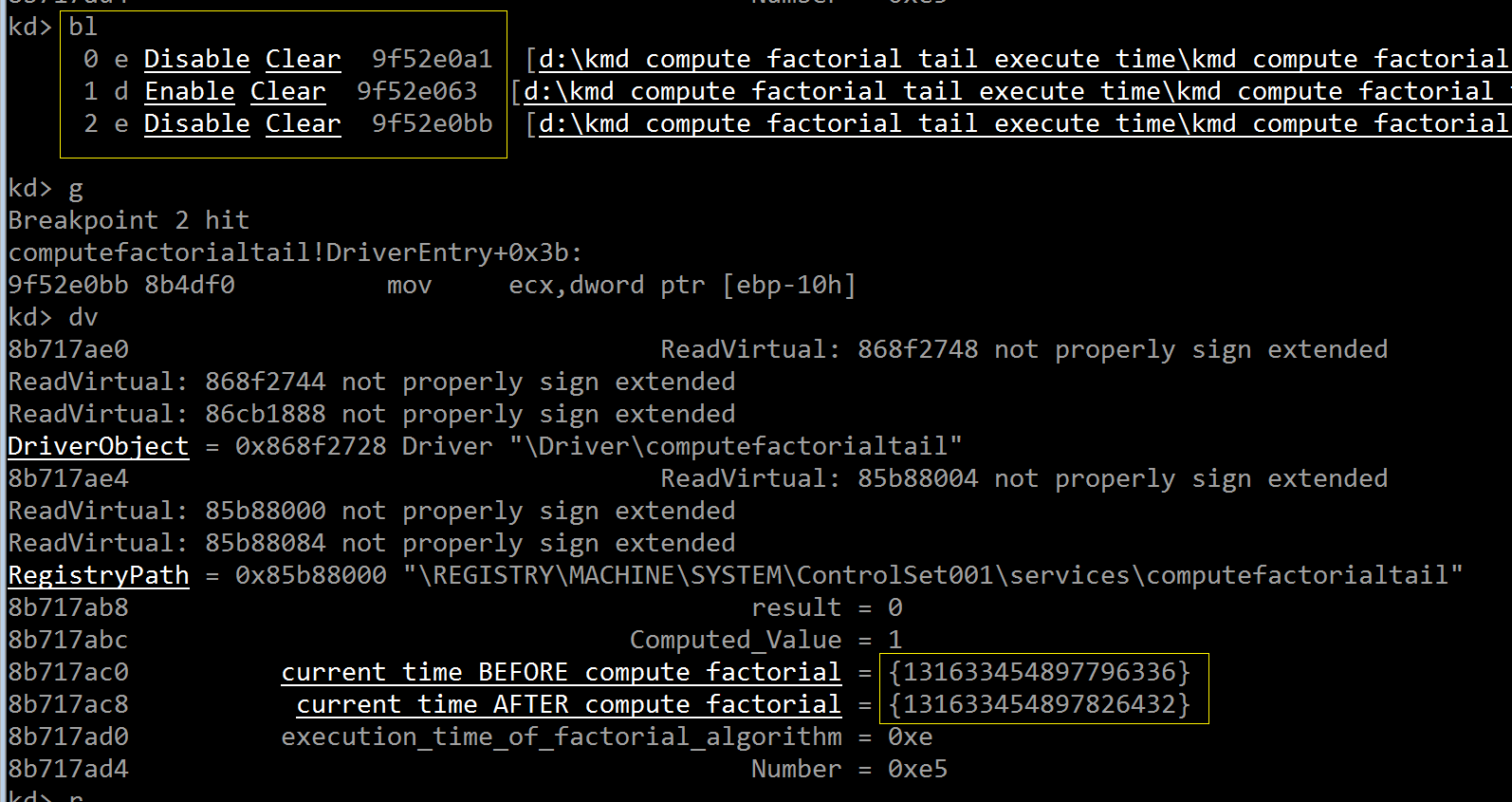
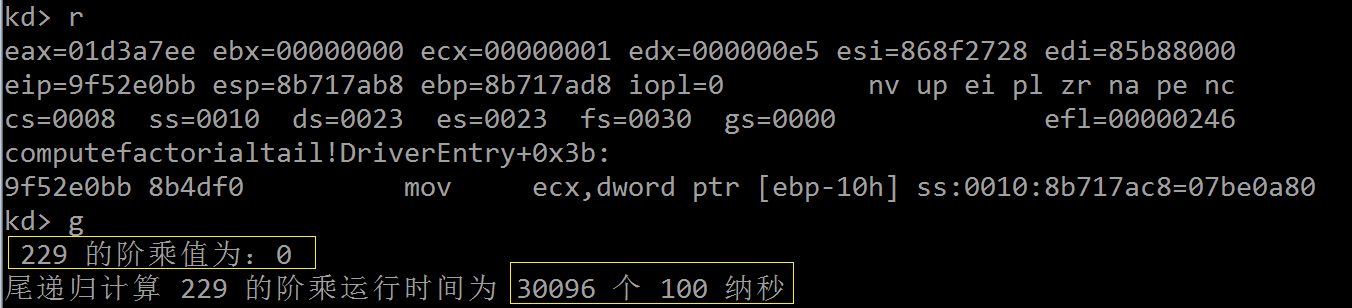
经过多次反复调试,证明 tail_recursivef_factorial() 计算 229! 时的运行时间在 2—4 毫秒之间,看来即便没有做编译器优化,
CPU 的高速运算能力也让两百多次的函数调用在毫秒级别就能够完成。
👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽👽
这一次让我们在 tail_recursivef_factorial() 内部的“imul”指令地址处设置断点,由于递归调用的关系,这个断点每次都会
被触发,直至满足终止条件;在经过四次调用后的概况如下:

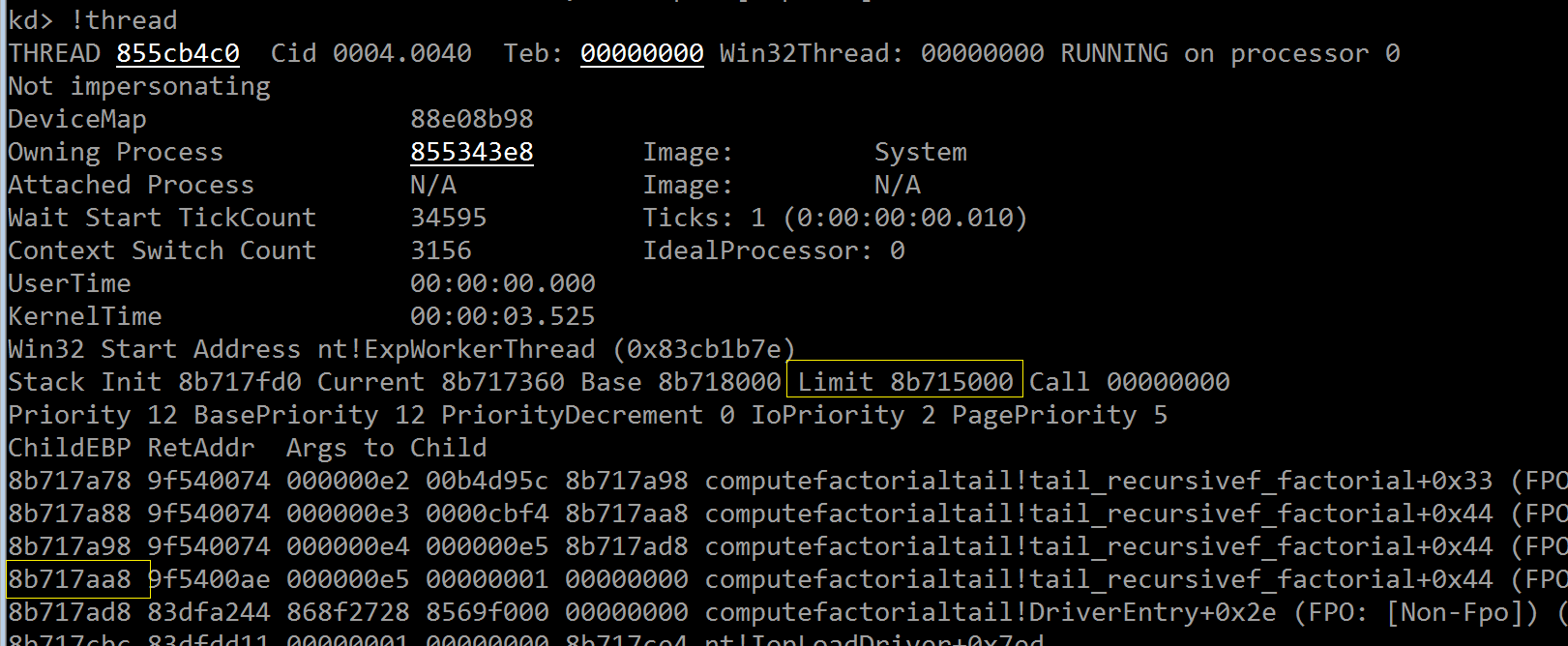
如上图所示,在第四次执行“imul”指令前,内核栈上已经有 4 次 tail_recursivef_factorial() 的栈帧记录;
当前的 Computed_Value 值为 11,852,124(0xb4d95c),也就是 229 * 228 * 227 ——前三次“imul”指令的执行结果,假设
本次再执行“imul”指令把 Computed_Value 与 eax 的当前值(0xe2,亦即 226)相乘,就会发生溢出。
“elf = 00000206”是执行前的 EFLAG 寄存器内容,解码后的标志位如下图,表明尚未溢出:
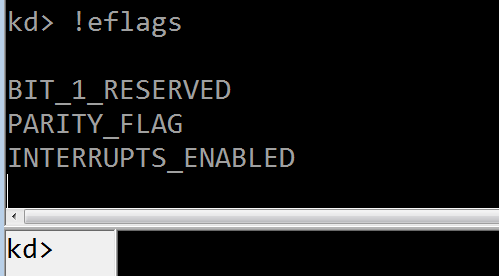
另一个关键信息是红框处的 ebp 值,它暗示每次递归调用都会消耗 16 字节的内核栈空间——这 16 字节是怎么来的呢?
再次回顾 tail_recursivef_factorial() 的反汇编代码,第一条使用栈上 4 字节空间的指令是“push ebp”、第二条是“push eax”,第三条是“push
ecx”。。。而在“call computefactorialtail!tail_recursivef_factorial”执行前,会隐式地压入 4 字节的返回地址,这是“call”指令内建的功能,不会作为
反汇编输出:

查看当前执行线程的内核栈,可知其下限在 8b715000 地址处;而首次的 tail_recursivef_factorial() 调用是从 8b717aa8 地址处开始消耗栈空间的,换言
之:(8b717aa8 - 8b715000) / 0x10 = 0n682,仅能够供 682 次递归调用,第 683 次调用就会越界,访问到尚未分配的物理内存区域,引发一次页错误,后
面我修改源码计算 683! 并在调试时就会出现这种情况,它会升级为“double fault”:
现在单步执行,然后检查“imul”指令的效果:

上图中的 EFLAG 寄存器内容(0xa83)经解码后显示符号位和溢出位都被设置了,表明乘法运算发生了下溢,观察 eax 中
存储的计算结果“9fa7e338”,它的 10 进制值为“-1,616,387,272”,所以后续的计算结果都是错误的。
——————————————————————————————————————————————————————————————————————————————————————
小结:本篇介绍通过获取当前系统时间来测量程序或一段代码块执行性能的方法,揭示了神秘的“LARGE_INTEGER”工作机制,并且比较源码级和机
器指令级算法实现的区别——其差异性完全由编译器主导;接着演示 32 位有符号数的溢出。。。所有这些都是在内核态下进行的,因此可谓比一般的用
户态调试更“底层”。限于篇幅,下一篇将比较另一种阶乘算法“recursive_factorial()”的机器级实现、执行性能,然后通过递归调用访问无效的内核
栈区域触发“double fault”并进行故障排查!
————————————————————————————————————————————————————————————————————————————————————————
posted on 2018-02-18 17:04 f1yin9_0x5hark 阅读(1005) 评论(1) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号